
新智元报道
AI不再只是童年回忆中的游戏,而是成为了训练大模型的坚实平台:OpenRA-RL将即时战略游戏《红色警戒》改造为AI代理的训练场,并开源了多项关键技术。
AI能自己打红警了。

近期,Hugging Face推出了一个名为OpenRA-RL的新项目,它让经典RTS游戏成为大型语言模型训练的实际应用环境。

这不是简单的演示或玩具级别的展示,而是具备基础设施级功能的真实工具。
OpenRA-RL提供了50个MCP游戏工具的全面访问权限,并通过25Hz实时状态流不断更新信息。同时支持单进程64局并发训练,兼容LLM、脚本Bot和强化学习代理等多个方面的发展需求。
更进一步的是,该项目原生接入了OpenEnv生态系统,使得TRL、torchforge及Unsloth等训练框架可以无缝集成使用。
以前如DeepMind的AlphaStar和OpenAI Five在星际争霸II或Dota2中的表现需要数千块TPU以及独特的定制架构支持。
对于大多数研究者而言,这样的资源几乎是不可触及的。
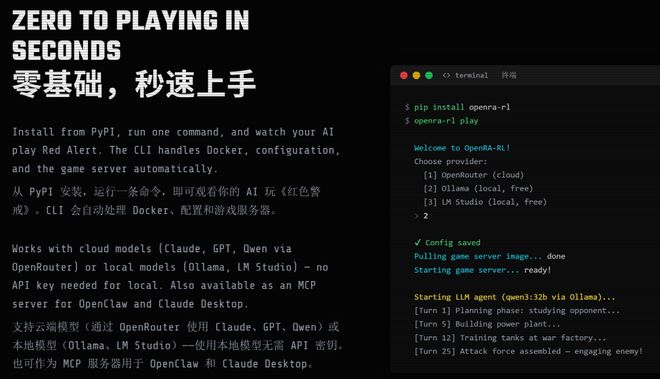
相较之下,现在开源社区已经大幅降低了即时战略游戏代理训练的门槛。只需要一台消费级显卡和一条pip install命令即可开始自己的实验。
在实际操作中,Qwen3 32B模型被部署在本地环境中,并与游戏内置的初级AI进行了多局对抗测试。
让我们看看实战。
游戏过程中,代理通过MCP工具集接收结构化的观测数据并发出指令。每局比赛前有策略规划阶段,在结束时进行反思和复盘,从中提取经验以指导后续决策。
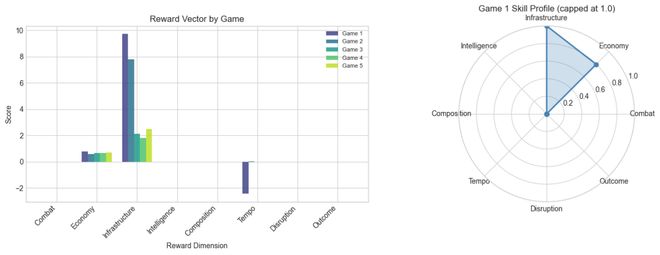
结果表明,尽管经济管理得分很高,但在战斗方面的表现却几乎为零。模型在每一局比赛中都能成功建立起经济体系,但从未生产出任何进攻部队。
虽然所有比赛最终都以平局告终,但OpenRA-RL提供的8维奖励向量揭示了更丰富的信息:经济得分范围从0.58到0.80,基础设施表现稳定,而战斗和骚扰维度的分数则为零。
这种详细的失败模式分析有助于研究者设计出更好的奖励塑造策略及课程学习方案。
例如,在第五局比赛前10回合的日志中清晰地展示了模型的学习节奏:情报收集与规划阶段,随后是经济建设阶段,最后则是通过快速推进来弥补LLM推理延迟的问题。
工具调用分布也证实了这一点,其中advance操作占据了大约57%的比例,这正是异步架构设计的核心优势所在。
另一个值得注意的发现是在第二局比赛后反思阶段识别出建造顺序错误,并在第四局开始时进行了修正,说明提示注入式学习可以解决某些特定问题。
为什么选择《红色警戒》作为训练场?
Turn 1 | get_faction_briefing()Turn 2 | end_planning_phase(strategy=「」Deploy MCV, build Power Plant (300 ticks), then Barracks/War Factory (500/750), train E1 + 1tnk, attack AI base at (64,64).「」)Turn 3 | deploy_unit(unit_id=120)Turn 4 | build_and_place(building_type=「」apwr「」)Turn 5 | advance(ticks=100) -> tick=55, cash=$5000, units=0, buildings=1Turn 6 | build_and_place(building_type=「」apwr「」)Turn 7 | build_and_place(building_type=「」powr「」)Turn 8 | advance(ticks=60) -> tick=108, cash=$4923, units=0, buildings=1Turn 9 | advance(ticks=130) -> tick=159, cash=$4838, units=0, buildings=1Turn 10 | advance(ticks=80) -> tick=210, cash=$4753, units=0, buildings=1这是因为即时战略游戏对于大型语言模型来说是一个挑战。现有平台通常不支持LLM代理的操作模式:高层接口、异步交互和可变推理延迟。
OpenRA-RL选择了经典的Westwood RTS《红色警戒》,基于开源项目OpenRA修改了游戏引擎,以便更好地适应大模型的需求。
该框架不仅适合Qwen3或Claude等大型语言模型,同样适用于Python脚本代理。所有这些都在相同的环境中进行测试,无需任何改动。
OpenRA-RL架构可形象地描述为“三层三明治”:底层是修改后的OpenRA游戏引擎;中间层通过gRPC实时传输观测数据和操作指令;顶层提供Gymnasium风格的API接口给Python客户端使用。
MCP服务器暴露了50个游戏动作作为工具,使任何兼容MCP的LLM客户端能够驱动整个游戏过程。
这种分层设计的核心目的是让代理计算与游戏执行完全解耦:一个40毫秒一步脚本Bot和一个2秒一步的大模型可以在同一引擎上运行而互不干扰。
64局并发训练在一个进程中就能完成
大规模评估需要大量同时进行的对战。早期版本中,每场游戏都需要启动一个新的.NET进程,导致内存消耗大且重置时间长的问题。
在改进后的v2版本中,通过优化使一个进程可以承载64个会话,并发运行时占用约6GB内存,重启延迟仅为256毫秒。
这种设计的关键在于发现ModData在初始化后是不可变的,可以在多个会话间无锁共享,从而节省了大量资源。
每个会话保留独立的世界、命令管理器和BotBridge以确保隔离性。
OpenRA-RL的价值不仅体现在让大模型在游戏中建造电厂这样的简单任务上,更在于它提供了一个硬核且开放的训练环境。
现实中复杂的策略深度使前沿的大模型在面对《红色警戒》最弱AI对手时也难以发起进攻。新手级别的游戏就足以揭示大模型在建造顺序、兵种搭配和进攻时机上的不足之处。
通过8维奖励向量,研究者可以精确地了解问题所在并针对性地设计课程以改进这些弱点。
团队已经规划了几个明确的发展方向:基于Qwen3基线进行GRPO测试;利用8维奖励开展课程设计;以及跨模型对比评测和代理之间的排行榜竞争。
三明治架构
对于AI代理领域来说,这套工具的意义远不止是让红警成为训练平台。它标志着强化学习在即时战略游戏中的真正应用开始。
以前只有DeepMind和OpenAI等大公司才能进行此类研究,而现在开源社区已经打破了这一壁垒。
中间是 gRPC 桥接层,实时往外推送观测数据、接收操作指令。
最上层是 Python 封装,对外暴露 Gymnasium 风格的reset / step / close接口。
在此之上,MCP 服务器把 50 个游戏动作暴露为工具,任何兼容 MCP 的 LLM 客户端都能驱动一局游戏。

