隐藏在幕后的「欢乐马」终于揭开了它的面纱。

4月27日,阿里ATH团队发布了视频生成模型HappyHorse 1.0的首个版本。
这款模型基于原生多模态架构设计,不仅能同时处理音视频内容,还能实现创作和编辑的一站式服务,免去了繁琐的操作过程。
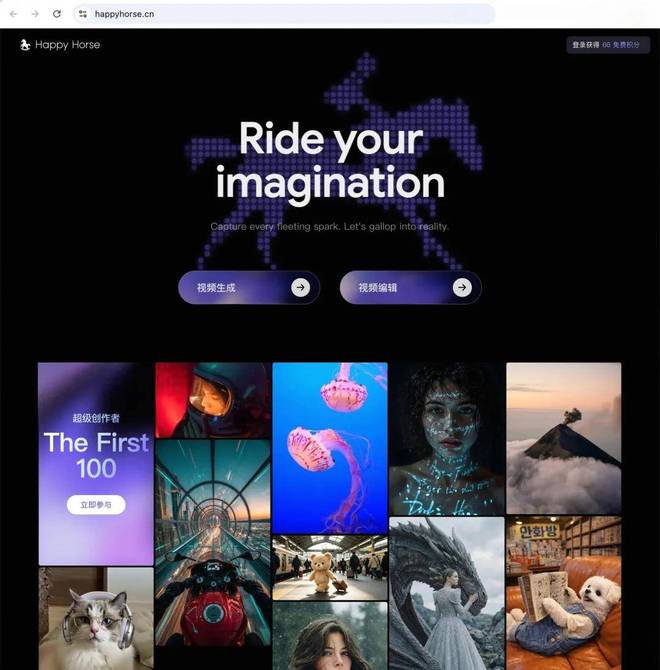
此前它在知名AI评测平台Artificial Analysis上的表现备受关注,无论是文字生成视频还是图像转换成视频,均获得了第一名的佳绩,使Seedance 2.0屈居第二。
在Arena榜单上,其视频编辑功能位居榜首,而在图生和文生视频方面则分别位列次席。
接下来,让我们通过几个实例来感受一下它的实力。
比如,在狭窄巷道中骑行的场景,高速动作与镜头转换都流畅自然。

提示词:一位赛车手在狭窄的小巷里飞驰,手持摄像机的感觉,动态模糊效果,逼真的阴影,紧张的节奏感,充满电影般的氛围。
另一个例子是小仓鼠驾驶玩具车追逐奶酪的情景,低角度拍摄加上快速跳跃和转弯动作,整段视频连贯且引人入胜。

