 智东西团队近期推出了一篇关于GPT images 2.0的文章,引发了人们对多模态模型的新一轮关注。
智东西团队近期推出了一篇关于GPT images 2.0的文章,引发了人们对多模态模型的新一轮关注。
过去,“画得好”不再是唯一的追求标准,人们现在更加注重“速度快、效率高、成本低”的特性。
很长时间以来,视觉理解和图像生成被区分为两个独立的系统:前者负责识别图像内容,后者则专注于根据需求创作新图。这种分离式的结构限制了模型的整体性能。
商汤科技最近采取了一种新的策略来应对这一挑战。
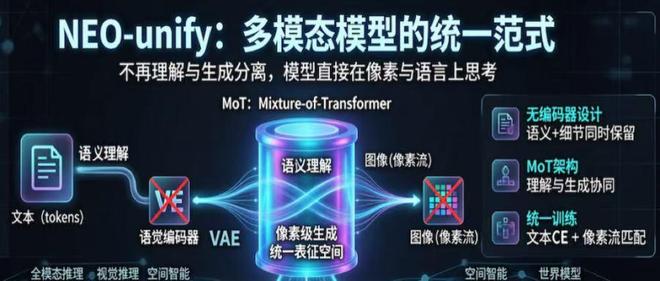
他们刚刚发布了名为SenseNova U1的原生理解生成一体化模型,并借助自主研发的NEO-unify架构,整合图像和文本的理解与生成功能,从而去除了中间环节,大幅提高了效率。
在多项基准测试中,SenseNova U1 Lite版本展现了卓越性能,在同级别的开源模型中达到行业领先水平,并在多个指标上接近商业闭源模型的表现。以8B的参数规模实现了接近更大模型的能力,彰显了“小而精”的优势。

▲高密度信息图(en)
▲高密度信息图(zh)
目前用户可以在Hugging Face和GitHub平台上获取SenseNova U1的开源代码。同时,“办公小浣熊3.0”智能工作助手也将集成这项技术,让用户直接体验其强大功能。
商汤此次发布的模型以效率取胜:在不增加参数数量的情况下达到了行业最佳水平。
SenseNova-U1-8B-MoT和SenseNova-U1-A3B-MoT是两个版本的开源代码,都基于统一的多模态架构设计,适用于图文理解、生成及复杂交互任务。
测试结果显示,SenseNova U1在多种维度上表现出色:无论是图像理解还是文本生成,都能以较小模型规模达到商业级性能。特别是在AI2D和IFBench等基准测试中取得了领先成绩,达到了91.7分的高水准。
在信息图生成任务方面,SenseNova U1的表现尤为突出,在GenEval、OneIG、LongTextBench等多个任务上展现了强大的文本一致性与复杂结构生成能力。在BizGenEval和IGenBench等标准测试中达到了50.7分的平均成绩。
