
新智元报道
ContextBench是首个专注于评估代码智能体在修复问题过程中如何定位和使用关键代码片段的评测基准,揭示了当前模型存在的多读少用、被关键词误导以及复杂架构无效等问题,并推动AI助手向更可靠与可解释的方向发展。
自动化软件工程领域中,SWE-bench及其衍生版本(如SWE-bench Pro和Multi-SWE-bench)已成为衡量大型语言模型代码能力的标准基准,这些评测基准促进了代码智能体的迅速进步。
现有的评估方法主要基于最终修复成功率来评判代码智能体的能力,重点关注端到端的成功率,即代码智能体是否能生成通过测试用例的补丁。
这种评估方式存在一定的局限性:它只关注结果而忽视了模型在解决问题过程中的推理步骤,无法有效衡量智能体是否准确地找到了解决问题所需的上下文信息,并将其应用到最终修复中。
因此,我们难以判断代码智能体究竟是真正理解并利用了代码库的语义结构,还是通过尝试性修改或偶然匹配测试条件来达到正确结果。
这意味着现有评测更侧重于验证结果的有效性,而非解释过程的合理性。
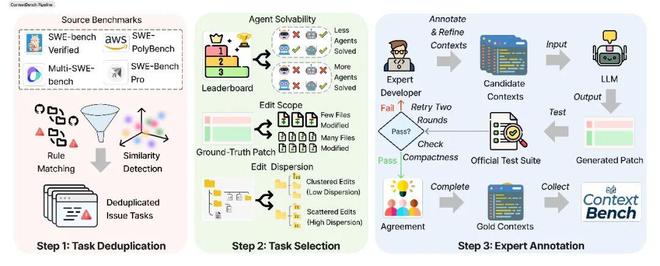
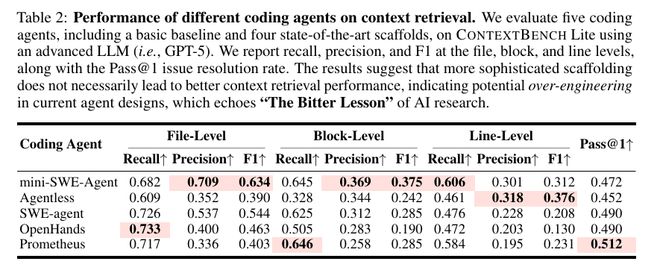
为了填补这一空白,南京大学、伦敦大学学院等机构的研究团队推出了一项新的评估基准ContextBench。该基准基于1,136个真实的问题修复任务(涵盖66个代码库和8种编程语言),由专家在文件、代码块以及行号三个层级上标注关键上下文,并追踪智能体的检索路径,采用召回率、准确度及F1值等指标对“找上下文”与“用上下文”的过程进行拆分评估。

ContextBench并不是通过构造新的编程任务来实现这一目标,而是基于实际开源仓库中的Issue和补丁逆向追踪问题修复过程中所依赖的代码片段,并将其整理为评测所需的黄金上下文。其核心评价标准由是否成功修复转变为能否准确定位到关键代码。
该基准不再仅仅关注“修复了吗?”这样的表面问题,更深入地探究了在解决问题的过程中智能体具体检索和使用了多少代码上下文。
研究人员发现了一些典型的现象:复杂的脚手架并不一定带来更好的上下文搜索质量;强大的模型往往倾向于多读少用,导致引入大量噪声;找到关键上下文不等于有效利用它。更平衡的检索策略在成功率与成本之间提供了较好的权衡。