这套分层的核心目的只有一个:Agent 的计算和游戏的执行完全解耦。
一个 40 毫秒一步的脚本 Bot 和一个 2 秒一步的 LLM,跑在同一个 25Hz 引擎上,互不干扰。
64 局并发:一个进程搞定
训练和大规模评估需要大量并发对局。
早期 v1 版本一局游戏开一个 .NET 进程,跑 64 局需要约 40GB 内存,每次重置要 5-15 秒——完全不能用。
v2 版本的核心优化是:一个 .NET 进程承载 64 个会话。
关键发现是 ModData(单位属性、建筑参数、科技树、地图规则)在初始化后不可变,加载一次就能跨会话无锁共享。
仅此一项就回收了约 35GB 内存。
每个会话保留独立的 World、OrderManager 和 BotBridge,彼此隔离。
结果相当暴力:重置延迟从 5-15 秒降到 256 毫秒(快了约 40 倍),64 会话总内存从约 40GB 降到约 6GB(省了约 7 倍),JIT 编译从 64 次降到 1 次。
真正重要的事
OpenRA-RL 真正重要的不是让一个大模型在红警里造了几座发电厂。
更重要的是:这个训练场够硬、够准、够开放。
环境本身有真实的策略深度——320 亿参数的前沿模型对阵最弱 AI,5 局打下来零交战,连一次进攻都没发起过。新手难度的红警就足以暴露大模型在建造顺序、兵种搭配、进攻时机上的短板。
而且暴露得很精确:如果只看胜负,5 局全是平局,一个字就讲完了;但 8 维奖励向量会告诉你,经济得分 0.58-0.80,基建表现不错,战斗和骚扰是干脆的零——弱点在哪、课程设计往哪开刀,一目了然。
团队在博客里列出了几个明确的下一步方向:
基于 Qwen3 基线跑 GRPO(同一个 Agent,权重更新替代提示注入,看战斗零分能不能动起来);
利用 8 维奖励做课程设计(从只需要战斗维度的场景开始,逐级往上爬);
跨模型横评(Claude Sonnet、GPT 级模型、更小的本地模型,同一张地图、同一个对手、同一个时间限制);
以及 Agent 对 Agent 的排行榜竞技。

对于 AI Agent 领域来说,这套工具的意义远不止红警本身。
AlphaStar 和 OpenAI Five 证明了 AI 能在 RTS 里达到超人水平,但那些成果被锁在高墙之后——几千块 TPU、定制架构、不可复现。
OpenRA-RL 第一次把这堵墙推倒了一部分:一台消费级显卡,一行pip install,你就站在了 RTS Agent 研究的起跑线上。
红警是一个信号——这是强化学习该登场的地方。
而现在,登场的门票终于不再只属于 DeepMind 和 OpenAI 了。
参考资料:
https://huggingface.co/blog/jadetan/openra-rl%20GitHub%20-%20yxc20089/OpenRA-RL:%20Open%20Framework%20for%20AI%20Agents%20to%20play%20Red%20Alert%20through%20Reinforcement%20Le%20
https://huggingface.co/spaces/openra-rl/openra-rl%20
https://openra-rl.dev/