
DeepSeek发布创新成果!多模态模型研究报告出炉:性能超GPT-5.4
DeepSeek近日在GitHub上公开了一款多模态推理模型及其技术报告《以视觉原语思考》。这个模型基于DeepSeek V4-Flash架构(总计参数量为284B,实际运行时激活的参数数量为13B)开发而成,并提出了一种新的多模态推理方式。研究指出当前市面上的许多大型多模态模型存在一个未被充分重视的问题:“指代鸿沟”(Reference Gap),即尽管这些模型能够识别图像中的内容,但在用自然语
科技7 阅读
共找到 113 篇相关文章
DeepSeek近日在GitHub上公开了一款多模态推理模型及其技术报告《以视觉原语思考》。这个模型基于DeepSeek V4-Flash架构(总计参数量为284B,实际运行时激活的参数数量为13B)开发而成,并提出了一种新的多模态推理方式。研究指出当前市面上的许多大型多模态模型存在一个未被充分重视的问题:“指代鸿沟”(Reference Gap),即尽管这些模型能够识别图像中的内容,但在用自然语

最近,DeepSeek 在 Github 上发布了新的多模态模型,并公布了相关技术报告。技术报告中指出,虽然多模态大语言模型取得了显著进步,但目前主流的思维链范式仍主要局限于语言学领域。最近的研究重点在于利用高分辨率裁剪技术来解决感知鸿沟问题,但却忽略了参照鸿沟这一核心障碍。自然语言本身的模糊性难以提供精确的空间指引,导致在需要严谨参照的任务中出现逻辑崩溃。DeepSeek 在其多模态技术报告中提

新智元报道该项目展示了如何使用多模态生成模型创建一个虚拟世界,从零开始构建了一个可以自主运行的AI角色系统。开发者利用六步地图生成流程和角色立绘抠图技术,建立了一个包含全景地图、功能区定位、可交互元素定位以及可行走区域标注的完整管道。项目中还包括决策波、对话调度、动作执行及微反思等机制,以确保每个Tick内所有AI角色的行为都经过精心设计和模拟。每个AI角色都配备了三层记忆系统来记录其经历,并根据

在具身智能领域,研究者们正面临视觉仿真算力瓶颈的挑战。为了应对这一难题,新一代的GS-Playground通用多模态仿真框架应运而生,它突破了传统平台的限制,实现了高吞吐量并行物理仿真的创新。 听雨 2026-05-01 14:28:46

2026年4月21日至22日,“奔赴AGI 重塑未来”为主题的中国生成式AI大会(北京站)圆满落幕。大会汇聚了73位来自学界、业界及投资界的嘉宾,通过一场开幕式和多场专题论坛与技术研讨会的形式,全面解析了AI产业的脉络、创新模式以及Token经济等议题,并探讨了在中国市场的机会。会议内容广泛涵盖了大语言模型、多模态模型、世界模型、智能体到AI眼镜等一系列前沿技术和应用,同时也涉及数据处理、芯片设计

机器之心编辑部随着五一假期的到来,DeepSeek 最新发布了一项技术进展。前一天,陈小康在 X 平台上的一则消息引发了公众对 DeepSeek 多模态功能的关注。一些用户已经能够在 DeepSeek 的网站和应用程序中体验其多模态特性。刚刚,DeepSeek 在 Github 上正式发布了他们的多模态模型,并公开了技术报告。这是一个全新的推理范式,具有开创性的意义。欢迎访问项目主页:https:

近日,DeepSeek发布了多模态技术报告《视觉原语思考》(Thinking with Visaul Primitives),详细披露了其新推出的识图模式背后的创新机制。该识图模式采用了名为DeepSeek-V4-Flash的基座模型,参数量达到284B,并拥有13B激活多模态推理模型。这一模型尚未正式命名,但DeepSeek已经确认未来会将其整合进基础模型中进行发布。据介绍,传统的思维链主要在语
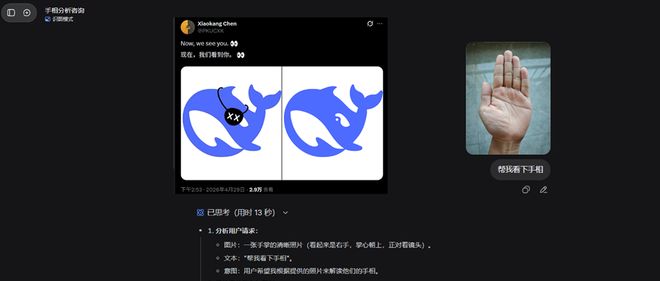
陈骏达和云鹏共同编辑了这篇关于DeepSeek多模态能力的文章。据报道,DeepSeek的全新视觉识别功能正在灰度测试阶段。被选中的用户可以发现,在DeepSeek的应用首页上新增了一个“识图模式”的选项。通过上传图片,系统能够像人类一样理解各种物体和场景。DeepSeek的研究团队第一时间分享了这一创新成果。其中一位研究员陈德里表示,“天才多模态同事们”使得小鲸鱼具备了观察世界的独特能力。我们也

