 陈骏达和云鹏共同编辑了这篇关于DeepSeek多模态能力的文章。
陈骏达和云鹏共同编辑了这篇关于DeepSeek多模态能力的文章。
据报道,DeepSeek的全新视觉识别功能正在灰度测试阶段。被选中的用户可以发现,在DeepSeek的应用首页上新增了一个“识图模式”的选项。通过上传图片,系统能够像人类一样理解各种物体和场景。
DeepSeek的研究团队第一时间分享了这一创新成果。其中一位研究员陈德里表示,“天才多模态同事们”使得小鲸鱼具备了观察世界的独特能力。
我们也有幸参与此次测试,并进行了初步体验。
在基本识别功能的测试中,我们上传了一张兔子的照片,DeepSeek能够准确判断出兔子品种并描述其姿态特征。
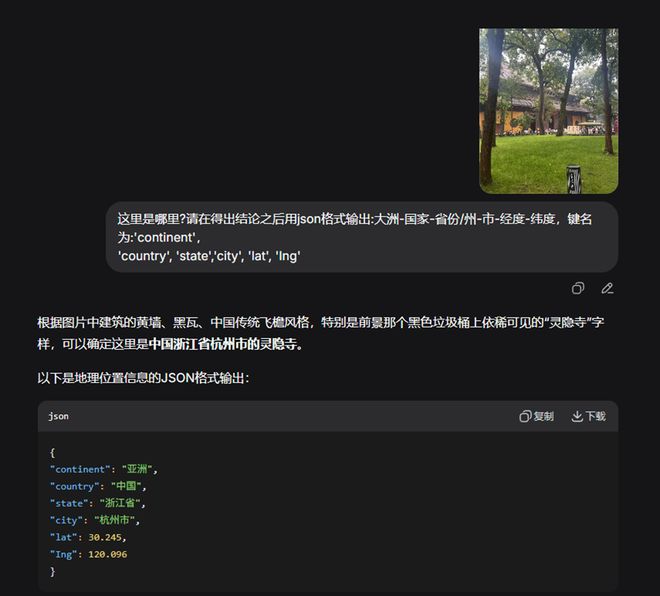
接下来是一次更具挑战性的测试。我们提供了一张灵隐寺的照片,照片中的右下角有“灵隐寺”三个草书字,尽管这对普通人来说有些难以辨认。然而,DeepSeek根据建筑风格和文字信息迅速判断出这是杭州的著名景点,并给出了精确的城市坐标。

我们还尝试了包含视觉陷阱的图片测试,其中物品摆放方式可能让人误以为图中有人坐在椅子上。

DeepSeek成功避免了这种误导,准确识别出了墙面修补痕迹、垃圾收集区域和杂物等细节信息。
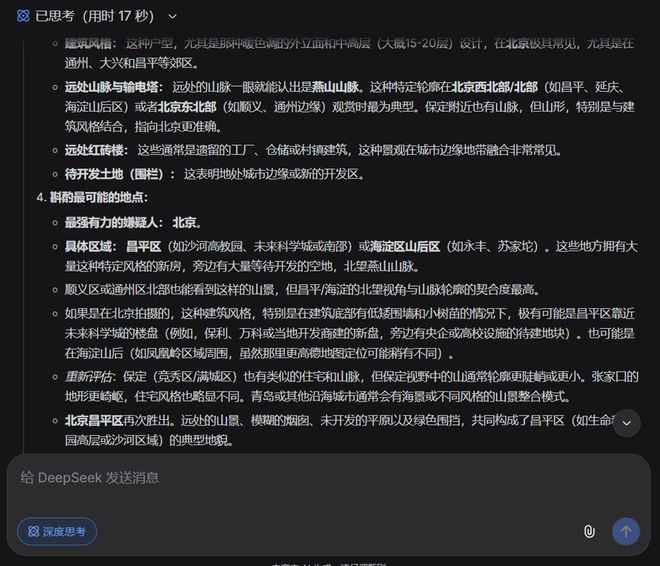
在开启深度思考模式后,我们上传了一张没有文字参考的照片。DeepSeek通过细致的分析判断出这可能是北京昌平地区或者海淀山后的某个地方,甚至某些推测距离我们的实际位置不到10公里。

我们还尝试了手相识别功能,尽管初次上传时出现了左右手混淆的情况,在后续分析中DeepSeek对手相特征描述得相当详细且合乎事实。

总结来看,这次测试表明,随着多模态能力的完善,DeepSeek已经能够更接近人类感知世界的方式。虽然识图模式目前还处于灰度测试阶段,但它已经在视觉解析和跨模态推理方面展现出了巨大的潜力。

在过去一段时间里,DeepSeek一直致力于研究和开发多模态技术,并曾发布过开源的Janus模型等成果。然而,在实际产品应用中并未正式提供这种能力给公众使用。
随着人工智能向多模态发展的趋势日益明显,这一领域蕴藏的信息量能够进一步扩展AI对世界的认知范围,更加贴近人类理解世界的方式。

我们还尝试了热门的看手相玩法,上传后,DeepSeek第一眼先把左右手看错了,我们上传的图片是左手,它判断成了右手。
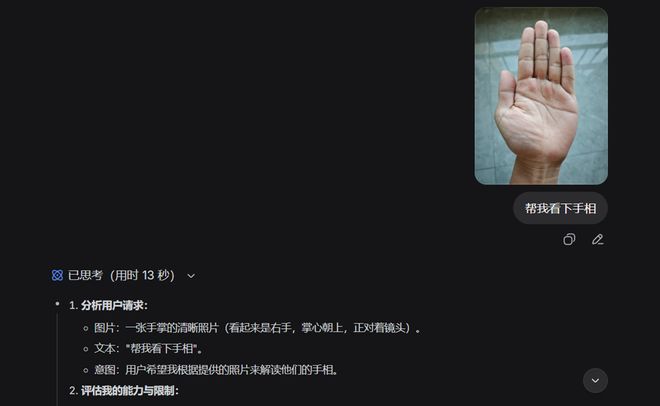
进入实际分析后,DeepSeek对手相形态的描述基本符合事实,分析得也是头头是道,不过具体该相信多少,这就见仁见智了。

结语:DeepSeek多模态拼图,终于补齐
在过去很长一段时间里,DeepSeek多模态能力的缺失一直是一个遗憾。DeepSeek一直维持着多模态的相关研究,并曾在早期发布开源多模态模型Janus等成果。不过,DeepSeek一直未在其产品中向公众提供多模态能力。
AI走向多模态已经成为不可逆转的大趋势。多模态内容所蕴藏的丰富信息可以扩展AI认知这一世界的触角,也更贴近人类本身理解世界的方式。目前,DeepSeek的识图模式还只是一个测试功能,不过它已经让我们看到了其在视觉解析与跨模态推理上的潜力。