赋予视频生成「视觉思维链」:VChain显式建模时空规划与状态演变
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?在具身智能、影视制作以及物理仿真等应用场景中,要求模型不仅要生成 “平滑的像素”,更要实现 “逻辑连贯的演化”。这种对物理规律与因果关系的建模能力,是当前基于大数据驱动的端到端生成模型面临的长期挑战。那么,我们能否将多模态大模型(MLLM)的推理能力,作为一种 “外脑” 注入到
科技3 阅读
共找到 23 篇相关文章
当视频生成模型在视觉保真度上不断突破时,一个核心瓶颈正变得愈发清晰:模型是否真正理解了真实世界?能否推理出合理的演变过程?在具身智能、影视制作以及物理仿真等应用场景中,要求模型不仅要生成 “平滑的像素”,更要实现 “逻辑连贯的演化”。这种对物理规律与因果关系的建模能力,是当前基于大数据驱动的端到端生成模型面临的长期挑战。那么,我们能否将多模态大模型(MLLM)的推理能力,作为一种 “外脑” 注入到

IT之家 5 月 13 日消息,小米技术今日正式发布并开源 Xiaomi OneVL 一步式潜空间语言视觉推理框架。官方表示,该模型在业内率先实现 VLA、世界模型、潜空间推理等多个技术路线的统一,在具备 XLA 模型强悍推理能力的基础上,大幅提升了推理的速度和精度,是行业内具备开创性的方案,在精度上超越显式 CoT、在速度上对齐“仅答案”预测的潜空间 CoT 方案。过去,VLA 和世界模型是自动

GPT-5级推理能力塞进语音模型,OpenAI把同传翻译成本砍穿地板价 听雨 2026-05-08 12:35:32 量子位 Op

在大模型时代,许多专业人士或许都遇到过类似的问题:当尝试将 DeepSeek-R1 和 OpenAI-o1 这样的卓越推理能力移植到小规模语言模型(SLMs)上时,实际效果往往不尽如人意。尽管现有的强化学习方法 GRPO 对于 7B+ 参数量的大模型来说非常有效,但一旦应用于更小型的模型中,比如 1.7B 或者参数量更少的情况下,性能提升就显得十分有限。针对小规模语言模型在强化学习中的推理难题,香

作者|樊雅婷提供的电子邮箱地址似乎不完整或有误,请确认后重试。GPT Image 2 的出现标志着图像生成技术的一个重大转折点,它不仅仅是一个优化后的扩散模型或是更高效的架构迭代,而是将语义理解和推理能力直接引入了图像生成过程中的关键环节。这样的革新不仅解决了图像质量与一致性的问题,还大大提升了用户交互体验。根据最近的观察和分析,GPT Image 2 的成功在很大程度上归功于其独特的混合架构——
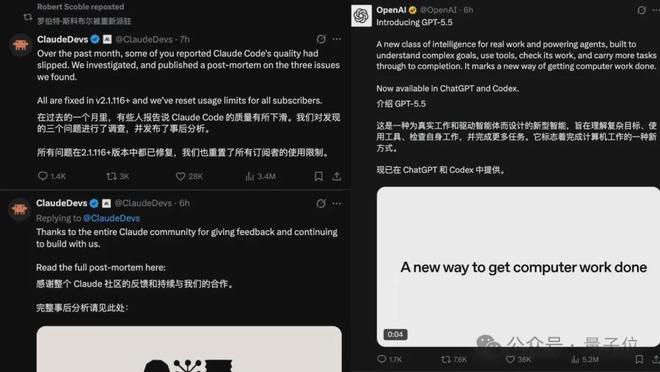
最近,有关人工智能模型Claude的一系列问题引起了广泛关注。在GPT-5.5发布前后,Claude团队承认了他们的问题:用户所使用的额度已被重置。经过一段时间的否认后,该团队终于在官方博客上公布了三个关键性技术故障。他们的模型性能被故意降低至中等水平,而非原先承诺的高度推理能力。此外,系统中的缓存问题导致每次对话结束后都会清除之前的思考记录。还有一个限制每条回复不超过100个词的提示语也影响了输

最近的一则新闻报道了一家初创公司在短短几年内达到了百亿估值并获得了超过十亿的融资,引起了广泛的关注。 十三 2026-04-23 22:28:57 量子位

“以图思量”的方法,即通过工具调用或代码生成等方式,在思考过程中引入辅助图像(如裁剪、标定、作辅助线等),已成为增强多模态大语言模型视觉推理能力的重要手段。这类方案虽然效果显著,但也带来了对外部工具的依赖性,导致了几个局限。训练和推断复杂度高:在训练过程中,模型需要额外学习各种工具及函数接口的使用方式,增加了训练难度;同时,在多轮交互式推理中也延长了推断延迟时间。可操作类型受限:受制于可用工具种类

深度学习模型DeepSeek R1 的问世,引发了人们对大规模预训练是否是提升模型推理能力唯一途径的新思考。事实上,通过后处理技术如强化学习、过程奖励和闭环反馈机制,人们得以以极低的成本解锁原本需大量算力才能触及的高级功能。这一现象正逐渐在自动驾驶领域重现。自动驾驶系统已经完成了一系列大规模的数据预训练,但仍存在一个重大障碍:它们尚无法完全理解为何特定的行为模式是最佳选择。真正的进步需要依赖闭环反