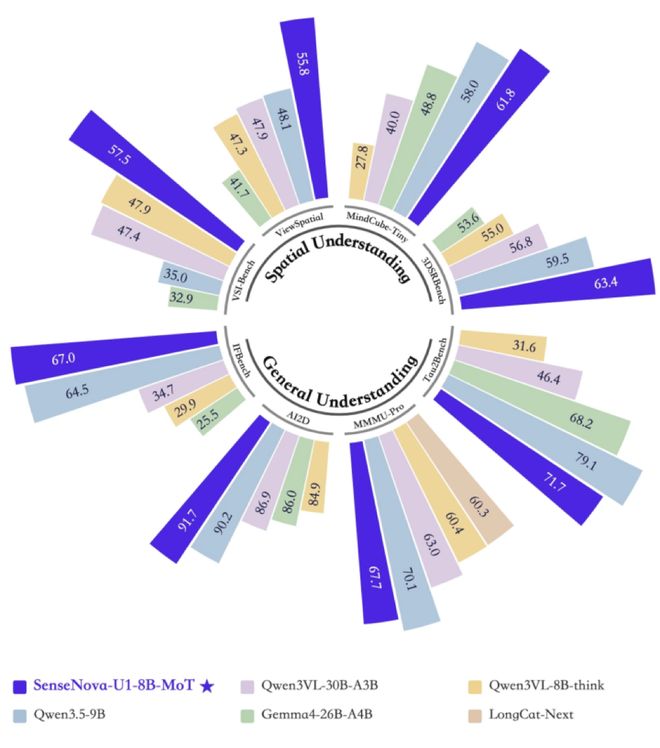
编辑能力和图文交错功能方面,SenseNova U1也在WISE、VBVR、OpenING和GEdit-Bench等多个场景下取得了显著成效,在视觉推理任务中的表现尤为出色,远超传统图像生成模型。
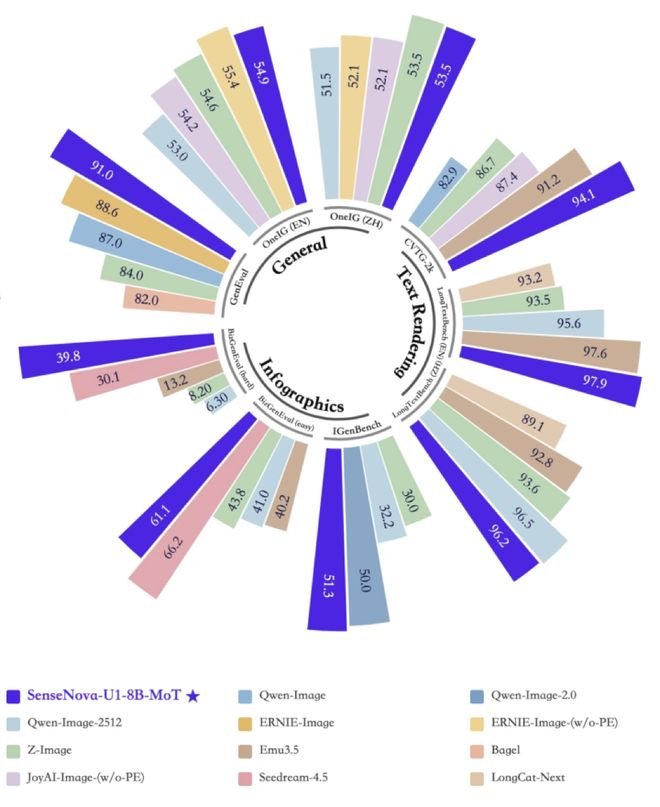
与现有商业闭源模型相比,SenseNova U1在信息图生成等关键指标上的响应时间更短,但质量上却能媲美甚至超越竞争对手。例如,在信息图生成和长文本处理方面,它能在大约15秒内完成接近60分的高质量输出。
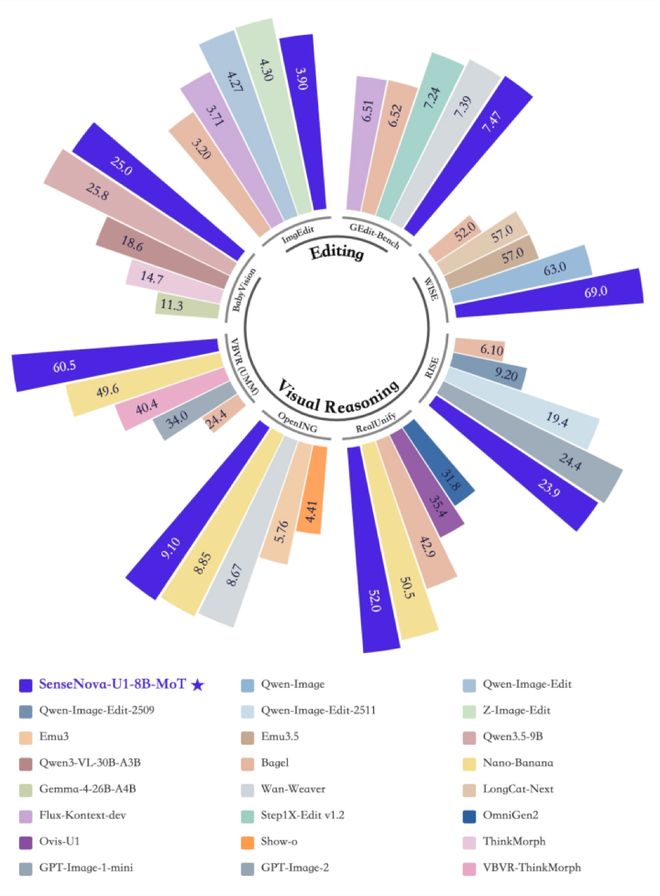
但相比这些分项成绩,更关键的是它的“性能—效率比”。
这些优势主要得益于底层架构的设计革新——SenseNova U1采用了NEO-unify原生统一架构,减少了中间环节的信息损失,并优化了数据利用效率和推理开销。
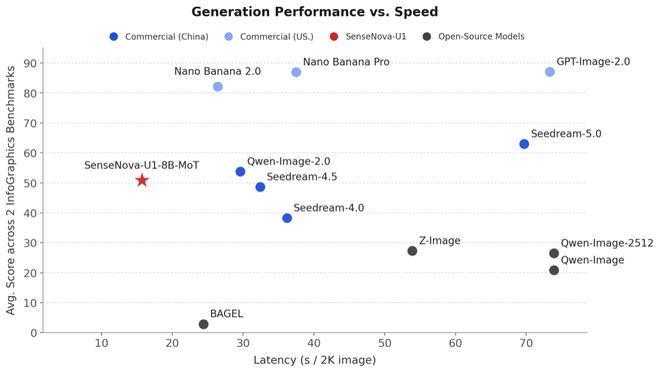
结果就是,这款模型仅凭8B的参数规模就能在多个维度上达到行业最佳水平,在某些场景下甚至可以接近商业级闭源产品的性能。
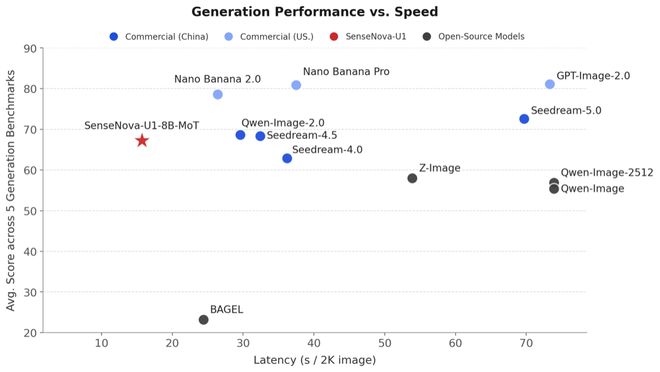
从评估结果来看,这种架构创新带来的效果已经很明显。接下来我们将通过实际应用来验证其真实表现。
我们选取了高密度信息图、趣味创意图像和流程图等多种任务进行测试,覆盖多个应用场景。
在生成信息图方面,用户只需输入文字说明或资料内容,模型就能提炼关键信息并自动生成一张具有结构化层级关系的信息图表。例如,在“苏超出圈之路”案例中,SenseNova U1成功制作了一张多层蛋糕式的信息图,层次分明,没有出现明显的错位和遮挡问题。
“龙虾使用指南”的例子展示了模型在复杂场景下处理文本细节的能力:它不仅能够正确显示关键信息,还能自动匹配相应图标和情绪化画面。