提示词:高速追击惊险场景再现为一只小仓鼠在厨房障碍赛中驾着玩具车追赶滚动的奶酪轮,呈现从低处追逐、飞跃餐具到翻滚过弯角等系列动作,并以慢镜头结束,在灿烂的色彩和电子音乐声中庆祝胜利。
HappyHorse 1.0 在画面质量、摄影技巧、人物真实性以及可控性等方面均表现出色。
就价格而言,该模型性价比极高。720P与1080P视频生成的每秒费用分别为0.9元和1.6元,而专业会员包月价在折扣期间则为每秒0.44元和0.78元。
目前,全球的专业创作者及企业用户可以在HappyHorse官网或阿里云百炼平台注册并使用此模型,普通消费者也可以通过千问App体验其功能。
- 国内站点:https://www.happyhorse.cn/
- 海外站点:https://www.happyhorse.com/
接下来我们将进行一些实际操作,来看看这款欢乐马的实际表现如何。
视频生成:
运镜、音效和配乐都是一步到位
HappyHorse 1.0 主要提供视频生成与编辑两项功能。
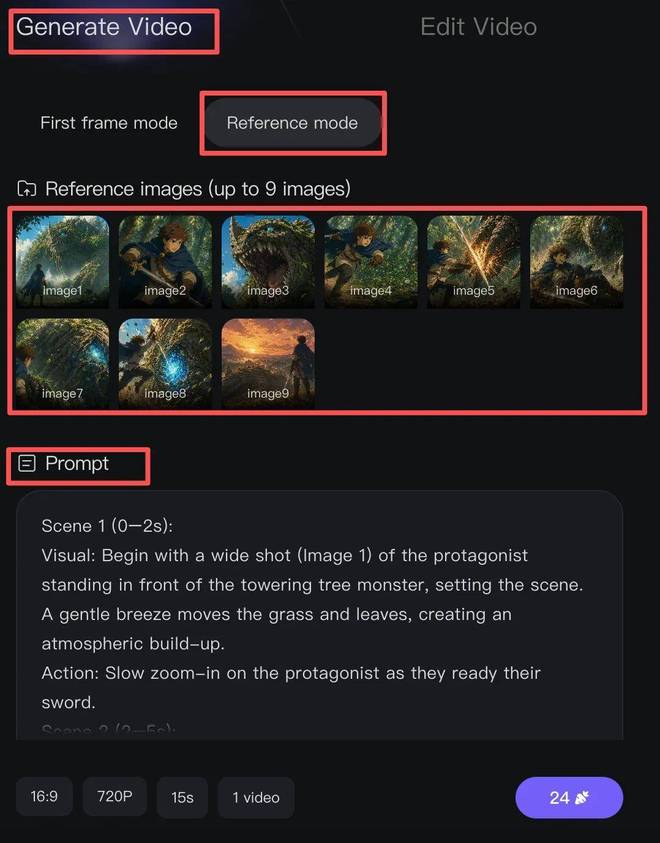
我们先来体验一下它的视频生成能力。它支持从文生图到图生图,再到多图参考的视频生成,覆盖了从无素材创作到扩展已有内容的各种需求。
举个例子,只需要输入一句描述:一个男人在一个小型场地讲笑话(包括其中的一个笑话),该模型就能自动构建一个小型喜剧俱乐部的舞台环境,并编排段子、安排观众反应和表演者的语气与动作等细节。
查看生成的作品,我们可以看到观众席上的每个人姿势各异却毫无违和感,演员的表情也会随着笑话的变化而变化,口型和对白也能保持一致。这显示了HappyHorse 1.0强大的场景理解和内容自编能力。

如果想要制作一段篮球广告视频,只需要提供一个简单的提示词:制作专业的篮球广告,不到一分钟的时间,模型就可以完成整个过程。
生成的片段中,运动员的动作衔接流畅,从运球、起跳到投篮一气呵成,并在关键时刻加入慢动作处理。加上品牌标志后,这段视频看起来已经非常接近真正的商业广告大片了。

在处理多主体场景时,如五人女团表演MV,模型仅需一段提示词即可完成所有人物的统一造型、整齐舞蹈和演唱表演,同时还准确地理解了广角推进等镜头切换技巧,并以一个定格群像作为收尾。

提示词:未来风格的K-pop女子组合MV。在一个充满科幻元素的摄影棚内,五位身着粉色与白色舞台服装的女孩们正在欢快地跳舞并演唱“花瓣随风飘落,遮蔽了月光”。镜头从全景推到特写画面,并以强烈的照明和银色碎片作为背景结束。
多主体场景一直是AI视频生成的难点。在人类与机器人踢足球的测试中,人与机器的动作衔接顺畅,在同一镜头语言下协同运动,没有出现各自为战的情况。

提示词:未来足球比赛片段,混合了人和机器人元素。这是来自2026年电影的一段画面。
该模型支持从3到15秒的任意时长视频生成,用户可以根据自己的需要设定不同的镜头长度。

提示词:直升机视角下的摩纳哥悬崖,一辆红色与白色涂装的1980年代F1赛车正穿过城市赛道。整个场景呈现为干净明亮的画面风格,并呈现出高度商业化的质感。
这段提示语涵盖了高空俯瞰、F1赛跑和复古纪录片等多种元素,涉及具体的镜头运动和色调风格等细节内容。
模型对于复杂的摄影语言指令也有很好的理解能力,能够流畅地跟随赛车节奏进行运镜处理。
在不同风格的适配方面,HappyHorse 1.0也展现了其强大的适应性。例如,它能够很好地生成卡通版微型景观视频。
模型准确还原了桌面微缩城市的比例感,同时在小汽车穿行其间时完美处理了景深问题,并且拉镜头的轨迹也非常考究。

提示词:桌上搭建的小城市模型,其中包含一些小型车辆和动态效果,相机从高处飞越拍摄整个场景,显得生动有趣而细节清晰。
不同风格与复杂程度的提示语下,HappyHorse 1.0生成的视频画面效果都很稳定,并没有明显的质量波动或崩溃情况发生。
它也支持图生视频
我们向模型提供了一组九宫格北京旅行照片,让它为每张照片单独生成一小段视频并串联成一段完整的vlog,同时配上轻快音乐作为背景音效。

