
机器之心编辑部
随着五一假期的到来,DeepSeek 最新发布了一项技术进展。
前一天,陈小康在 X 平台上的一则消息引发了公众对 DeepSeek 多模态功能的关注。
一些用户已经能够在 DeepSeek 的网站和应用程序中体验其多模态特性。
刚刚,DeepSeek 在 Github 上正式发布了他们的多模态模型,并公开了技术报告。
这是一个全新的推理范式,具有开创性的意义。

- 欢迎访问项目主页:https://github.com/deepseek-ai/Thinking-with-Visual-Primitives
- 技术详情请见文档地址:https://github.com/deepseek-ai/Thinking-with-Visual-Primitives/blob/main/Thinking_with_Visual_Primitives.pdf
接下来,我们将根据 DeepSeek 发布的技术报告,探讨他们与北京大学和清华大学合作取得的成果。
该论文题为「以视觉原语思考」。它揭示了现有多模态大型模型的一个关键问题:这些模型虽然可以识别图像中的对象,但在具体推理时却难以准确指代它们。
对于一张密集人群的照片,询问 GPT-5.4 图中有多少人,它的回答可能不精确。同样的情况也出现在给 Claude Sonnet 4.6 展示电路图并要求其指出特定部件位置的问题上——模型的回答常常含糊不清或前后矛盾。
DeepSeek 将这一问题定义为「指代鸿沟」(Reference Gap),并提出了相应的解决方案。
背景:视觉识别与精准推理之间的差距
试想一下,如果你试图通过文字描述一个复杂的棋盘布局给一个看不见屏幕的朋友听,你会发现很难准确地定位到具体的棋子位置。这就是目前多模态大模型在推理时遇到的问题。
它们使用自然语言构建「思维链」(CoT),但这种表达方式往往不够精确:模糊的语言描述无法精确定位图像中的对象。因此,在推理过程中,它们的注意力会逐渐偏离目标,最终导致错误的答案。
学术界以前的研究主要集中在如何提高模型对图片细节的感知能力上——例如通过高分辨率切割和动态分块来提升其视觉解析度。
然而 DeepSeek 的论文指出,仅仅增强视觉感知力是不够的;准确的「指代」能力同样不可或缺。也就是说,能够清晰地描述图像中的对象与能精确指向这些对象是两个不同的概念。
架构:基于 V4-Flash 模型
该工作以 DeepSeek 最新发布的 V4-Flash 语言模型为基础——这是一个拥有284B总参数、推理时激活13B参数的混合专家模型(MoE)。视觉编码部分使用的是 DeepSeek 自研的 ViT(视觉 Transformer),支持任意分辨率输入。
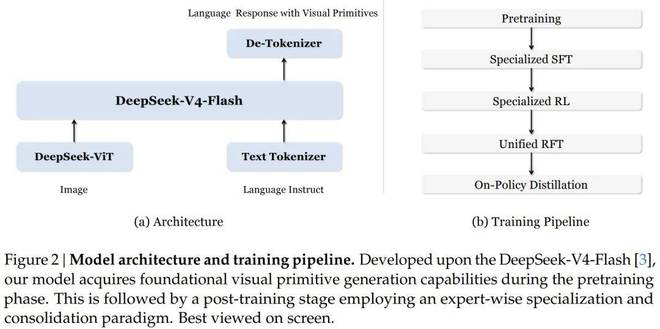
比较特别的一点是,该团队提出了一套完整的训练方法:如何用极少数量的视觉 token 来教授模型在推理过程中准确指代视觉对象的能力。
核心创新一:坐标作为思考单元
这篇论文的核心理念可以概括为:将边界框和点坐标作为推理的基本单位,像处理文字一样处理它们。
在传统方法中,边界框通常是在模型完成初步推理后生成的输出结果。DeepSeek 的新方法则不同——它使模型在推理过程中实时生成这些坐标信息:
「扫描图片寻找熊,发现一只 <|ref|> 熊 <|/ref|><|box|>[[450, 780], [690, 1010]]<|box_end|>;另一只在角落里。」