在人物与指令理解方面,“马斯克vs奥特曼”这个案例很好地证明了SenseNova U1的语义对齐能力。模型通过简单的提示词就能生成具有对比意味的形象图,并保持一致性。
对于技术流程图等复杂任务,该模型也能够提供清晰、逻辑性强的信息展示方式,适合非专业读者阅读理解。
测试中另一个明显的感受是速度优势:这类图像的生成时间大约为十几秒,实现了近乎实时的效果。
除了信息图表,SenseNova U1还可以应用于多种内容创作领域,如简历制作、产品说明和百科知识等,对于营销、办公、设计等行业来说,这将极大地提高内容生产的效率。
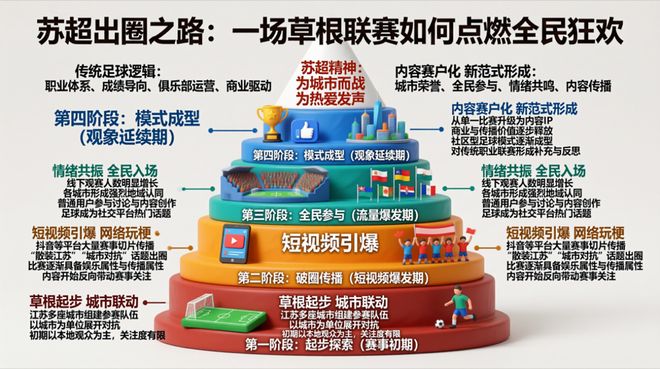
商汤科技的创新之处在于打破传统多模态模型的工作方式——不再将语言与视觉信息分割为独立处理单元,而是统一在一个框架内进行融合建模。
通过减少中间环节的信息损耗,并从原始像素和文本数据中直接学习,这种设计使得不同模态间的数据传输更加高效。
这种基于原生架构的理解与生成一体化能力,不仅提高了模型的效率,也为未来的具身智能研究提供了新的思路。

除了图像生成,SenseNova U1还能实现连续性的图文交错输出:在处理复杂任务时可以一边解释逻辑一边生成示意图或流程图。例如,在教程编写过程中,它可以保持文字叙事、插图风格和人物事件的一致性与连贯性。
这种能力源于其原生的图文理解生成机制,能够完整保留图像和文本之间的底层关联,并在统一表征空间内进行高效思考。
从长远看,这种技术路线可能会成为具身智能研究的重要基础。随着机器人在现实世界中的应用越来越广泛,如何理解和利用空间关系将变得至关重要。

总结来说,SenseNova U1通过创新的底层架构和原生多模态能力为AGI的发展铺平了一条更加高效的路径,并开启了“图文同构、思画合一”的新时代。这标志着国产大模型在全球竞赛中的硬核解法已经初步形成。
商汤科技此次全面开源不仅体现了其技术创新实力,也为行业带来了新的发展方向和机遇。随着技术的进一步渗透和发展,“图文共融”将成为未来多模态AI发展的重要趋势之一。

从结果来看,整体结构层级清晰,信息分区明确、表达直观,对于非技术读者也较为友好。
