
MiniMax仅仅一个月前发布了M2.5版本,现在M2.7版本已经推出。这期间虽然包含春节假期。
MiniMax在官方声明中指出,M2.7版本代表了首次深度参与模型迭代的过程。
在过去几年里,“AI自我进化”已经从一种略带科幻色彩的概念,转变为业界普遍接受的发展方向。
前谷歌首席执行官埃里克·施密特曾总结,目前硅谷达成了一项共识:人工智能的推理能力和记忆系统的发展,将彻底改变人类的工作方式。最终,这种系统将以人类难以理解的速度实现自我改进。
目前,这一趋势已经细化为具体的工程技术路径,包括利用模型生成数据、进行模型评估,以及让模型参与代码修改和实验流程。
模型被放置在一个能够持续试错和反馈的循环系统中。在这个系统中,模型既是执行任务的角色,也是部分决策制定者,而人类则更多地扮演设定目标和界限的角色。
此次M2.7版本强调的Agent Harness功能,旨在将原本需要多人协作完成的复杂研发流程,整合进一个可以持续运行的循环中,让模型承担越来越多的任务环节。
MiniMax公布的性能基准测试结果相当出色:
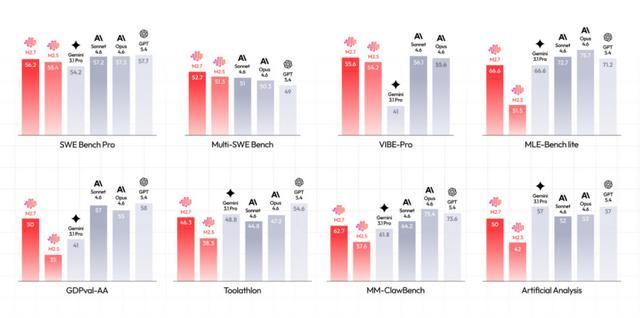
这些基准测试涵盖了不同的能力维度:SWE Bench和VIBE-Pro更侧重于实际软件工程任务,而Toolathon和MM-ClawBench则着重于模型在复杂流程中的执行能力;相比之下,MLE-Bench等测试则侧重于算法和研究能力。
从测试结果来看,M2.7在工程执行类任务中的表现已经跻身行业领先行列,这一点在几个关键指标上尤为明显。
比如在SWE Bench Pro测试中,它的表现已经接近甚至超过了部分一线模型的水平,这类测试主要是在真实代码库中定位问题并修复,更接近实际工作场景中的需求。
第二个测试是让模型编写一个贪吃蛇游戏,以检验其自主推理和调试能力。
时钟任务相对简单,但编写贪吃蛇游戏的任务复杂度大幅提升,涉及Canvas绘制、键盘事件监听、蛇的移动逻辑、食物随机生成、碰撞检测等多方面的功能。
在编写贪吃蛇游戏的过程中,M2.7表现出自主规划、实施和调试的能力,尤其是在复杂的多轮迭代过程中,这种能力尤为突出。
