
机器之心编辑部
每当人们逐渐熟悉某种玩法之际,新的创意又紧随而来。
最近,一股热潮席卷全网,那就是 OpenAI 推出的 GPT Image 2,它不仅擅长生成美观图片,还引领了「信息图生成」的新潮流。从知识卡片到数据图表,再到攻略长图和科普海报,只需一句话就能产出一张布局精美的信息清晰、质感出色的图像,其迅速走红的速度堪比当年吉卜力风格的风靡。
然而,国内用户若想体验 GPT Image 2,则会遇到一定门槛。那么有没有一种更加简单且适合国人的选择呢?
好巧,还真有。
最近我们发现了一款国产开源模型——商汤的日日新 SenseNova U1 系列原生理解生成统一模型,它正好满足了这一需求。
这个模型能够处理那些超大规模模型的操作,并且以前需要大量脑力和时间才能完成的任务,现在仅需简单描述要求即可自动整理信息、设计版式并呈现视觉效果,输出成品图非常专业。
此外,它完全开源并且不限制使用次数。
就像这样:

SenseNova U1 不仅仅会「绘图」,还采用了 NEO-unify 理解生成统一的新架构,能够真正实现语言和图像信息的协同处理。这使得它只需 8B 的小参数量就能达到许多商业闭源模型的效果,并且效率极高。
它的独特之处在于将视觉信息直接融入思考链路中,从而开创了连续性图文创作输出的模式。
需要指出的是,商汤这次开源的产品是 SenseNova U1 的轻量版系列 SenseNova U1 Lite,包括 SenseNova-U1-8B-MoT 和 SenseNova-U1-A3B-MoT 两个版本。
- GitHub 地址:https://github.com/OpenSenseNova/SenseNova-U1
- Hugging Face 地址:https://huggingface.co/collections/sensenova/sensenova-u1
尽管模型规模较小,但它在多个评估维度上的性能依然领先。