新智元报道【新智元导读】Opus 4.7发布48小时,口碑两极撕裂。官方榜单并列全球第一,逻辑推理公开测试却从94.7%暴跌到41.0%。token消耗涨了35%,旧接口直接报错,用户集体控诉「更贵、更蠢、更爱顶嘴」。Anthropic到底升级了什么,又搞砸了什么?「4.6根本没法用,4.7的消耗速度像核反应堆一样。」Opus 4.7发布后,一位Reddit用户在Anthropic官方帖子下的留言

ReCALL团队在量子位平台上发布了一篇文章,探讨了生成式模型的应用效果。当多模态大模型具备强大的视觉和逻辑推理能力时,人们期待它们能轻松解决图像检索任务,尤其是组合图像检索问题。然而实际应用中却发现,将这些大型生成式模型改造为判别式的检索工具后,其性能反而显著下降。这种从生成转向判断的转换过程中产生了严重的功能退化现象。最近,紫东太初团队与新加坡国立大学的研究人员合作解决了这一行业难题,并提出了

4月3日,小米创始人兼董事长雷军在微博上宣布了一个重要进展:小米的大模型MiMo的调用量已经突破了1万亿词元,这标志着公司在大模型技术领域取得了一项重大成就。前一天即3月31日,雷军还披露了MiMo-V2-Pro大模型在权威评测平台Text Arena上的最新成绩。这款模型凭借其卓越的复杂推理能力、长指令遵循以及多轮对话功能,在Model Rank维度上成功跻身全球前五。此外,在评估实验室综合研发

摘要:尽管“Gemini叫Uber”和“千问直接打车”的功能看似相似,但实际上两者有着本质的区别。前者仅限于让AI操控应用程序界面完成任务,而后者则是真正赋予了AI深层次的推理能力,使其能够深入参与到实际的服务履约过程中。凤凰网科技 出品作者|Dale在中国的人工智能领域中,有两家公司始终保持着独立的发展路线,并未被行业热潮所左右:DeepSeek和千问。前者专注于AGI信念的研究与技术革新;后者

MiniMax仅仅一个月前发布了M2.5版本,现在M2.7版本已经推出。这期间虽然包含春节假期。MiniMax在官方声明中指出,M2.7版本代表了首次深度参与模型迭代的过程。在过去几年里,“AI自我进化”已经从一种略带科幻色彩的概念,转变为业界普遍接受的发展方向。前谷歌首席执行官埃里克·施密特曾总结,目前硅谷达成了一项共识:人工智能的推理能力和记忆系统的发展,将彻底改变人类的工作方式。最终,这种系

在腾讯最近发布的财务报告后的媒体见面会上,公司透露,腾讯的混元系列最新版本HY 3.0正处于内部测试阶段,预计将于2026年4月对外发布。该版本是混元系列的重大更新,相比前一版本HY 2.0,核心性能有了显著提升。腾讯表示,HY 3.0模型在多个关键领域进行了优化,包括推理能力和智能代理(Agent)能力,整体智能水平有了显著提高。为了加快模型的迭代速度,自2025年下半年以来,腾讯混元团队进行

3月10日,在上海举行的发布会上,美的集团宣布了其2026年全屋智能战略,并推出了“三个一”策略和自进化家居智能体MevoX,展示了向人工智能转型的决心。美的集团副总裁赵磊在会上介绍了公司的核心战略——以一个家庭网络、一个AI大脑以及一个开放平台为基础。该战略的核心是具有高级推理能力与记忆功能的MevoX智能体,并基于此构建了MIA 1.0系统,旨在实现全屋设备的一体化管理。目前,美的已经完成了超

在多模态内容的理解和生成领域,统一的多模型已经显示出显著的效果,但这些成果主要集中在图像处理上。近日,滑铁卢大学与快手可灵团队共同研发出了一种名为 UniVideo 的创新性系统。该系统能够在单一框架下执行视频理解、创建及编辑任务,并且基于一个多模态生成模型构建而成。UniVideo 采用双通道结构设计,将大规模多模态语言模型(MLLM)的指令理解和推理能力与多模态扩散 Transformer(M

你是否也在对这个问题感到疑惑? AI大模型之间的实际差距,真的就像各种榜单上显示的那样明显吗? 确实,这些排名看起来一目了然。 参数和得分都很清晰,但总觉得用特定题目和维度来评估AI的能力,似乎有些限制其潜力。 如果将它们置于复杂互动环境中,这些模型的逻辑推理能力是否还能像在标准测试中那样拉开差距呢? 我相信不止我一个人有这种疑问。 目前已经有新的方法开始应用了,并且引起了极大的关注: 将全

去年7月举行的国际数学奥林匹克竞赛上,两家人工智能公司因争夺金牌成绩而引发了广泛关注。当时OpenAI和谷歌都宣称取得了金牌的成绩,但OpenAI由于提前违反官方规则宣布结果而受到了批评;谷歌DeepMind的Gemini进阶模型则是首个被奥赛组委会正式认定为金牌的人工智能系统。竞赛与真正的数学研究之间仍存在明显的界限。自那之后,AI的发展迅速加快,其解决数学问题的能力不再仅仅依赖于推理能力。现在

近日,谷歌正式发布了其最新的图片生成和编辑模型Nano Banana 2(Gemini 3.1 Flash Image),该模型已在谷歌的多种产品中上线。Nano Banana 2在功能与速度上进行了全面提升,在世界知识、图像质量、推理能力和主体一致性等方面均有所突破。同时,它在基准测试中的表现优于GPT-Image 1.5、Seedream 5.0 Lite和Grok Imagine Image