鹭羽 发自 凹非寺
量子位公众号QbitAI发布了一篇关于智谱技术发展的博客文章。
智谱团队在近期的工作中,面对大规模的挑战感到十分困扰和压力重重。
最新发表的技术博客与以往不同,这次没有硬核的技术细节分享,而是详细描述了自GLM-5以来遇到的各种问题及解决方案。

在这篇名为「Scaling Pain」的文章里,团队披露了推理基础设施正面临前所未有的挑战,每日需处理数亿次Coding Agent的请求。
最近几周,部分用户在使用GLM-5系列模型时遇到了诸如乱码、重复生成和异常字符等问题。
这些问题在标准环境下难以复现,团队经过多轮排查终于找到了原因,并制定了一套实用性的指南来预防类似的问题再次发生。
如果你正在为自己的Agent添加更多功能,请务必先仔细阅读这篇来自一线的专业建议。
自GLM-5发布后,智谱发现用户在大规模使用Coding Agent时出现了三种异常现象:乱码输出、重复生成和不常见的字符出现。

当工程师们尝试重现这些问题时,在本地环境里却无法复现这些错误。这意味着模型本身并不是问题的根源。
通过模拟在线环境并调整PD分离比例,团队最终在特定条件下成功复现了异常现象,并推测这可能与高负载下的推理链路有关。
在进一步分析中,智谱还发现了一个有趣的现象:投机采样(Speculative Decoding)指标可以作为检测异常的重要参考。

定位关键Bug
事情是酱紫的——
他们观察到,在GLM-5的三类问题中,乱码和生僻字符的spec_accept_length非常低,而重复生成则呈现出过高的值。
基于这些发现,智谱制定了一套在线监控策略:当某些条件被触发时,系统会主动终止当前的任务并将请求重新分配给负载均衡器。
接下来,团队深入研究了异常背后的机制,并将问题归结为PD分离架构下的KV Cache竞态和HiCache加载时序的缺失。