在图像理解和生成基准测试中,SenseNova-U1-8B-MoT 表现尤为出色。虽然参数量仅为 8B 级别,但在通用理解、空间理解等多项测试中的成绩均优于 Qwen3VL-30B-A3B 和 Gemma4-26B-A4B 这样的大规模模型。简单来说,SenseNova-U1-8B-MoT 并非靠堆砌参数取胜,而是在较小体量下实现了高效的多模态理解能力。
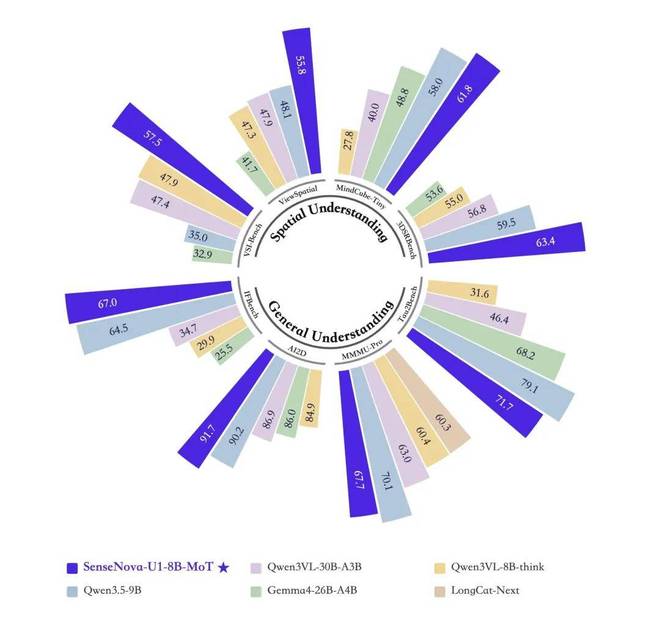
在图像生成基准测试中,SenseNova U1 Lite 的信息图生成(Infographics)分数达到 39.8 分,领先于 Qwen-Image 等模型。这表明在处理复杂高密度信息转化为图表时,该模型具备卓越的逻辑重组能力。
在文字渲染这一维度下,SenseNova U1 Lite 的成绩几乎全面领先。它能快速准确地将文本转换成高质量图像。
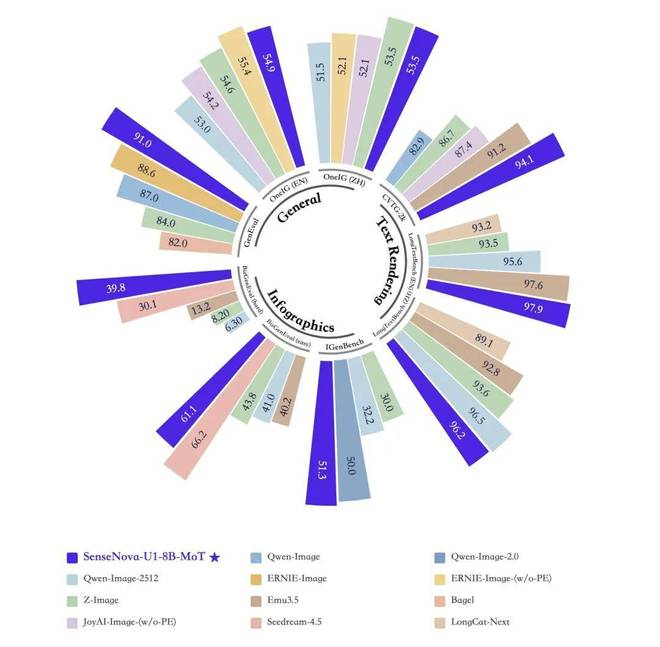
这意味着 SenseNova-U1-8B-MoT 不仅速度更快,在低延迟条件下也保持了较高生成质量,非常适合实际生产环境中的应用需求。
Generation Latency vs. Averaging Performance on Infographic Benchmarks, i.e., BizGenEval (Easy, Hard), and IGenBench
Generation Latency vs. Averaging Performance on OneIG (EN, ZH), LongText (EN, ZH), BizGenEval (Easy, Hard), CVTG and IGenBench
在当前 AI 领域,开源概念已经变得稀松平常。许多所谓的「开源」只是开放权重或设置各种商业限制。
光看榜单当然不过瘾。
