最近,有关人工智能模型Claude的一系列问题引起了广泛关注。
在GPT-5.5发布前后,Claude团队承认了他们的问题:用户所使用的额度已被重置。
经过一段时间的否认后,该团队终于在官方博客上公布了三个关键性技术故障。
他们的模型性能被故意降低至中等水平,而非原先承诺的高度推理能力。
此外,系统中的缓存问题导致每次对话结束后都会清除之前的思考记录。
- 还有一个限制每条回复不超过100个词的提示语也影响了输出质量。
- 三个故障叠加在一起,使Claude用户的体验大幅下降。
- 尽管其他竞争对手的压力是一个因素,但这次问题的主要原因仍然是技术失误。
新版本发布得太巧,让人怀疑是否与GPT-5.5的推出有关联?
然而,事实证明,这三个错误并非首次出现。去年八月,类似的事件也曾发生过一次。
那次Anthropic团队在他们的模型Opus 4.0和4.1上遇到了类似问题,并且声明从未有意降低其性能质量。
最近这次新的报告标题为“近期三个主要问题的回顾”,意指当前的问题是最近才被发现并解决的。
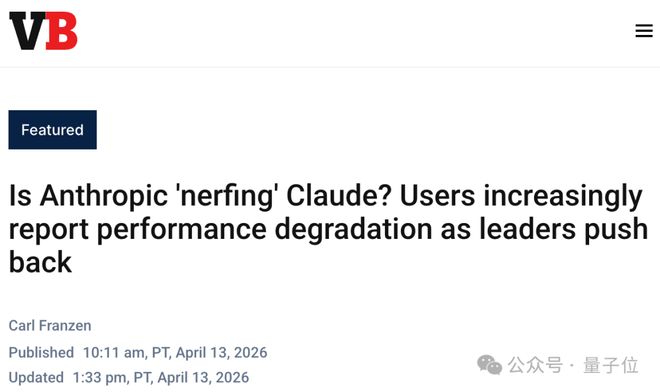
社区对此持续关注,直到十多天前,AMD AI团队发布了一份详细的审计报告,证实了从二月份开始模型推理深度急剧下降的事实。
这份报告分析了超过6800个会话文件和17000多个思考片段,揭示了Claude在处理任务时表现出明显的计算能力退步现象。
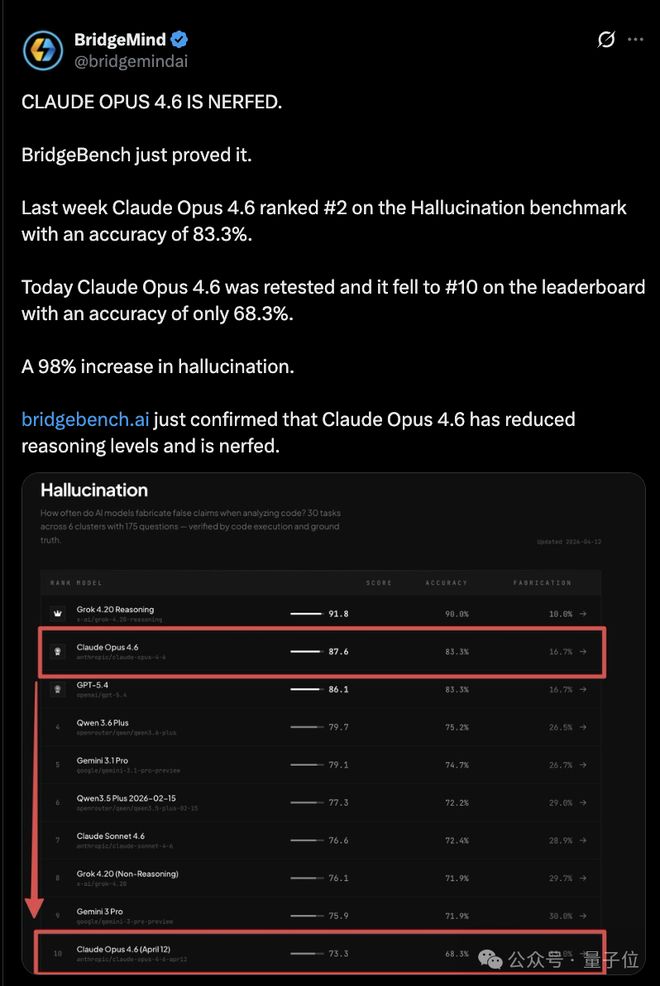
与此同时,BridgeMind测试平台也记录到了Opus 4.6准确率从83%降至68%,排名下滑至第十位的情况。
尽管研究者后来质疑这种评测方法的准确性,但这些数据已经让“Claude变笨”成为了一个热门话题。
社交媒体上甚至出现了新词AI缩水通胀,意指用户为相同的价格获取了质量更低的产品。
不是刚刚,是最近。