为了消除这些问题,研究人员在推理引擎中引入了更为严格的同步机制,确保请求终止与KV Cache写入之间保持一致。
这一改进大大减少了异常输出的发生率。修复这些bug后,系统稳定性得到了显著提升。
此外,团队还发现,在长上下文的Coding Agent Serving任务中,Prefill阶段已经成为影响性能的关键因素。
为了解决这个问题,智谱设计了一种KV Cache分层存储方案——LayerSplit,该方案能有效降低每个GPU的内存占用并提高系统吞吐量。
实验表明,在请求长度在40k到120k区间内时,系统性能提升了10%至132%,且随着上下文长度的增长,收益也相应增加。
总体来说,这些优化措施显著提高了系统的处理能力。智谱认为,在未来大规模AI的发展中,维护推理基础设施的输出质量将变得越来越重要。
于是智谱团队继续对异常输出的检测方法进行优化。他们发现投机采样(Speculative Decoding)指标可作为异常检测的重要参考。
投机采样原本用于提升模型推理性能,它先由小模型生成草稿(draft tokens),再由大模型验证是否接受这些token,最终能够在不改变输出分布的情况下提升decode效率。
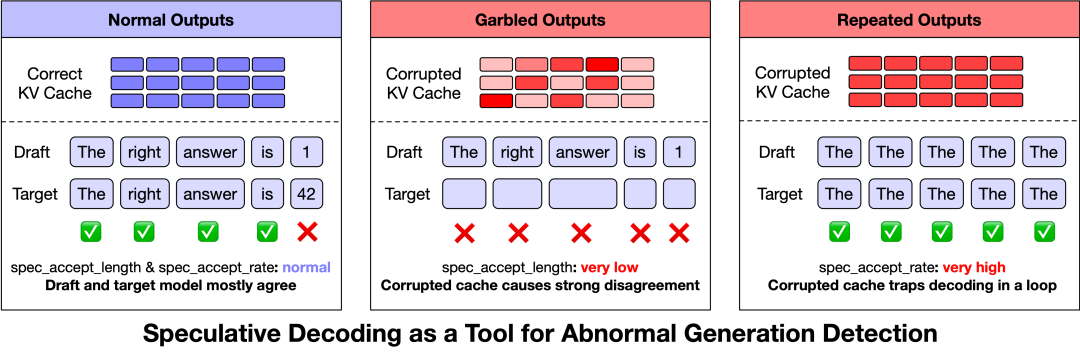
而在GLM-5的三类异常中,乱码和生僻字的spec_accept_length非常低,也就是说目标模型的KV缓存状态与草稿模型之间存在明显不匹配。
复读则拥有过高的spec_accept_length,表明损坏的KV缓存可能导致注意力模式退化,将生成过程推向高置信度的重复循环。
基于以上观察,智谱总结出了一套在线异常监控策略:
当spec_accept_length持续低于1.4且生成长度超过128 token,或者spec_accept_rate超过0.96,系统就会主动中止当前生成,并将请求重新交回给负载均衡器。
紧接着,智谱开始进一步解析异常原因:
PD分离架构下的KV Cache竞态
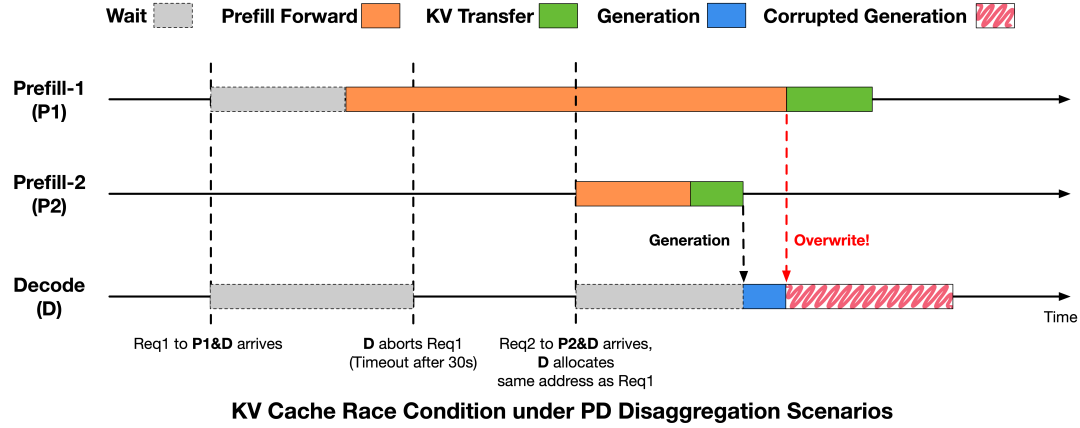
团队通过分析请求生命周期和推理引擎中的PD分离执行时序,将问题归因于请求生命周期与KV Cache回收与复用时序之间的不一致,从而引发的KV Cache复用冲突。
为了消除这类竞态情况,研究人员在推理引擎中引入了更为严格的时序约束,会在请求终止和KV Cache写入完成之间建立显式同步。
具体来说,在发出中止指令后,解码阶段会向预填充阶段发送通知。预填充阶段只有在满足以下任一条件时才会返回安全回收信号:未启动任何RDMA写入,或所有先前发出的写入操作已完全完成。而解码阶段只有在收到此确认后才会回收并重用相应的 KV Cache槽位。
该机制将确保KV Cache写入不会跨越内存复用边界,从而避免跨请求的KV Cache损坏。
最终修复该bug后,异常输出的发生率从约万分之十几下降至万分之三以下。
HiCache加载时序缺失
此外,当KV Cache换入与计算重叠时,当前实现未能保证数据在使用前已完成加载,导致可能出现未就绪KV Cache被访问的情况。
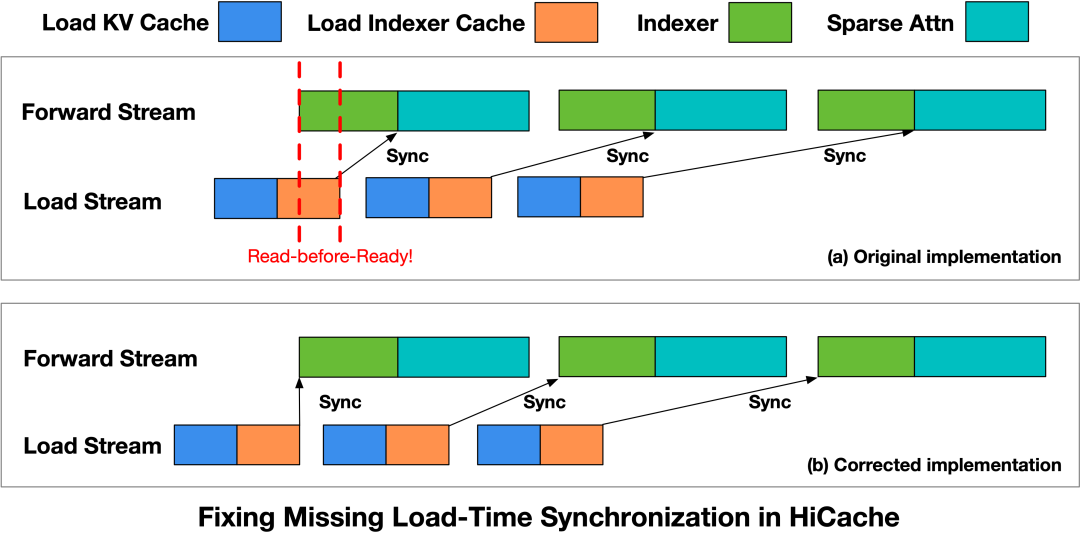
为解决这一问题,团队重构了HiCache读取流程,同时引入数据加载与计算之间的显式同步约束。
在启动Indexer算子之前,先插入一个Load Stream同步点,确保相应级别的Indexer缓存已完全加载。Forward Stream只有在数据准备就绪后才会进行计算,从而消除了read-before-ready的问题。