商汤此次选择全面开源 SenseNova-U1 系列,代码托管在 GitHub 平台,并且模型权重和完整技术报告也会同步公布于 Hugging Face 平台。
在众多多模态大模型中,商汤此次开放的不仅是一个架构上有创新、且成功实现了理解 - 生成 - 统一路线的产品,还为学术界提供了反复验证的机会,同时也为开发者社区和产业伙伴们提供了一个直接可用的基础设施。
特别是它的体积小但能量大、效率高的特点,在资源受限环境下也能发挥出强大的能力。
当整个行业都在追求 GPT Image 2 的图像生成质量时,商汤选择的是统一本身。而随着全面开源的发布,这条路径现在属于所有人共同探索和利用。
从结果可以看出,SenseNova U1 Lite 可以一边推进故事情节,一边同步生成对应场景的插图,图和文本来自同一套思维过程,逻辑连贯、风格统一。


想学习电影运镜,也可以向 SenseNova U1 Lite 提问,它会把文字解释和视觉图同步给你,并且保持人物角色的高度一致性。这比单纯的文字教程好懂得多,也比纯图示来得有逻辑。

这种带图思考的能力,正是 SenseNova U1 的原生图文理解生成能力。它能把图像与文本从底层进行融合,实现高效、连贯的思考和图文交错输出。不但效率高,也更接近人类的理解与表达模式。
我们还用 SenseNova U1 Lite 尝试了复杂高密度信息图(infographic)的生成
信息图要解决的是一个真实的表达困境:一篇论文、一份研报、一个操作流程、一个知识点,原始形态往往密度过高、结构不清,大多数人看到就想关掉。而一张好的信息图,能把同样的内容重新组织,让读者在几秒钟内抓住核心。
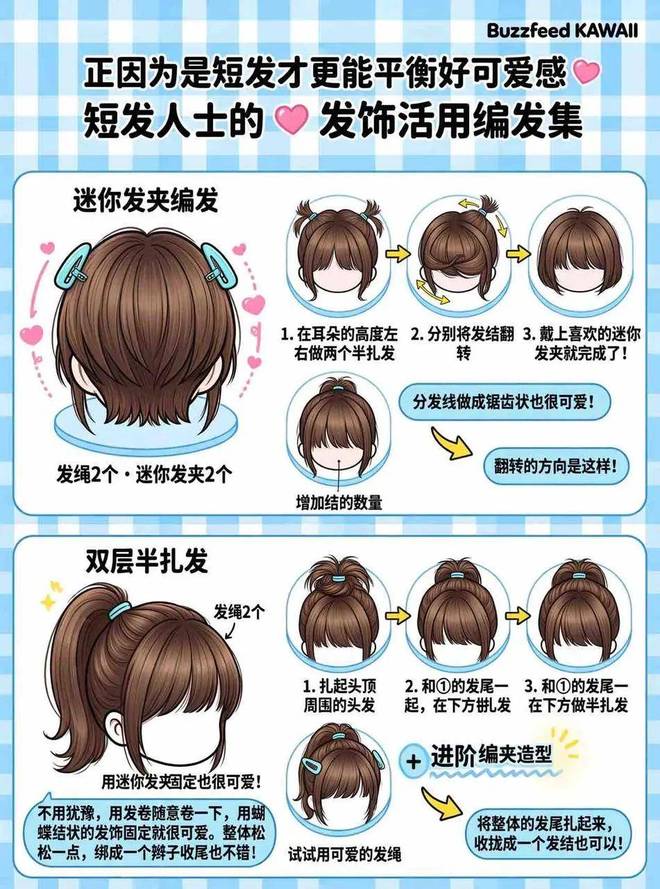
首先,我们让模型生成了一张适合可爱女生的短发造型信息图,SenseNova U1 Lite 完成度依然在线。
在接下来的案例中,SenseNova U1 Lite 生成的占星术与塔罗牌占卜图片风格华丽,充满了神秘主义元素,如果你对星座感兴趣,不放也试着做一份属于自己的星座图。