在当时,许多用户虽然对Claude的质量下降不满,但由于没有替代品,只能继续使用它。
直到GPT-5.5发布后,Anthropic公司才决定公开承认问题,并在官方博客上发布了详细的回顾文章。
其中提到了三个具体的问题:推理级别被降低、缓存清除机制出错以及提示词限制导致的输出质量下降。
3月4日,推理默认值从高调整为中;3月26日,由于代码bug,每轮对话都清空了之前的思考记录;4月16日,则是对回复长度进行了新的限制。
这些问题影响到了不同的用户群体,并在不同时间段内发生。综合起来看,整个Claude模型的性能持续且不均匀地下降。
除了技术故障外,Anthropic公司在四月份还采取了一系列策略调整措施,包括对第三方工具的限制和价格政策的变化。
这些变化引发了许多用户的不满,并引发了关于成本控制与用户体验之间的平衡问题的讨论。
针对此事,官方回应表示会重置用户额度作为补偿。然而,一些人认为这种做法更像是常规操作而非实际补偿。
结合上述种种情况,网友们的反应开始出现分化:一部分人认为公司已经尽了最大努力解决问题,并且保持了一定的透明度;而另一部分则对公司的处理方式提出了质疑。
近期,许多用户已经开始转向其他替代模型。例如Codex和GPT-5.5,后者特别强调在编码方面的能力提升。
偷偷降了推理等级
与此同时,DeepSeek V4也已经准备就绪,Gemini的发布也被期待中。
越聊越傻
对于Anthropic来说,修复错误和恢复用户信任的时间窗口正在变得越来越紧迫。
Claude继续干活,但逐渐忘了自己为什么要干这件事。健忘、重复、工具调用乱飞,就是这个bug的症状。
而且因为思考记录被反复清,每次请求都缓存未命中,token消耗反而飙升。花了15天才修好。
一句提示词砸了输出质量。
4月16日,系统提示里加了一条「工具调用之间文字不超过25个词,最终回复不超过100个词」。
Opus 4.6和4.7都掉了3%性能,四天后回滚。
三个问题影响不同用户群,在不同时间段生效。叠加起来的效果就是整个Claude Code在持续、不均匀地变差,但谁也说不清到底哪里不对。
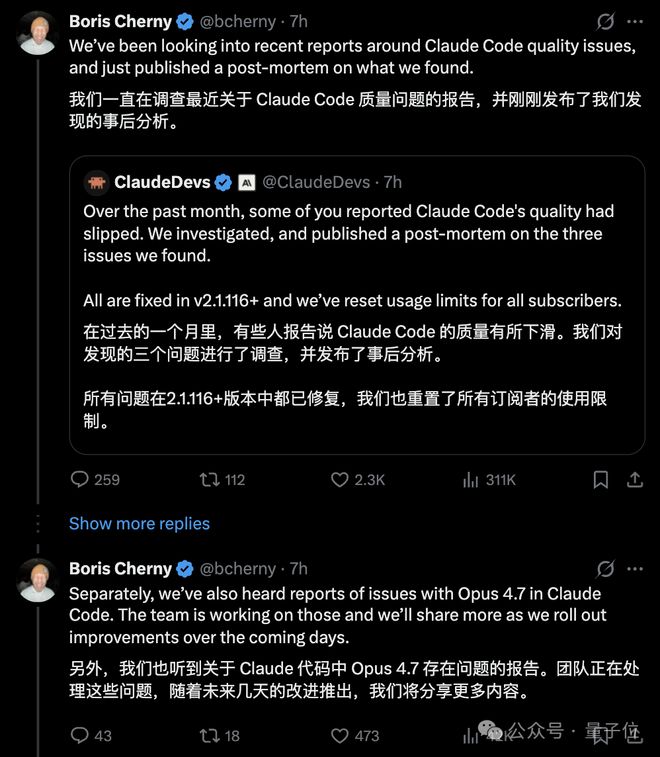
官方推特上,ClaudeDevs发总结,Claude之父Boris Cherny也亲自下场回复,并预告Opus 4.7的bug也正在de了。
但问题是,光有bug不够解释这两个月发生的一切。
四月里,A社的骚操作一箩筐
把时间线拉开看,四月其实是A社连续三拳打在自己脸上。
4月4日,Anthropic封禁了OpenClaw等第三方agentic工具通过Pro/Max订阅运行。想继续用?去走API按token付费。
4月21日,官方定价页悄悄把Pro plan里的Claude Code去掉了,支持文档也从「Pro或Max plan」改成了「只有Max plan」。
被网友抓包后,Head of Growth Amol Avasare出来说这只是2%新用户的A/B测试。但问题是公开页面是全站更新的,口径完全对不上。几小时后灰头土脸地回滚。
连起来算一笔账。Pro用户20/月,年费240。要继续用Claude Code,得升到Max 5x,100/月起步,年费1200。五倍。Max 20x是2400,十倍。中间没有过渡档。
注意,这里单位是美元。
4月23日,就是今天,postmortem上线,补偿是重置使用额度。
有网友不客气地指出,上周Opus 4.7发布时就已经重置过一次了,所以这次的「补偿」其实就是一次正常的周期重置。
三件事连起来,味道就不是bug了,是成本焦虑全面爆发。
网友不买账
综上种种,对于Claude,网友的反应也开始分化。
有人觉得出bug可以理解,postmortem写得也算透明。Boris在HN一条一条回复,这比大多数公司做得好。