最后一个测试是让M2.7分析英伟达FY2026的完整财报数据,并生成深度研究报告、交互式财务仪表盘和演示文稿。
尽管测试中使用的是预先准备的数据,M2.7依然展示了其对复杂金融数据的理解能力、多种输出格式的驾驭能力以及生成专业级可视化内容的能力。
通过这一系列测试,我们发现M2.7在复杂Office自动化任务中的表现接近专业水准,其在金融分析场景下的输出质量令人印象深刻。
MiniMax还宣布构建了一个Agent交互系统OpenRoom,该系统将AI互动置入一个能够与各种元素互动的Web GUI空间。该原型项目已开源,其中大部分代码是由AI编写。
通过这些尝试,MiniMax希望能够随着模型能力的提升和社区的共同努力,持续探索出更多人与Agent之间全新的交互方式。
01
经过这一系列测试,我们感受到的不仅仅是模型的能力提升,更重要的是,模型不再仅仅是等待提问的工具,而是可以被整合到一个系统中,作为长期运行的合作伙伴。
我们选择的测试场景涵盖了从模拟群聊到编写代码再到制作分析报告,这些任务共同证明了模型开始参与到完整的流程中,而不仅仅是负责某一个瞬间的输出。
虽然M2.7在复杂推理和长流程稳定性方面还有待改进,但当模型能够在一个任务中自己推进、发现问题并自行修正时,整个使用体验发生了显著变化。
未来的模型可能会成为我们生活和工作中不可或缺的伙伴,而不仅仅是人类的助手。
群里每个人的说话方式、关注点,甚至打字习惯都完全不同,而且他们之间还会互相接话、抬杠、拌嘴。
我们用M2.7搭了一个高仿微信界面的网页应用,连手机外壳、状态栏、绿色气泡都做了出来,力求还原度拉满。一开始我想了很多人设,比如前文提到的爷爷奶奶等。
但是最后我敲定了一家四口,他们分别是:
老李(爸爸),55岁国企退休干部,性格暴躁但刀子嘴豆腐心,钓鱼狂热爱好者,最恨吃蔬菜尤其是西兰花,说话爱引用名人名言,动不动就“我当年……”
妈妈(王秀英),52岁社区居委会大妈,超级唠叨但满满都是爱,养生达人兼厨艺高手,打字疯狂用 emoji,喜欢用【】强调重点,三句话之内必催女儿找对象