读不下去的论文,交给它。
最近,谷歌 DeepMind 发布了一篇颇受关注的论文《Image Generators are Generalist Vision Learners》,内容密度高,需要反复阅读才能理清脉络。我们把摘要丢给 SenseNova U1 Lite,让它生成一份图解。它不只是把文字重新排了一遍,而是真正提取出了论文的核心主张、方法逻辑和关键结论,用更直观的视觉结构把这些内容呈现出来,让一篇需要沉下心来读的学术文章,变得可以快速上手。
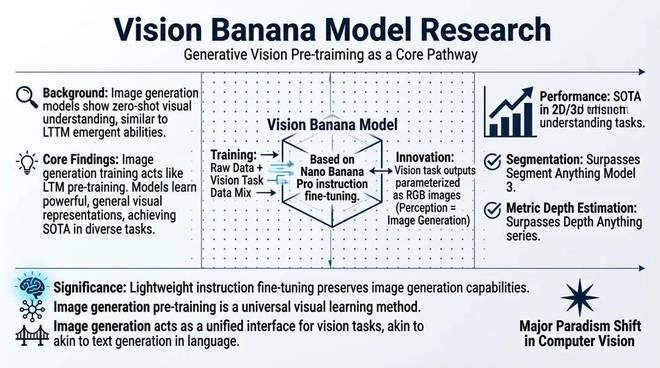
论文地址:https://arxiv.org/abs/2604.20329v1
接着,我们又换了一个完全不同的题材:让模型生成一张「武侠江湖禁忌」信息图。
这类内容看似轻松,其实很考验模型的结构化表达能力。因为它既要有江湖味,又要让读者一眼看懂规则。
SenseNova U1 Lite 的完成效果依然很有意思。它把江湖禁忌拆成了几个清晰板块:比如勿偷学武功,勿背后放冷箭暗器等。

金庸江湖生存指南:

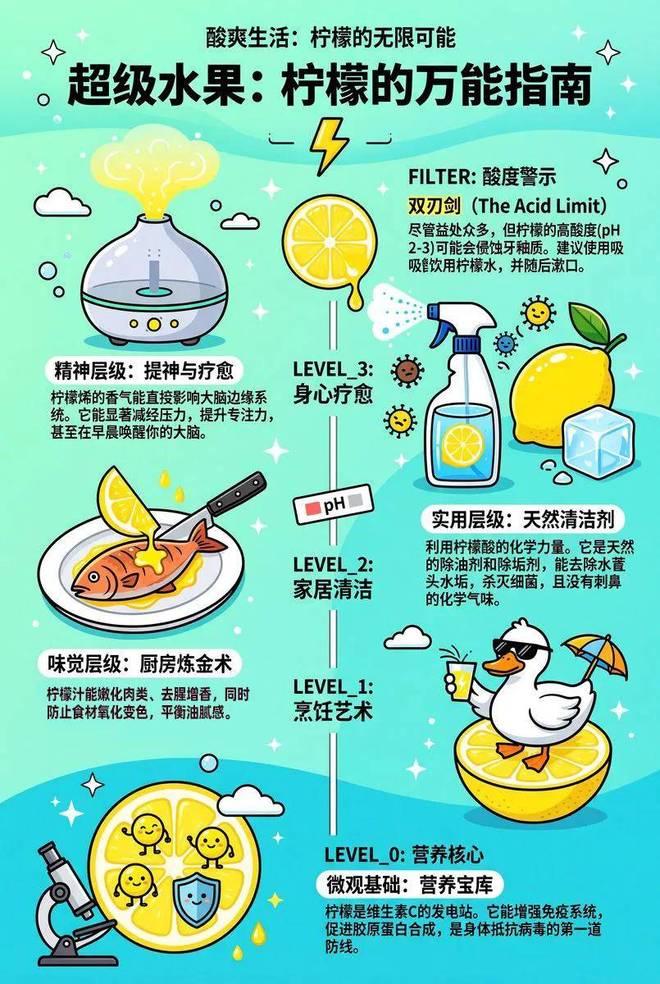
接下来,我们又让模型生成了一张「柠檬的万能指南」信息图。SenseNova U1 Lite 的处理方式比较聪明。它把柠檬的用途拆成了几个清晰模块:烹饪、家居清洁、心身疗愈。
生成詹姆斯 · 乔治 · 弗雷泽名著「金枝」(The Golden Bough)信息图:

刺绣入门指南:

城市明信片:
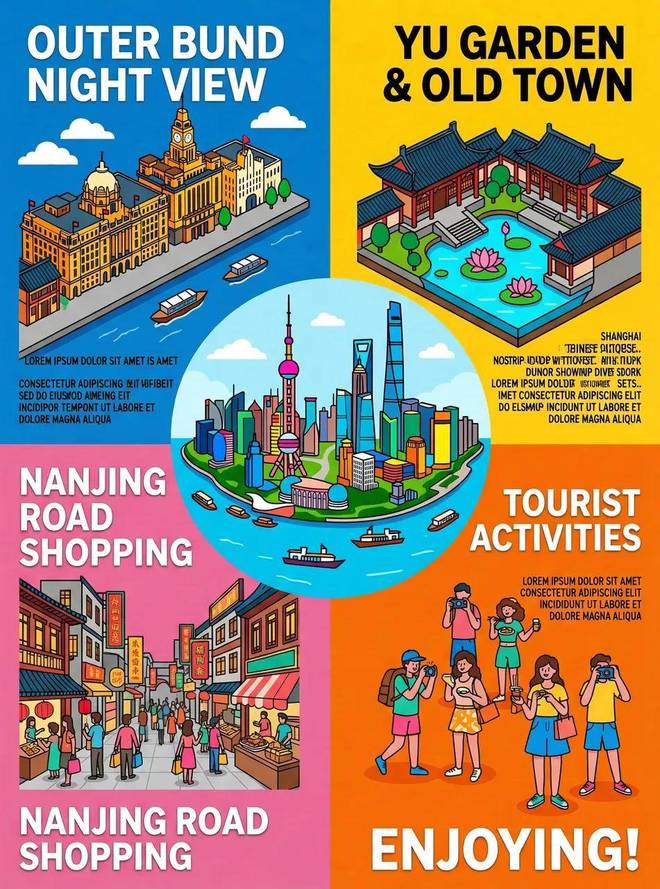
从以上结果可以看出,对于高信息密度场景,SenseNova U1 Lite 处理起来相当游刃有余。
高效统一架构,让小模型跑出大模型效果
看完这些效果,一个问题自然会浮现:它为什么能做到这些?