一轮实测下来,另一个比较直观的感受是速度。这类图像的生成基本都在十几秒内完成,有点接近“言出法随”的感觉。
在这样的生成效率下,各种应用场景也不在话下。目前,SenseNova U1可生成信息图谱、专业简历、生活指南、产品说明、百科知识、漫画创作等多种内容。对营销、办公、设计、商业分析等场景来说,这类能力直接对应的是内容生产效率提升。
三、告别“缝合”,NEO-unify架构如何成为理解与生成的“通才”?
测评集成绩有优势,实测效果也毫不逊色,这个原生框架究竟好在哪里,我们来拆解一下。
过去,多模态模型的工作方式更像是“分工协作”:视觉编码器负责理解图像,变分自编码器负责生成图像。前者看图,后者画图,中间再通过不同模块完成衔接。
理解与生成更像两条并行的流程,能配合,但很难真正融合,所以SenseNova U1这次选择直接推倒重建,从底层架构上直接改掉这套“拼接式”体系。
其采用的自研NEO-unify架构,不再把语言和视觉当作需要中间转换的两种信号,而是从一开始就把它们当作同一类信息来建模。
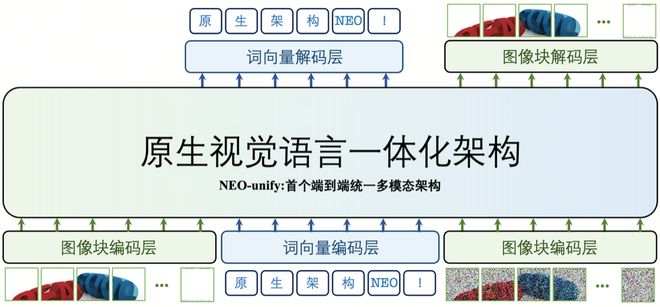
换句话说,语言与视觉不再各走各路,在同一套表征体系里共同参与理解、推理和生成。
这种设计本质上回到了“多模态AI第一性原理”:不同模态之间本来就是内在关联的。
在具体实现上,模型尽量减少中间压缩与转换环节,直接从接近原始的像素和文本信息中学习,让信息在传递过程中损耗更小。
同时,它的数据和推理效率也更高。这也是SenseNova U1值得关注的地方:并不是单纯靠堆参数规模换效果,而是在底层架构上重新处理多模态模型的协作方式。
四、当AI学会“带图思考”,展开空间智能更多想象
不同于GPT-image2单纯图像上的“卷王体质”,SenseNova U1也展示了另一种可能:让图像成为逻辑的一部分,并在推理过程中引入对空间结构的理解。
这也是其“连续性图文创作输出”的能力核心。
SenseNova U1是业内首个能够在单一模型上进行连贯图文交错生成的模型。这意味着,在处理复杂任务时,模型可以一边解释逻辑,一边生成对应的示意图、流程图、草图或设计图。