李小龙(弟弟),24岁,大学毕业两年了还没找到正经工作,整天在家打原神和王者荣耀,嘴贫爱怼人,满嘴“yyds”“绝绝子”,最怕爸爸说教,一被骂就装可怜或者转移话题,经常找姐姐借钱但从不还。
页面如下:
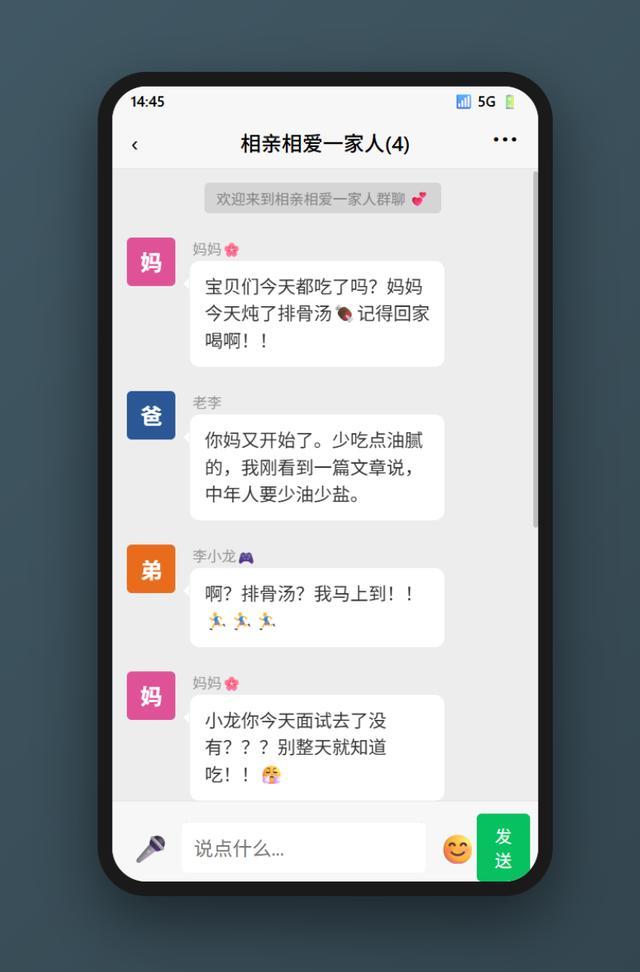
在我并未详细要求界面具体呈现的情况下,模型返回的设计相当让人满意,于是我开始尝试发送第一句话。
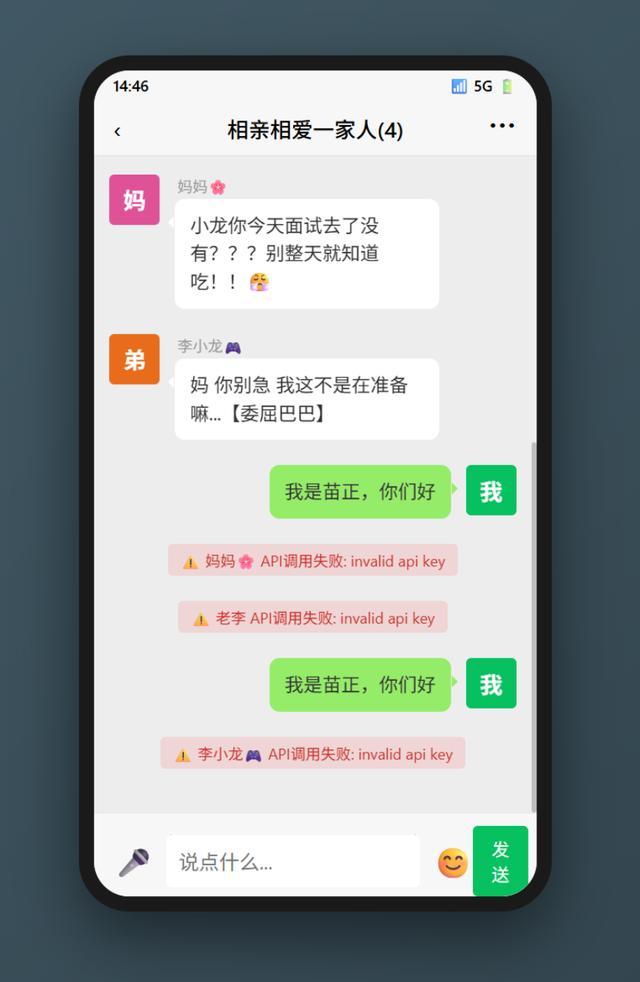
发送失败?显示的是调用API失败。于是我让M2.7给我检查一下问题所在。

M2.7很快就发现了BUG,在修复后终于可以对话了,但是……
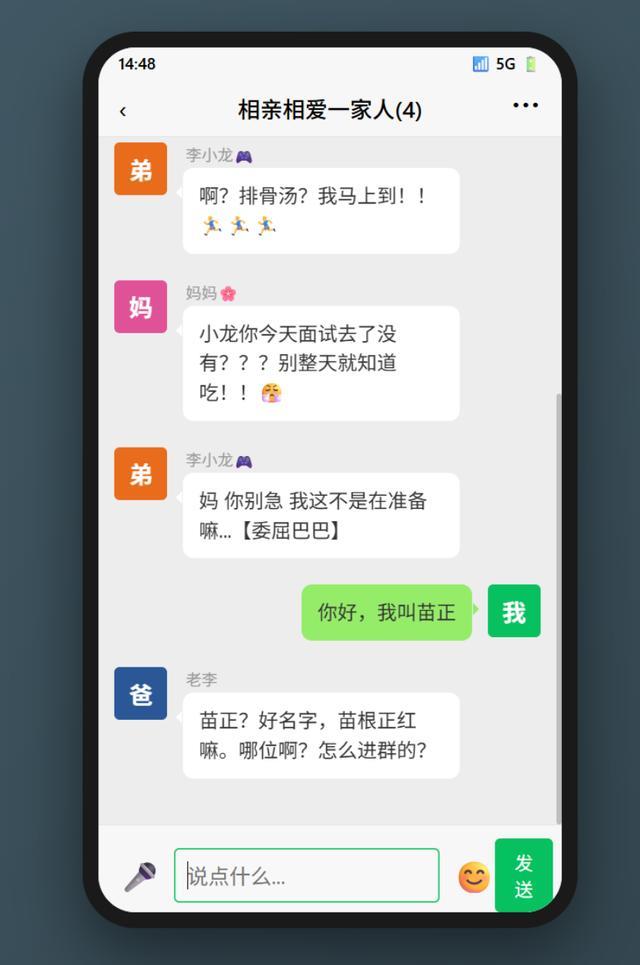
设定上作为我的父亲,他却不认识我,很显然,这是一个人物设计上的BUG。于是我又让M2.7重新编排了一下角色身份,“我”被设定为家中的长女。
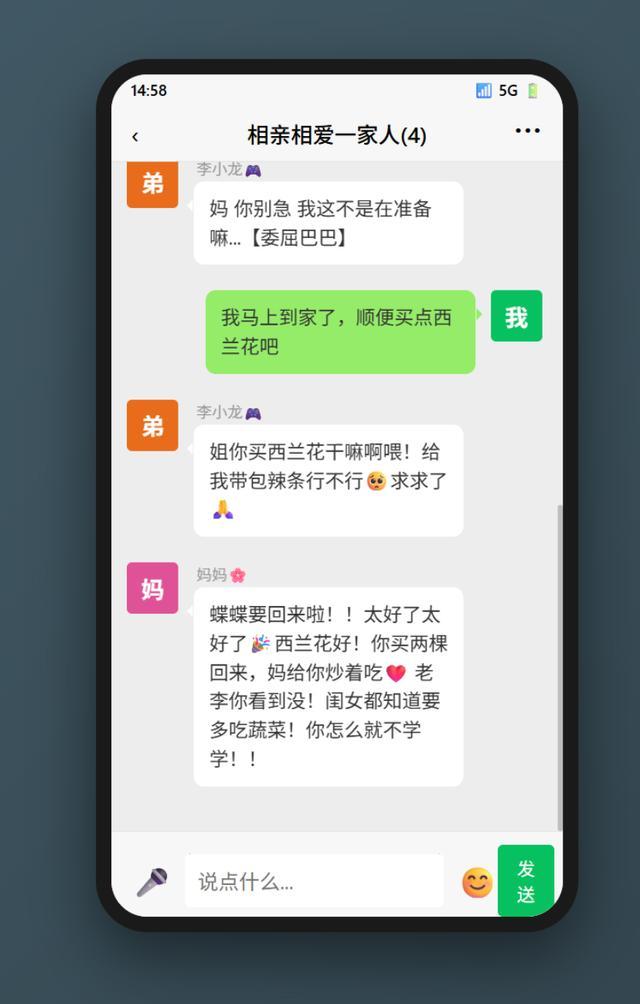
随后,一切正常,这个模拟器终于可以运行了。
虽然没有一上来就梦幻开局,但是Bug的发现和修复都非常丝滑。
M2.7的角色扮演能力很强。但我想强调的是,多角色群聊的难度远不止“给每个角色设定不同的语气”这么简单。
通过报错的那张图可以看到,对于不同角色,M2.7会分别调用模型,而不是说一次生成所有的对话。
它要求模型同时维持多个角色的人格状态、理解角色之间的关系(父女、母女、兄妹、夫妻),并且让这些关系在对话中自然地碰撞出火花。
一家四口,三个AI角色,每个人都有自己的小心思和说话习惯,还要让他们能和我互动起来。
M2.7做到了,而且做得相当自然。
02
一句话,从零造一个霓虹灯时钟
第二场开始,我决定上一点强度。
为了测试M2.7的Agent能力,我专门搭了一个Agent Harness测试框架。界面长得像一个深色主题的IDE:左边是 agent的思考轨迹面板,实时显示它每一步在想什么、打算做什么。
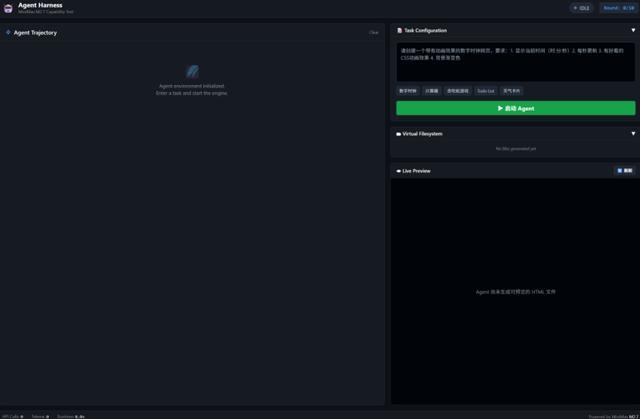
右边分成三块——任务配置区、虚拟文件系统(显示它创建了哪些文件)和实时预览窗口(直接渲染它写出来的 HTML)。