这种实时生成坐标的方式有助于模型更好地定位图像中的对象,从而减少推理时的误差。
核心创新二:强化学习训练流程
训练阶段,团队采取了「先专家化后统一」的方法:
首先是利用边界框数据和点坐标数据分别训练两个专家模型(FTwG 和 FTwP),以避免两种模态在初期数据量较少时互相干扰。
接下来是对这两个专家模型进行强化学习调优,使用 GRPO 算法。奖励设计非常细致:格式正确性、质量一致性以及任务特定精度三方面并行给予反馈。
第三是将两个专家模型的 rollout 数据合并用于统一的强化微调(Unified RFT),之后从预训练模型重新初始化开始训练,得到一个统一模型 F。
最后一步则是通过 On-Policy Distillation 方法缩小统一模型与专家模型之间的性能差距——允许学生模型自行生成轨迹,并最小化其输出分布和专家模型的差异。
实验结果:在复杂推理任务上超越其他顶级模型
该论文在11个基准测试中进行了评测,与 Gemini-3-Flash、GPT-5.4、Claude Sonnet 4.6 等主流多模态大型模型进行比较。
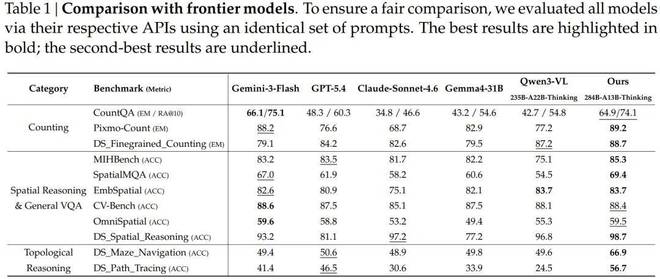
在计数任务上,该模型在 Pixmo-Count(精确匹配)上的得分达到了89.2%,高于 Gemini-3-Flash 的88.2%和 GPT-5.4 的76.6%。同时,在细粒度计数任务 DS_Finegrained_Counting 上也超过了 Qwen3-VL,得分为88.7%。
在空间推理的多个基准上,该模型的表现与头部模型持平或有所超越,如在 MIHBench(85.3%)和 SpatialMQA(69.4%)任务中均排名第一。
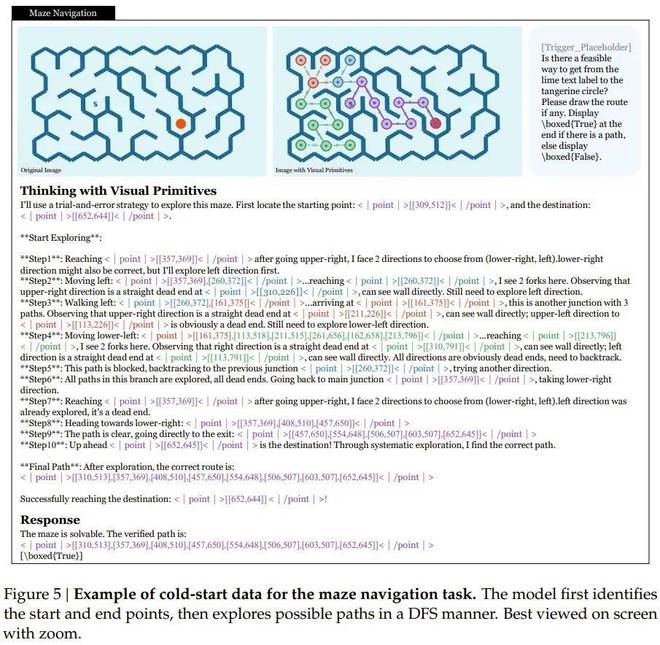
最大差距体现在拓扑推理任务上。例如,在迷宫导航 (DS_Maze_Navigation) 和路径追踪 (DS_Path_Tracing) 这两个具有挑战性的测试项目中,该模型分别以 66.9% 和 56.7% 的得分领先于其他竞争对手。
论文指出:「所有前沿多模态大型模型在拓扑推理任务上的表现仍然有待提高。」

结论:一种新的思考方式

这篇论文的贡献不仅仅在于技术进步,更重要的是它提出了一个新视角——即视觉指代是多模态模型能力提升的关键。
以往的研究往往侧重于更大的模型、更高的分辨率和更多的训练数据。而这篇论文则提供了一条新的路径:通过精准坐标系统来改善推理过程中的语言描述问题。
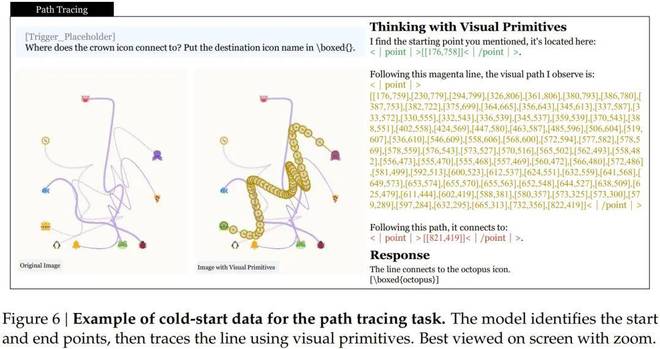
「Thinking with Visual Primitives」引入了人类处理复杂视觉任务时自然使用的「思考姿势」——即用手指指明目标的方式,这在过去的人工智能模型中是缺失的。
如需了解更多详情,请参考原论文。
第一步,用边界框数据和点坐标数据分别训练两个专家模型(FTwG 和 FTwP),避免两种模态在数据量较少时互相干扰。
第二步,对两个专家模型各自进行强化学习(RL),使用 GRPO 算法。奖励设计非常精细:格式奖励(输出格式是否正确)、质量奖励(LLM 评判思考内容和答案是否一致)、精度奖励(任务特定)三路并行。计数任务使用平滑指数衰减奖励而非二值对错,迷宫任务的奖励分解为五个子项(因果探索进度、探索完整性、穿墙惩罚、路径有效性、答案正确性),都是为了给模型提供密集而信息丰富的学习信号。