例如在教程、在绘本故事等场景中,它可以让文字叙事、插图风格、人物事件等保持一致性与连贯。
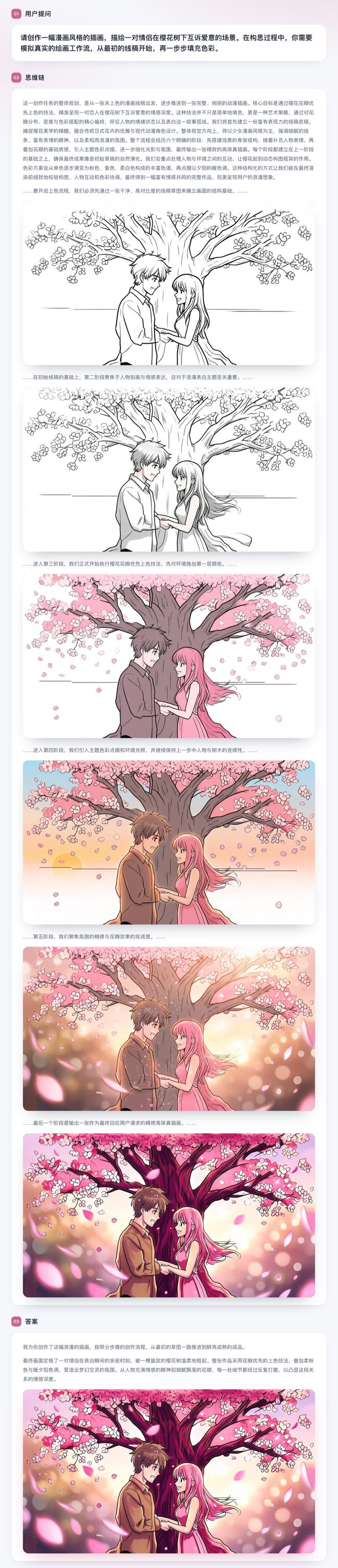
同时,SenseNova-U1并不是先生成一段完整文字,再去“补图”,而是从材料准备或构图草稿开始,一步步输出关键操作,并同步生成对应画面。
整个生成过程是连续的:步骤之间有承接关系,图像之间保持风格一致,文字和视觉内容也始终围绕同一上下文展开。这种连贯性,在过去依赖多模型串联的方案中很难稳定实现,往往会出现风格漂移或信息断裂。
本质上,这得益于SenseNova U1所具备的原生图文理解生成能力,能天然将图像和文本底层融合信号完整的保留上下文中,在统一表征空间进行高效连贯思考。
这也让它和空间智能产生了更直接的联系。空间智能关注的是模型如何理解位置、方向、布局、关系和结构,而这些能力恰恰会在图像生成、高密度信息图排版、流程图构建和场景示意中反复出现。
如果继续往后看,这类能力也可能成为具身智能的重要基础。机器人要在真实环境中完成任务,不仅要“看见”物体,还要理解物体之间的关系、判断行动路径,并根据任务目标做出连续决策。
从这个角度看,SenseNova U1的意义不只是生成更好看的图,而是在单一模型中尝试打通理解、推理和视觉表达。它距离真正成为机器人的“具身大脑”还有距离,但这类统一架构,至少提供了一条更接近多模态闭环的技术路径。
结语:理解与生成走向统一,多模态模型进入分岔口
从底层架构的NEO-unify创新,到应用层面的原生图文交错与高密度信息图生成,商汤的全面开源,不仅是参数规模上的“以小搏大”,更是对多模态第一性原理的深度回归。
当行业还在讨论生图模型的真实边界时,SenseNova U1已经通过理解与生成的统一,为AGI的到来铺就了一条更具效率的路径。
开源的力量将让这种原生多模态能力迅速渗透进每一个垂直行业,我们正在见证的是一个“图文同构、思画合一”的全新时代的开启。
在大模型全球竞赛的下半场,国产模型正在输出属于自己的硬核解法。