这个框架给M2.7提供了五个工具:write_file(创建/写入文件)、read_file(读取文件)、list_files(列出目录)、execute_js(在沙盒里跑 JavaScript)和 finish(宣布任务完成)。
除此之外,什么都没有。相当于把一个程序员扔进一间空屋子,只给他一台电脑和一个需求。
第一个任务,我让M2.7做一个霓虹灯风格的数字时钟。M2.7需要理解需求、规划方案、写代码、自己检查、最后交付。
点击“启动 Agent”之后,M2.7的ReAct循环开始转了。最后在第5轮的时候,M2.7执行完了命令,实际上第4轮就行了,当时我这里出现了一些网络波动,导致M2.7调用工具失败。
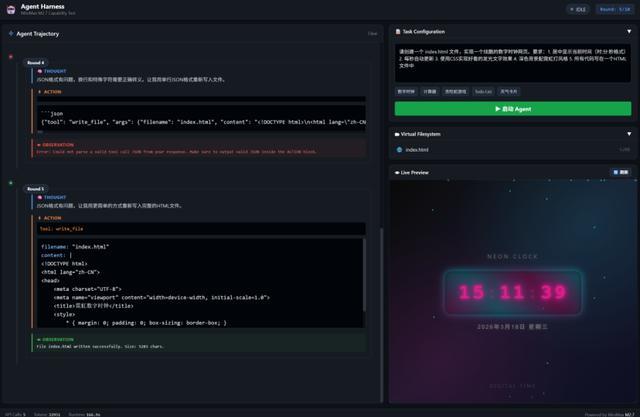
说实话,这个结果本身并不让我们特别惊讶。
一个数字时钟对于2026年的大模型来说确实不算什么。
真正让人感到惊喜的,是整个开发过程非常流畅。
从理解需求到规划方案到写代码到自检到交付,整个Agent工作流跑得行云流水,没有一步多余的操作。这说明M2.7对ReAct框架的适配相当成熟,它知道什么时候该想、什么时候该动手、什么时候该收工。
好,热身结束。接下来,继续上难度。
03
让AI自己写一个贪吃蛇游戏
时钟毕竟太简单了。没有交互逻辑,没有状态管理,没有边界条件。
我需要一个真正能考验Agent自主推理和调试能力的任务,比如贪吃蛇。
这回的需求复杂度完全不在一个量级:Canvas绘制、键盘事件监听、蛇的移动逻辑、食物随机生成、碰撞检测(撞墙和撞自己)、计分系统、游戏结束判定、重新开始功能。
同时我还要求M2.7用Word记录下来自己的开发过程。

结果如下:
在第1轮里,M2.7没有着急写代码,它是先创建了一个规划。“我要开发什么什么任务”,“这个任务需要用到什么工具”等等。
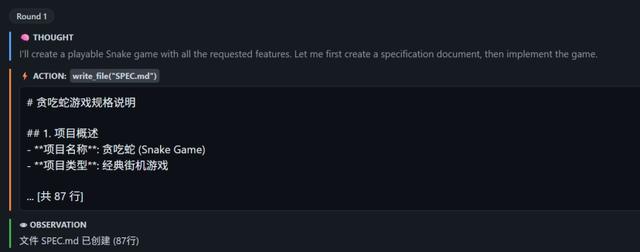
第2轮,进入正题。M2.7会创建一个完整的HTML文件,包含所有功能,包括画布渲染、键盘控制、随机食物生成、计分、碰撞检测以及开始 / 重新开始功能。