新智元报道生数科技的MotuBrain在两个重要榜单中拔得头筹,标志着公司在机器人智能领域取得了重大进展。此成就建立在其前身Motus的基础上,并大幅提升了跨任务泛化能力和多模态数据处理能力。通过引入先进的UniDiffuser架构和MoT技术框架,生数科技实现了视频、动作等连续模态的一体化建模,使得模型在训练过程中能够同时掌握多种关键技能。这不仅扩大了学习的数据来源范围,还提升了模型对复杂任务的
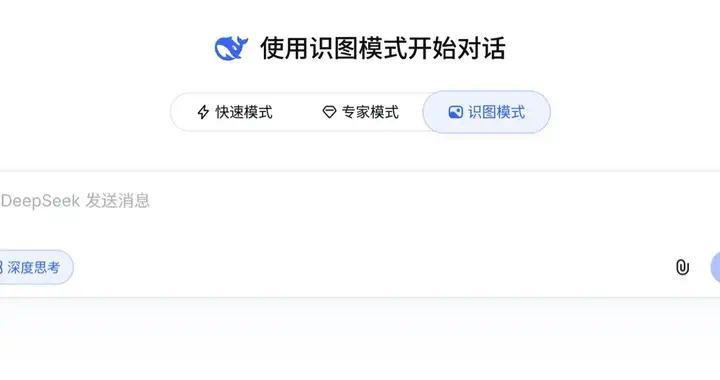
4月29日,有用户向IT之家反馈称DeepSeek正在进行一项名为“识图模式”的灰度测试,该功能与现有的“快速模式”和“专家模式”并列,并且不再局限于简单的OCR文字识别技术,而是具备了多模态识别的能力。今日有网友分享了一张图片显示,使用灰度测试的用户可以通过上传一张图片让DeepSeek进行描述。一些体验过的网友表示其速度与Flash相似,非常快。另一位网友则尝试触发识图模式界面却未能成功,收到

原本以为DeepSeek的AI更新已经告一段落了,没想到该公司竟然在上周刚推出V4版本之后,又带来了更大的惊喜。今天上午,DeepSeek推出了识图模式,并且正在进行灰度测试。这表明备受期待已久的多模态功能终于要面世了!目前,使用网页版或App更新后的用户有可能被随机选中参与这项测试,APPSO也第一时间进行了体验。DeepSeek的多模态研究员陈小康在社交平台上发文称:“Now, we see

DeepSeek的「鲸鱼」标志已正式揭开了神秘面纱。陈小康,一位专注于多模态技术的研究员,在X平台上发布了一条动态:“Now, we see you。”在该帖子中,DeepSeek的标志性鲸鱼图案被去除了眼罩装饰。不久之后,用户们发现DeepSeek网站上悄然推出了“识图模式”功能。这一新模式允许用户上传图片,并由模型进行内容识别和分析。不过,这项服务目前仅对部分用户开放测试,尚未全面推广。实际上