过去,多模态 AI 几乎被一个固定范式所统治:视觉编码器负责感知理解,把图像压缩成特征向量喂给语言模型;变分自编码器负责生成图像,把语言模型的意图解码成像素。两套系统各司其职,看似分工明确,却在理解与生成之间埋下了一道天然的断层。
问题出在压缩这个动作上。视觉编码器把图像变成特征向量,本质是一次有损的信息筛选,它预先决定了哪些视觉细节值得保留、哪些可以舍弃。而这个决定,早在模型真正开始思考之前就已经做完了。生成侧同样如此:解码器只能从语言模型的理解结果中重建图像,而不是从原始像素出发。两端都在用二手信息工作,断层由此而来。
这种路线并不是没有价值。相反,它是过去几年多模态模型快速发展的重要基础。但它的问题也很明显:每多经过一个模块,信息就多一次转换;每多一次转换,就可能带来一次损耗。尤其是图像这种信息密度很高的模态,一旦被过度压缩,细节、空间关系、局部结构都可能被弱化。到了生成阶段,模型再想把这些信息完整还原出来,就会变得更困难。
这也是为什么很多多模态模型会出现一种割裂感:它可能能说清楚图里有什么,却不一定能准确画出复杂结构;它可能能生成一张好看的图片,却不一定真正理解文字里的逻辑关系;它也可能能完成单张图生成,但一旦要求连续输出多张风格一致、逻辑连贯的图文内容,就容易出现前后不一致、细节漂移、版式混乱等问题。
SenseNova U1 Lite 的答案,是一套叫做 NEO-Unify 的原生多模态架构,解决这种理解和生成之间的断层
其思路是把这些原本分开的环节尽可能收拢到一个统一架构里。它不再把视觉和语言当成两个需要互相翻译的系统,而是让图像信息和文本信息在同一个内部空间中共同参与计算。这样一来,模型处理图文任务时,不需要在看图系统、语言系统、生成系统之间来回传递,而是可以在同一套模型内部完成感知、理解、推理和表达。
这样做带来的第一个好处,是信息路径更短。
传统架构里,模型完成一次复杂图文任务,可能要经历看图 — 理解 — 规划 — 生成 — 修正等多个阶段,而且每个阶段之间都存在对齐成本。SenseNova U1 Lite 的统一架构则更像是把这些环节压缩进同一个大脑里,让模型可以一边理解内容,一边组织画面,一边保持语义和视觉的一致性。少了中间转译,模型就能把更多计算用于真正的理解和生成,而不是消耗在模块之间的衔接上。
第二个好处,是效率更高。
通过架构上的统一,减少不必要的信息损耗和流程开销,让较小规模的模型也能释放出更高的有效能力。
这也是 SenseNova-U1-8B-MoT 值得单独拿出来看的原因。8B 级别的模型规模并不算大,但它在图像生成、图像编辑、复杂信息图、视觉推理等任务中,能够接近甚至追上部分大型商业模型。背后的关键,并不是简单小参数逆袭大模型,而是统一架构让计算利用率更高,模型不需要花太多能力去弥补模块割裂带来的损耗。
