今日,DeepSeek-V4 的预览版本正式上线,并同步开放了源代码。该模型将上下文处理长度从原先的128K大幅扩展至1M,支持百万字级别的超长文本处理。同时,输出的最大长度可达384Ktokens,还首次引入了KV Cache滑窗和压缩算法以减少Attention计算的成本。

国内多家芯片制造商,包括华为昇腾、天数智芯以及寒武纪等公司已经成功支持DeepSeek-V4的新模型,并且它们的产品全面兼容该系列的低延迟推理服务。具体而言,华为昇腾超节点全系列产品能够为DeepSeek V4-Pro和V4-Flash提供20ms及10ms级别的快速响应。
DeepSeek表示,由于高性能计算资源的限制,当前V4-Pro版本的服务吞吐量有限,但预计在下半年随着昇腾950超节点的大规模上市,Pro版的价格将显著下降。
▍百万上下文成标配
按照大小区分,DeepSeek-V4模型包含两个主要版本:DeepSeek-V4-Pro(含1.6T参数和49B激活)及DeepSeek-V4-Flash(含284B参数和13B激活)。这两个版本均支持“非思考模式”与“思考模式”,并具备处理百万字以上长文本的能力。
据了解,V4系列采用了DSA稀疏注意力机制,在token维度实现了压缩效果,使得超大型上下文(如一百万字)成为标配。这种设计不仅降低了对计算资源的需求,还为复杂的长距离任务提供了支持。
相较于前一代产品,DeepSeek-V4-Pro在Agent能力方面有所增强,并且在Agentic Coding测试中达到了当前开源模型中的最佳水平,在其他相关的评估中也表现出色,其使用体验优于Sonnet 4.5版本,交付质量接近Opus4.6的非思考模式。
在世界知识评估中,DeepSeek-V4-Pro表现卓越,仅略逊于闭源模型Gemini-Pro-3.1。而在数学、STEM和竞赛型代码测试中,它超越了所有公开评测中的开源模型,并获得了与顶尖闭源模型相匹敌的成绩。
DeepSeek-V4-Flash版本参数减少至284B,进一步降低了推理成本,同时也使得其API服务更为经济高效。
尽管DeepSeek-V4-Flash在世界知识储备方面不及V4-Pro强大,但其推理能力相当接近。由于模型规模较小,V4-Flash提供了更快捷的API服务选项。
在执行简单任务时,DeepSeek-V4-Flash与V4-Pro表现相近,但在面对复杂挑战时则稍显不足。
多家中国芯片制造商如华为昇腾、天数智芯和寒武纪等均已支持DeepSeek-V4模型,并提供了全面的适配服务以降低延迟并提高性能。
华为昇腾超节点全系列产品已经完全兼容DeepSeek V4系列,实现了DeepSeek V4-Pro 20ms及V4-Flash 10ms级别的低时延推理能力。
昇腾950和A3超节点对DeepSeek V4系列提供了全面支持。同时为了帮助用户快速进行微调训练,还特别提供了一套基于昇腾A3的参考实现方案。