机器之心编辑部每当人们逐渐熟悉某种玩法之际,新的创意又紧随而来。最近,一股热潮席卷全网,那就是 OpenAI 推出的 GPT Image 2,它不仅擅长生成美观图片,还引领了「信息图生成」的新潮流。从知识卡片到数据图表,再到攻略长图和科普海报,只需一句话就能产出一张布局精美的信息清晰、质感出色的图像,其迅速走红的速度堪比当年吉卜力风格的风靡。然而,国内用户若想体验 GPT Image 2,则会遇到
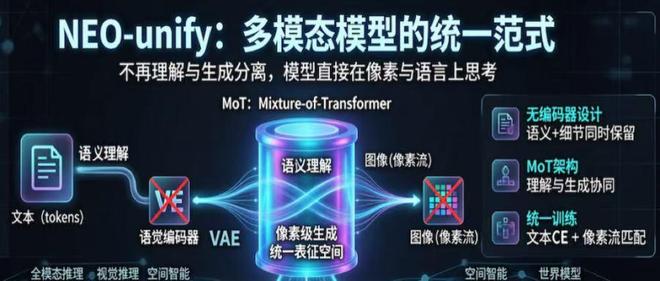
智东西团队近期推出了一篇关于GPT images 2.0的文章,引发了人们对多模态模型的新一轮关注。过去,“画得好”不再是唯一的追求标准,人们现在更加注重“速度快、效率高、成本低”的特性。很长时间以来,视觉理解和图像生成被区分为两个独立的系统:前者负责识别图像内容,后者则专注于根据需求创作新图。这种分离式的结构限制了模型的整体性能。商汤科技最近采取了一种新的策略来应对这一挑战。他们刚刚发布了名为S

西风 发自 凹非寺量子位 | 公众号 QbitAI五一假期即将来临,你是否已经开始在工作群中看到有人提前发出“假期在线”的信息了呢?这种现象背后反映出员工对于节假日工作的无奈:是带着电脑出门还是不带?这个问题让不少职场人士感到头疼。而这次我决定尝试一种新的方法,那就是安装一款名为DuMate的AI助手,看看它能否帮我处理一些假期可能遇到的工作任务。据了解,这款软件具备多模态理解和生成能力,能够应对

隐藏在幕后的「欢乐马」终于揭开了它的面纱。4月27日,阿里ATH团队发布了视频生成模型HappyHorse 1.0的首个版本。这款模型基于原生多模态架构设计,不仅能同时处理音视频内容,还能实现创作和编辑的一站式服务,免去了繁琐的操作过程。此前它在知名AI评测平台Artificial Analysis上的表现备受关注,无论是文字生成视频还是图像转换成视频,均获得了第一名的佳绩,使Seedance 2

4月23日,北京举办了备受瞩目的华为乾崑技术大会,会议的核心主题聚焦于“安全”。在此次大会上,一系列创新的技术和解决方案相继发布,其中包括新一代ADS 5系统、配备AI多模态感知功能的鸿蒙座舱HarmonySpace 6、双17.2英寸的蝶羽双联屏显示设备以及LCoS双焦面AR-HUD。在新的ADS 5架构中,“博弈论”被用于训练人工智能,这一变革极大地提高了系统的安全冗余度。通过模拟复杂的驾驶场
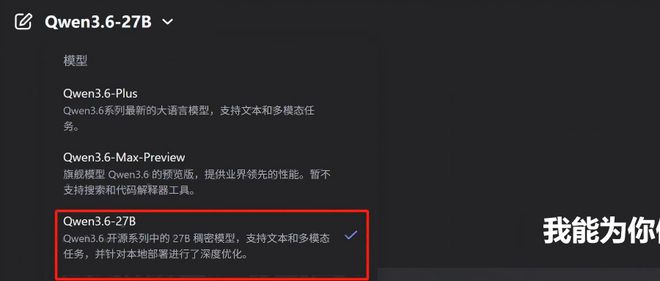
智东西编译 杨京丽编辑 陈骏达近日,阿里通义千问团队发布了Qwen3.6-27B的开源版本——这是一个具有270亿参数的大规模稠密多模态模型,并支持思考与非思考模式。相较于先前推出的Qwen3.5-397B-A17B,新的Qwen3.6-27B虽然在参数量上仅为前者的十分之一,却在编程性能等多个关键指标上实现了超越。其不仅显著提升了编程能力,在文本和多模态推理方面也表现出色。与同级别的Ge

最近,商汤科技联合创始人兼首席科学家林达华教授荣获了第四届中银香港科技创新奖(人工智能及机器人领域),以表彰他在科研创新和成果转化方面的杰出贡献。林达华教授在计算机视觉与多模态智能领域的系统性创新,在图像视频理解、大规模多模态模型以及空间智能等方面取得了许多突破,促进了关键核心技术的自主创新与开源生态建设,并推动了人工智能研究成果的应用,为中国的人工智能技术进步和产业升级作出了重要贡献。林达华教授

在医学图像分割领域,一款国产多模态代理程序取得了显著成就。 一水 2026-04-22 15:17:04 量子位 这项成果已被CV