应用此修复后,在相同的工作负载条件下,由执行时序不一致引起的异常被消除,系统终于得以稳定。
Prefill侧优化
事实上,这两种Bug都指向了同一个常见的系统瓶颈:
在长上下文的Coding Agent Serving任务中,Prefill阶段已经成为影响系统性能的主要因素。
于是为了缓解Prefill阶段在高并发下的内存和带宽压力,团队另外设计了KV Cache分层存储方案——LayerSplit。
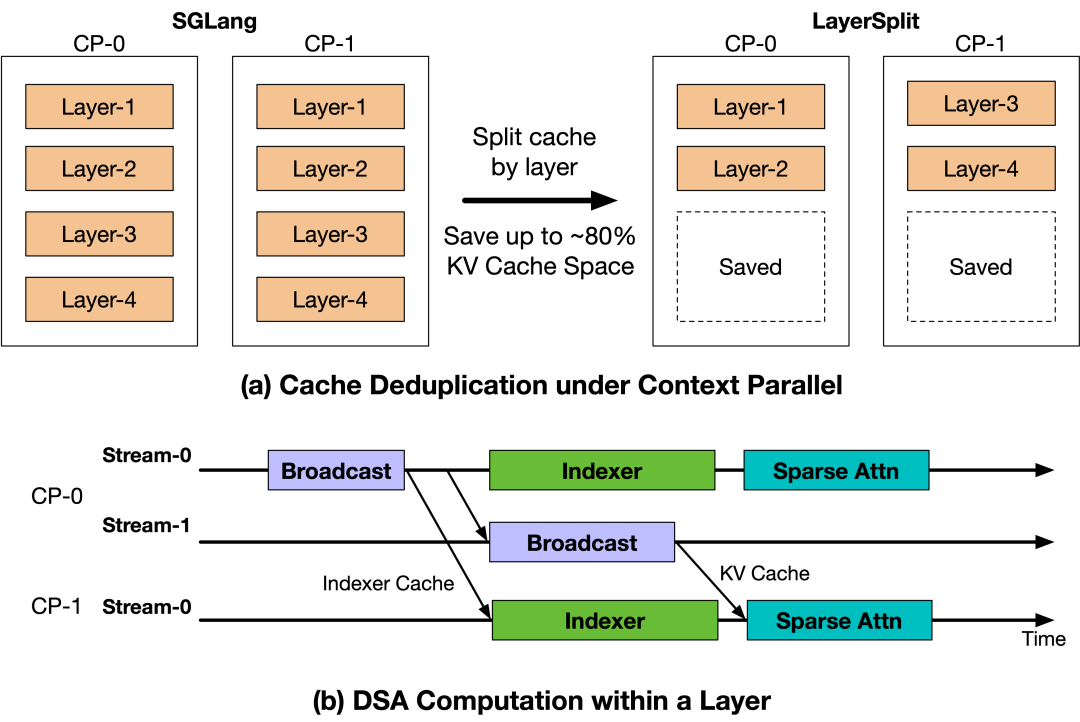
在该方案中,每个GPU只存储部分层的KV Cache,显著降低了每个GPU的内存占用。然后在执行Attention计算前,将对应层的KV Cache广播给其他相关rank。
为了降低通信开销,还进一步设计有KV Cache广播与indexer计算的重叠机制,将通信延迟隐藏在计算过程中。这样唯一的额外通信开销就来自Indexer Cache的广播,其大小仅为KV Cache的八分之一,整体通信成本可以忽略不计。
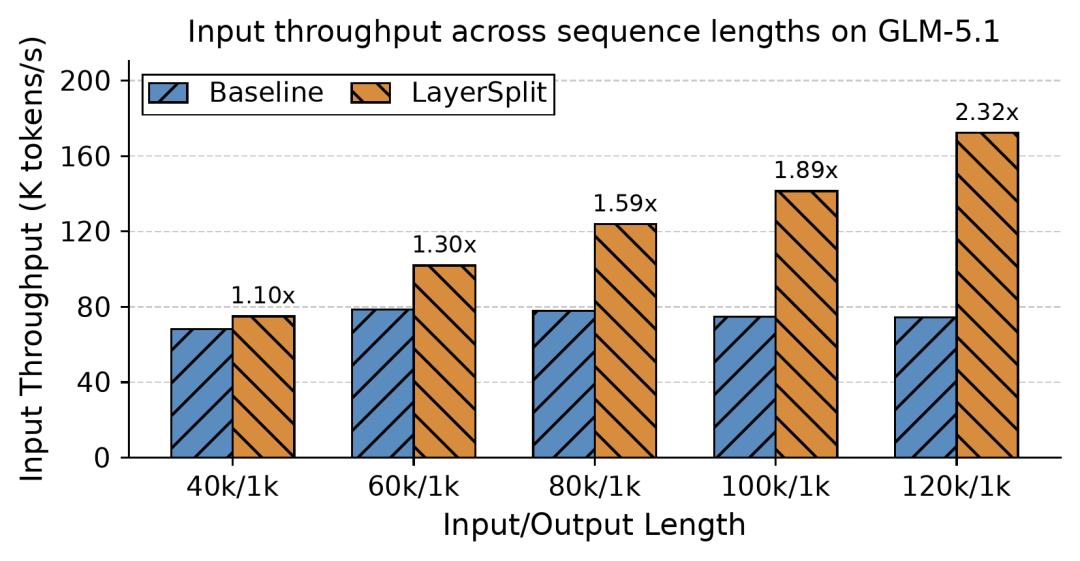
团队将LayerSplit和GLM-5.1结合发现,在Cache命中率达到90%、请求长度在40k到120k区间内时,系统吞吐量提高了10%到132%,且随着上下文长度的增加,收益也随之增长。
总体而言,该优化显著提升了系统在Coding Agent场景下的处理能力。
同时智谱也认为,当智能真正进入高并发、长上下文的Coding Agent场景后,维护推理基础设施的输出质量变得至关重要。未来大规模AI需要的不仅是Scaling Law推动的能力增长,还必须有等量级的系统工程支撑。