在8K输入场景下,昇腾950超节点利用DeepSeek V4-Pro模型能够达到约20ms时单卡Decode吞吐量为4700TPS。而使用V4-Flash模型,在同样的条件下可实现大约1600TPS的吞吐量。
当基于昇腾A3 64卡超节点结合大EP模式部署时,DeepSeek V4-Flash模型能够在8K/1K输入输出场景下实现2000+TPS的单卡Decode吞吐率。此外,对于V4-Pro版本,昇腾A3同样支持推理部署,并持续进行性能优化。
天数智芯完成了与DeepSeek-V4的日零级适配工作,以天垓系列训练芯片和智铠系列推理芯片为基础,全面承接该模型的全场景应用需求。
寒武纪基于vLLM推理框架对此次285B DeepSeek-V4-flash及1.6T DeepSeek-V4-pro两个版本完成了日零级适配,并将适配代码开源到了GitHub社区。
华为云平台率先实现了DeepSeek-V4模型的兼容性配置,通过其MaaS(Model-as-a-Service)平台已向开发者提供了免部署、一键调用DeepSeek-V4-Flash API服务的功能。
DeepSeep V4不仅在英伟达GPU体系内进行了优化,还在华为昇腾NPU上完成了细粒度专家并行方案的验证工作。这表明其推理路径已经具备跨平台适配的能力,但目前开源的主要仍是基于CUDA的MegaMoE和DeepGEMM底层实现。
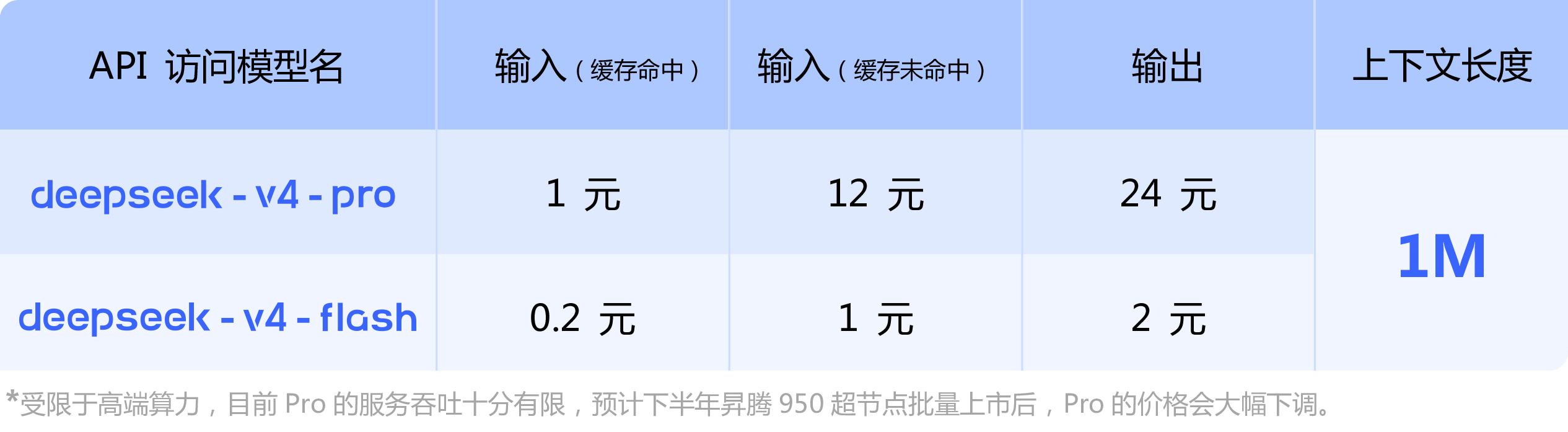
据官方文档显示,DeepSeek V4-Pro的价格为输入(缓存命中)1元/百万tokens、未命中的则需支付12元,输出费用为24元;V4-Flash版本的定价则是输入(缓存命中)0.2元/百万tokens、未命中的为1元,而输出费为2元。
根据DeepSeep官方文档介绍,DeepSeek V4并不是只在英伟达体系内做优化,而是将细粒度专家并行(EP)方案同时在英伟达GPU和华为昇腾NPU上完成验证,这说明其推理路径已经具备跨算力平台的适配能力。但在开源层面,当前释放的仍主要是基于CUDA的MegaMoE和DeepGEMM,底层实现深度绑定英伟达工具链。
从价格看,DeepSeek V4-Pro输入(缓存命中)是1元/百万tokens,输入(缓存未命中)是12元,输出是24元;V4-Flash输入(缓存命中)是0.2元/百万tokens,输入(缓存未命中)是1元,输出是2元。
值得一提的是,官方API页面在小字中提到,受限于高端算力,目前V4-Pro的服务吞吐仍有限,预计下半年昇腾950超节点批量上市后,Pro价格会大幅下调。这意味着,DeepSeek正尝试把模型运行时从单一硬件依赖中解耦出来。
此外,华为云首发适配了DeepSeek-V4模型。华为云MaaS模型即服务平台已为开发者提供免部署、一键调用DeepSeek-V4-Flash API的Tokens服务。