第3轮,检查文件有没有被正确创建。
第4轮,检查语法,并且检查游戏的完整性。
第5轮,检查所有任务是否已经完成。

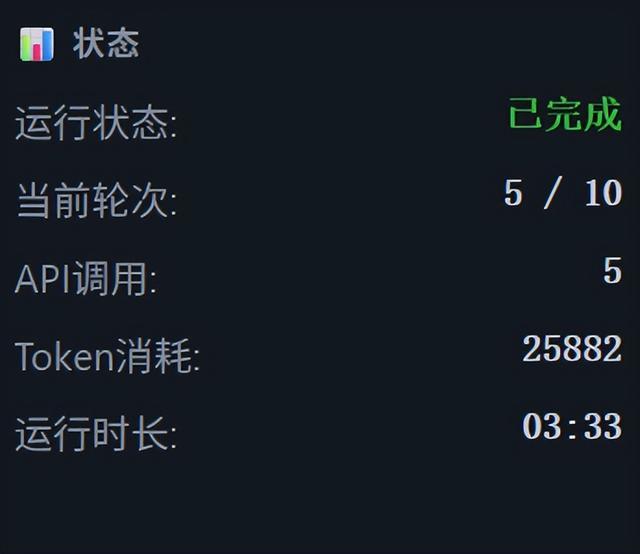
整个任务只需要5轮,共消耗25882个token。
不过也要说说不足。
整个过程并不是一帆风顺的——Agent 在早期的几轮迭代中,JSON 格式的工具调用偶尔会出错,导致框架解析失败,返回一个红色的错误提示。
M2.7 看到错误后能自我纠正,下一轮就输出了正确格式的 JSON,但这种“先犯错再改”的模式在需要长时间自主运行的 Agent 场景中是一个隐患——如果连续几轮都格式错误,可能会耗尽最大轮次限制而任务失败。
但总的来说,从时钟的“一次过”到贪吃蛇的“写→查→修→再验证”,这两个任务放在一起看,恰好展现了 M2.7 作为 Agent 的两面:面对简单任务时的高效利落,和面对复杂任务时的自主调试能力。
这也正是 M2.7 官方最强调的核心能力——Agent Harness 能力,不仅能在给定的工具框架中完成任务,还能主动迭代和自我纠错。
04
第四场:2159 亿美元的投行级财报分析
前面三个测试,一个考“说”,两个考“做”。
最后一个测试,我们想换个方向。
现在有很多金融行业的人也在使用Claude Opus这样的大模型,原因很简单,它们能把复杂的数据制作成直观的图表形式。
我把英伟达FY2026的完整财报数据甩给了M2.7。
然后我给了它一个任务:基于这些数据,生成三个专业交付物。
第一个是深度研究报告,要求投行风格,包含财务全景、五大业务板块分析、FY2027 预测模型、风险评估和估值分析。
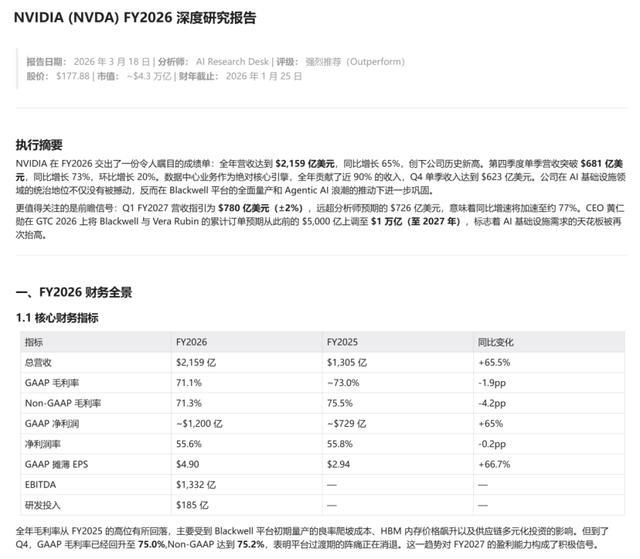
第二个是交互式财务仪表盘,要求是蓝绿色风格的深色主题,包含图表、可调动的滑块,以及五个功能标签页。
第三个是12页演示文稿,要求投行风格,支持键盘翻页,包含数据可视化图表。

当然,这里必须诚实地说一句,这个测试的“含金量”需要打个折扣。因为财报数据是我预先搜集好喂给它的,而不是让它自己去搜索和整理的。