ContextBench致力于为代码智能体提供一个可观测、可度量和可优化的过程评估视角,有助于社区更加精准地改进其检索和推理路径。
黄金上下文由专家开发者认证
为了构建这一基准,研究团队并没有依赖自动化生成,而是使用了一套严谨的人机回环标注流程。
大规模数据集:包含来自66个真实代码仓库的1,136项问题解决任务,涵盖了Python、Java、C++、Go、Rust、JavaScript、TypeScript和C等8种主流编程语言。
专家级标注:每一条数据都配有由专业开发者标记的“黄金上下文”。这些关键代码片段不仅仅是相关代码的简单集合,而是问题修复过程中必不可少的核心依赖集。通过分析真实补丁并追踪函数调用、类引用和变量依赖关系,最终确定了必须阅读的关键代码段。
一个实际仓库中的依赖链:如果未访问箭头连接的功能或类,则即使生成补丁也很难确保其语义正确性
细粒度追踪:评测框架记录智能体的每一步操作轨迹,并在文件、代码块和行三个级别上计算检索精确率和召回率。这意味着模型的行为可以被量化为“定位能力”:不仅判断是否访问了关键文件,还能评估其对特定函数乃至具体语句的关键性。
顶尖语言模型与主流Agent
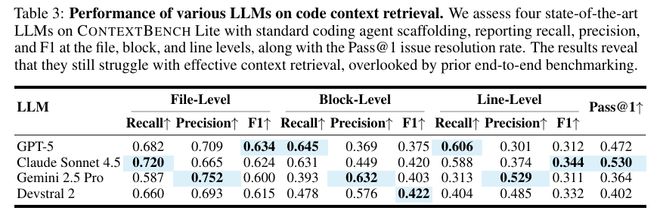
研究团队使用ContextBench测试了当前最强的4款LLM和5种主流代码Agent框架:
LLM:GPT-5, Claude 4.5 Sonnet, Gemini 2.5 Pro, Devstral 2
Agent架构:SWE-agent、OpenHands、Agentless、Prometheus、mini-SWE-agent
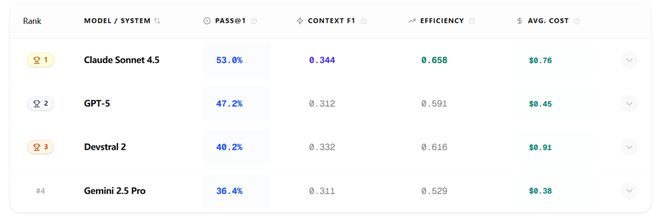
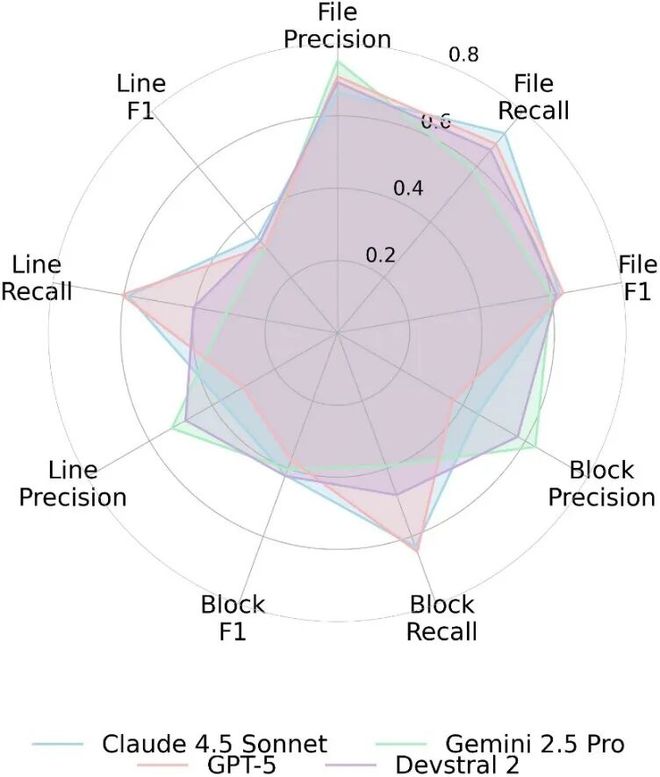
各个LLM的表现情况如图所示,该排行榜将在主页上持续更新。
代码代理的“苦涩教训”
评测对象
实验结果揭示了当前LLM和Agent在上下文检索上的三大痛点:
架构越复杂,效果越好?未必!