但更多人在算另一笔账。
这两个月里,所有正式渠道一声不吭。
只有几个员工在X上零星回复用户,而且被批评为「随机时间随机回复」,完全不成体系。

还有人质疑「缓存优化」的真正动机。清除思考记录的触发时间恰好卡在缓存过期的节点上,有人觉得这不是为了降延迟,是为了省成本。
同期Anthropic还对一小部分Pro用户做了A/B测试,悄悄给了不同的产品配置,信任又挨了一刀。

补偿措施是重置使用额度。有人不客气地指出,上周Opus 4.7发布时就已经重置过一次了。
BridgeMind的BridgeBench测试也在这段时间炸了锅,显示Opus 4.6准确率从83.3%掉到68.3%,排名从第2跌到第10。
虽然后来被研究者批评方法论有问题,前后测试的任务数量根本不一样,但「Claude变蠢了」的叙事已经传开了。
正如一位网友说的,不能把所有鸡蛋放在一个模型公司里。

One more thing
HN评论区里一个有意思的现象,不少人在聊自己的「迁移经历」。
有人说二月份就「下意识地」转去了Codex,直到现在才意识到大概是被Claude变差给逼的。

也有人说GPT-5.4已经比Opus4.6好了。

还有人在用MiniMax做补充,40美金4500条消息一个5小时周期,还能看到完整思考过程。

半年前「写代码就用Claude」几乎是共识。
现在Codex有400万活跃用户,GPT-5.5主打的就是编码和计算机操作能力,连OpenAI的人都直接说这个模型能当「参谋长」用。
Claude不是变差了。是别人变好了,而它在最不该出问题的时候出了问题。
留给Anthropic修bug和重建信任的窗口,比两个月前窄了不少。
GPT-5.5已经发布,DeepSeek V4俨然就位。
Gemini快来吧!就差你了。
[1]https://www.anthropic.com/engineering/april-23-postmortem
[2]https://news.ycombinator.com/item?id=47878905