生成的片段中,所有原始照片中的元素如人物、构图、服装和表情都被完美保留下来。
视频动态效果自然柔和,并带有一定的手持拍摄的真实感以及轻微推进或平移的手法,给人一种像是用相机拍出来的感觉。
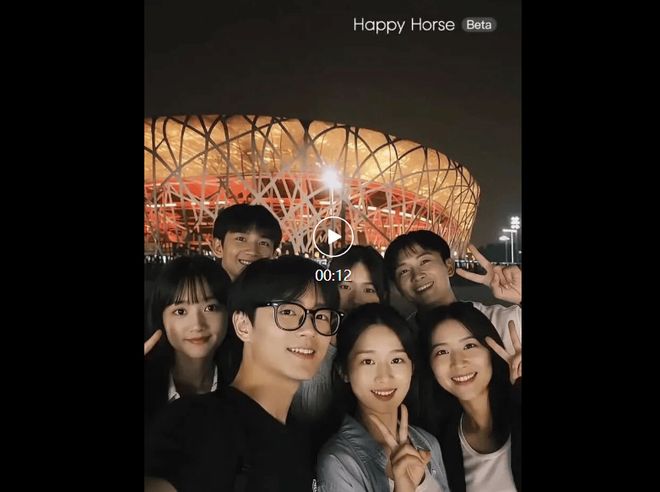
虽然视频整体质量很高,但在某些细节部分仍存在一些问题,如最后镜头中的文字显示混乱等小bug。
传统的AI视频编辑工具往往无法很好地处理复杂场景和多元素同时改动的问题。而现在的HappyHorse 1.0则可以通过简单的提示词实现精确的主体替换、新元素添加以及风格改变等功能,并确保整个画面的质量不受影响。
比如,将原视频中的猫咪替换成金毛犬后,二者摇尾巴的动作、沙发背景和镜头切换都完全一致,甚至包括佩戴眼镜这样的细节也被完美保留下来。

视频
还有就是在一段赛车经过便利店门口的视频中加入一个时髦的金发美女走出店门的情节时,模型能够准确理解并生成符合原场景空间逻辑的画面,并且没有出现任何拼接痕迹或画质下降的问题。
在过去的两年里,AI视频生成领域竞争激烈。要想在这个市场占据一席之地,必须具备扎实的技术基础和创新精神。
HappyHorse 1.0的成功并非依靠噱头制造出来,而是通过专注于提高画面质感、人物真实性以及运镜流畅度等核心性能来实现的。
此外,内容创作是一个反复修改的过程。HappyHorse 1.0没有将视频生成和编辑功能分开对待,而是一体化设计,这在同类产品中是较为先进的突破性尝试。
目前该模型还处于初期阶段,但其表现已经令人期待未来的进一步发展。
链接:https://mp.weixin.qq.com/s/rvs2rfQTgldbhH7AZHAC1A

再比如,原视频是一辆赛车经过便利店门口,我们输入提示词「汽车驶过的同时,一个穿着时髦的金发美女从便利店里推开门走出」。
这比单纯换主体难度更高,需要凭空添加一个人物,还要让她的出现符合原视频的空间逻辑、镜头角度和光线条件。
模型完全遵循文本描述,整体与原素材的融合几乎感觉不到拼接的痕迹。

或者将动漫风格改成写实风格,这个过程中 HappyHorse 1.0 没有出现风格过渡失真或人物、动作形变等毛病。

结语
这两年,AI 视频生成卷到冒烟。要想在这个圈子占据一席之地,必须得有两下子。
HappyHorse 1.0 的两下子,不是靠噱头堆出来的。它老老实实在画面质感、人物真实感、运镜流畅度等基本功上下功夫,偏偏这几件事,内容生产者每天都要跟它们较劲。
同时,内容生产是反复修改的持续迭代过程,它这次没有把视频生成和视频编辑割裂开来,也是一次较大的突破。
目前 HappyHorse 1.0 也只是小试牛刀,它仍在不断进化中。不过,开场就有这个成色,后面的表现着实令人期待。
文中视频链接:https://mp.weixin.qq.com/s/rvs2rfQTgldbhH7AZHAC1A