这可以通过一些实验结果来说明:
如下图所示,SenseNova-U1-8B-MoT 位于相当靠左的位置,延迟大约只有 15 秒 / 2K 图,是所有对比模型中生成速度最突出的一个。同时,它的平均得分接近 67 分,已经进入主流商业模型所在的中高分区间。
这意味着,SenseNova-U1-8B-MoT 的优势主要体现在效率上:它没有依赖更长的生成时间去换取性能,而是在低延迟条件下保持了较高的生成质量。相比一些得分更高但耗时达到 30 秒、70 秒甚至更久的商业模型,它更接近实际生产中需要的状态,快速出图、质量可用、响应稳定。
换句话说,如果只看最高分,GPT-Image-2.0、Nano Banana Pro 等模型仍然处在第一梯队;但如果把速度也纳入考量,SenseNova-U1-8B-MoT 的位置就变得非常突出。它用更短的时间完成了接近主流商业模型的生成效果,体现出很强的单位时间产出能力。
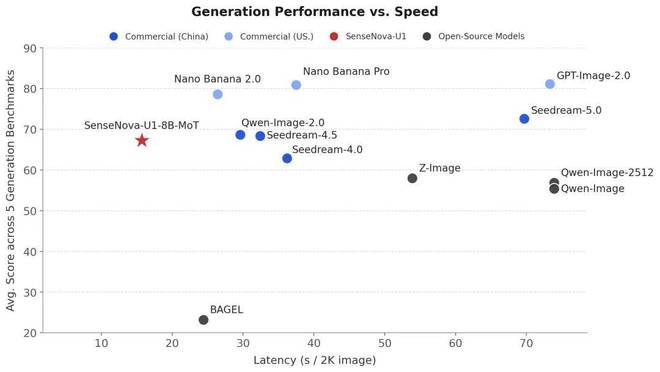
Generation Latency vs. Averaging Performance on Infographic Benchmarks, i.e., BizGenEval (Easy, Hard), and IGenBench
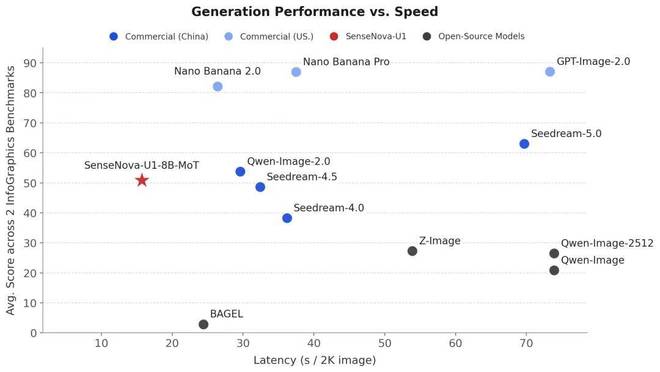
Generation Latency vs. Averaging Performance on OneIG (EN, ZH), LongText (EN, ZH), BizGenEval (Easy, Hard), CVTG and IGenBench
结语
在 AI 领域,开源两个字正在被严重稀释。有的开源只是权重开放,却不开放代码;还有的干脆设了各种商用限制,开源不过是蹭热度的说法。
商汤此次选择将两个参数模型全面开源,代码托管于 GitHub,模型权重在 Hugging Face 平台同步提供下载,完整技术报告也将在近期公布。
在当前多模态大模型格局下,开源一个在架构层面有实质创新、且跑通了理解 - 生成 - 统一路线的模型,意味着这套方法可以被学术界反复审视、被开发者社区持续打磨,同时也为产业伙伴提供了直接可用的基础设施。
尤其是它的小身材、大能量、高效率,能帮助开发者即便在资源受限的环境下,也能享受高效率的能力,发挥越级的实力。
当整个行业都在追赶 GPT Image 2 的生图质量时,商汤押注的是统一本身。而随着全面开源的放出,这条路径,现在属于所有人。