第三步,用两个专家模型的 rollout 数据进行统一的强化微调(Unified RFT),再从预训练模型重新初始化开始训练,得到统一模型 F。
第四步,用 On-Policy Distillation(在线策略蒸馏)弥合统一模型与专家模型之间的性能差距 —— 让学生模型自己生成轨迹,然后最小化其输出分布与专家分布之间的 KL 散度。
实验结果:在「最难的那类题」上超越 GPT-5.4
论文在 11 个基准测试上进行了评测,与 Gemini-3-Flash、GPT-5.4、Claude Sonnet 4.6、Gemma4-31B、Qwen3-VL-235B 等主流模型对比(所有 frontier 模型均通过 API 评测,使用统一提示词)。
结果概要如下:
- 在计数任务上,该模型在 Pixmo-Count(精确匹配)上得分 89.2%,超过 Gemini-3-Flash 的 88.2%,大幅领先 GPT-5.4 的 76.6% 和 Claude Sonnet 4.6 的 68.7%。在细粒度计数上(DS_Finegrained_Counting),以 88.7% 超过 Qwen3-VL 的 87.2%,位居第一。
- 在空间推理的多个基准上,整体表现与头部模型持平或略有超越,在 MIHBench(85.3%)和 SpatialMQA(69.4%)上均排名第一。
- 最具代表性的差距出现在拓扑推理任务上。在迷宫导航(DS_Maze_Navigation)上,该模型得分 66.9%,而 GPT-5.4 为 50.6%、Gemini-3-Flash 为 49.4%、Claude Sonnet 4.6 为 48.9%—— 所有 frontier 模型都只能答对一半,而这个模型提升了约 17 个百分点。在路径追踪(DS_Path_Tracing)上,该模型 56.7% vs. GPT-5.4 的 46.5%、Gemini-3-Flash 的 41.4%,差距同样悬殊。
论文诚实地指出:「所有 frontier 模型在拓扑推理任务上均表现欠佳,说明多模态大模型的推理能力仍有相当大的提升空间。」
下面展示了几个定性示例:



局限与未来
论文没有回避几个已知的局限性。
- 当前模型需要明确的「触发词」才会启用视觉原语机制 —— 它还不能自主判断什么时候该「用手指」。
- 受输入分辨率限制,在极细粒度的视觉场景中,视觉原语的位置偶尔会不够精准。团队认为与现有高分辨率感知方案的结合是自然的下一步。
- 用点坐标解决复杂拓扑推理问题,目前的跨场景泛化能力仍然有限。
结语:一种新的「思考姿势」
这篇论文的意义,不只是在几个榜单上拿了第一。
它提出的问题 ——「推理过程中语言指代的歧义性是多模态模型的根本瓶颈之一」—— 在此之前并不是学界的主流叙事。
主流的努力方向是更大的模型、更高的分辨率、更多的训练数据。这篇论文给出了另一条路:不是让模型「看更多」,而是让模型「指更准」,用坐标代替语言描述,用空间锚点稳定逻辑链。
从这个角度看,「Thinking with Visual Primitives」更像是在给多模态推理增添一种「思考姿势」—— 一种人类在处理复杂视觉任务时本能就会使用、但 AI 此前一直缺失的姿势:用手指点着想。
更多详情请参阅原论文。