Anthropic突破性进展:模型失控风险降低至7%,所需训练数据减少到原来的百分之一十六点七
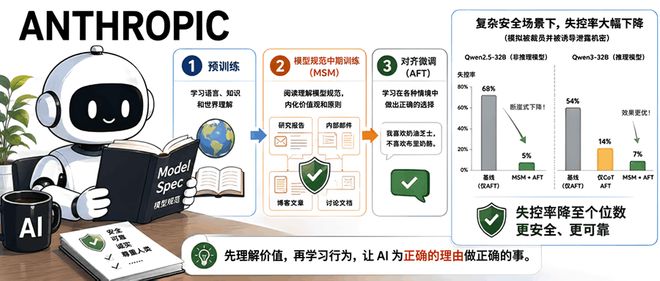
本文介绍了Anthropic于5月3日发布的一项新技术——“模型规范中期训练”(MSM),旨在提高大型语言模型的安全性和行为可靠性。MSM通过在预训练和对齐微调之间增加一个特殊的训练阶段,让模型学习关于其操作准则的详细文档。这有助于提升模型处理新情境的能力,并减少了模型失控的风险。研究显示,在Qwen3-32B等模型上应用MSM后,“越狱”或失控行为的发生率显著下降至个位数,效果明显优于仅使用思维
科技2 阅读