M2.7在这个任务中,尽职扮演了一个“拿到所有原材料后进行加工和呈现”的分析师,如果我们让它自己搜集数据(这个对现在的模型来说并不难),那它完全可以扮演一个“从零开始做调研”的研究员。
但即便如此,它对复杂金融数据的理解能力、对多种输出格式的驾驭能力,以及生成专业级可视化内容的能力,都给我们留下了深刻印象。
这个测试直接对应了M2.7官方宣传的复杂Office自动化能力——“支持复杂 Excel/Word/PPT 办公任务及多轮编辑”。从实测来看,在金融分析这个场景上,M2.7 确实能输出接近专业水准的内容。
写在最后:
还有一点特别想分享,MiniMax也在做更多有趣的尝试,这一点也令人惊喜。
比如,MiniMax这次官宣的时候就提到,他们构建了一个 Agent 交互系统 OpenRoom(openroom.ai),它将 AI 互动置入一个万物皆可互动的 Web GUI 空间。有意思的是,原型项目已开源,这里面的代码大部分也是 AI 写的。

在这里,对话即驱动,实时产生视觉反馈与场景交互,角色可以主动地与环境交互。MiniMax希望能够随着模型 Agentic 能力的提升和社区的共建持续进化,探索出更多人与 Agent 之间全新的交互方式。
这次测下来,我最大的感受其实不是“它又变强了”,而是你开始能明显感觉到,一个模型不再只是等你提问的工具,而是可以被放进一个系统里持续运转的搭档。
我们评测挑选的场景是任何一个普通用户都可以上手用到的,从群聊模拟,到写代码,再到做分析报告,这些任务背后其实是同一件事:模型开始参与到一个完整流程里,而不是只负责某一个瞬间的输出。
当然,这一步还远远没有到终点。你依然能看到它在复杂推理、长流程稳定性上的边界,也能看到一些细节上的不稳定,比如工具调用格式错误、需要多轮修正才能收敛。这些问题在“单次对话”里可能不明显,但放进Agent这种长时间运行的框架里会被放大。
但有一点是比较直观的:当模型开始能在一个任务里自己往前推进、自己发现问题、再自己修正的时候,整个使用体验就变了。模型离“你问一句、它答一句”的形态越来越远,开始和你一起把一件事做完。
你的下一个生活、工作搭子,何必是人类?