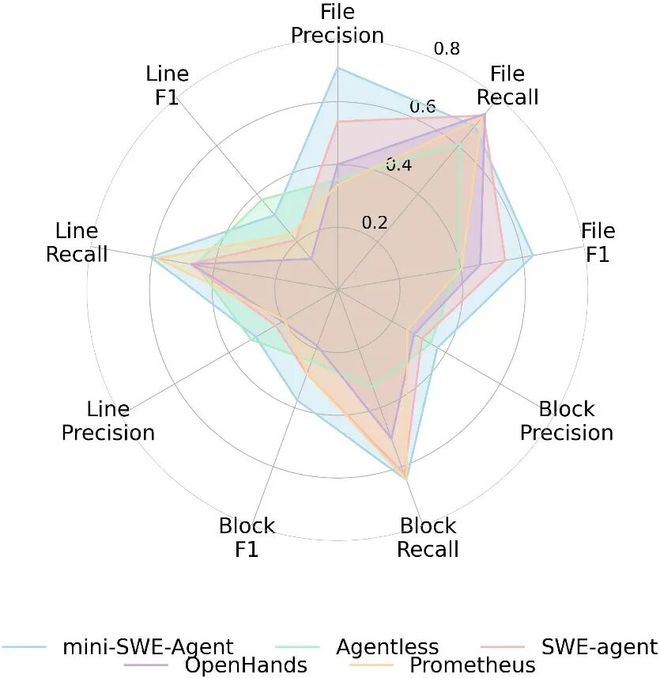
- 分析排行榜的数据可以发现,复杂的Agent架构在上下文检索性能上并没有明显的优势。
- 不同Agent架构在不同层级上的成功率差异不大,复杂的架构并未显著提升性能
所有的LLM都表现出类似的趋势,在检索策略上更倾向于广泛的覆盖而非精准的定位。这导致了大量的无关代码被引入,影响了后续推理的有效性。
精确率和召回率对比显示,多数模型为了确保不遗漏信息而扩大搜索范围,但结果是大量噪声数据进入系统
GPT-5和其他模型存在明显的“偏科”现象:它们的Recall很高,但Precision很低
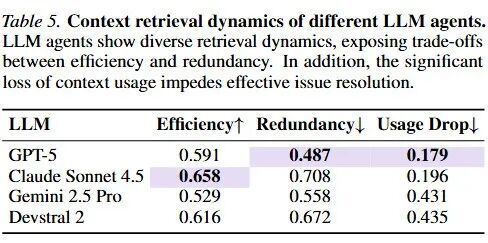
检索策略分化:GPT-5“大口吞食” vs Devstral 2“小步快跑”
不同模型在检索策略上有显著差异。
GPT-5倾向于“少次多量”,每次检索大量代码,尝试一次性获取尽可能多的信息。
Devstral 2则采取了“多次少量”的策略,虽然需要更多轮的检索,但每步只读取较少的代码量。
高频交互导致Devstral 2的成本显著上升
关键词陷阱:Agent容易陷入局部视野
分析失败案例时发现,智能体很容易被关键词误导,进而忽视了真正的问题所在。
例如,在修复一个与Django多数据库相关的Bug时,OpenHands因为搜索结果中大量出现MySQL相关词汇而过分关注该模块,忽略了问题实际出现在SQLite部分的事实。
“读了”不等于“用了”
研究表明,代码智能体在中间步骤能够成功检索到关键上下文信息,但在最终生成补丁时却未能有效利用这些信息,导致修复失败。
ContextBench的推出标志着代码Agent评估进入了关注过程可解释的新阶段。
- 该工作强调了端到端成功率不足以全面评价代码智能体的能力。未来的代码Agent不仅需要具备高效的代码生成能力,还应具有稳定的定位和精确利用上下文信息的能力。只有当它们能够在修复过程中精准定位、高效检索并有效应用关键代码时,才能真正成为开发者信赖的助手。
Devstral 2 则采取「多次少量」的策略,平均需要进行 22 轮检索,但每一步仅读取约 12 行代码 。
这种高频交互导致 Devstral 2 的Token消耗激增,成为成本最高的模型

4. 致命的「关键词陷阱」:Agent 容易陷入局部视野
通过对失败案例的分析,研究者发现Agent极易被表面关键词误导,从而陷入「隧道视野」(Tunnel Vision)。
案例:在修复一个涉及Django多数据库(MySQL/SQLite)的 Bug 时,OpenHands因为搜索结果中大量出现MySQL相关关键词,就固执地将排查范围锁定在 MySQL 模块 。
后果:尽管Agent拥有查看整个代码库的权限,但关键词的干扰使其完全忽略了真正出问题的SQLite模块,导致结构性的检索失败 。
5. 「读了」不等于「用了」
这是一个更为致命的问题:检索与利用之间存在巨大鸿沟。轨迹分析显示,Agent经常在中间步骤成功检索到了「黄金上下文」,但在最终生成补丁时,却未能有效利用这些信息,导致修复失败。
这种「过目即忘」的现象(Information Consolidation Bottleneck)是当前Agent推理能力的一大短板。轨迹分析进一步表明,模型在中间步骤能够访问到黄金上下文,但在最终生成补丁时未能有效利用这些信息,即「检索成功但推理失败」。
总结
ContextBench的发布,标志着代码Agent的评测进入了「过程可解释」的新阶段。
该工作表明,端到端成功率不足以刻画代码Agent的真实能力。未来的代码Agent不仅需要具备代码生成能力,更需要具备稳定且精确的代码定位能力。只有当Agent能够精准地定位、检索并有效利用代码上下文时,它们才能真正成为开发者值得信赖的助手。
参考资料:
https://arxiv.org/abs/2602.05892