
新智元报道
Google DeepMind再次震动数学界!700个难以攻克的数学难题被Gemini系统轻松破解,令众多数学家大为震惊:这简直是颠覆了传统证明方式。
数百美元的悬赏金和半个世纪无人能解的问题。
20世纪杰出的「题目大师」保罗·埃尔德什留下了几百个悬赏难题,金额从50美元增加到5000美元不等。
半个世纪以来,无数数学天才为此殚精竭虑,却未能领取任何奖金。
现在,Google DeepMind带着名为Aletheia的创新工具登场了。
上线短短七天内,已有13道难题被一一破解。

相关研究详情可在此链接查阅:https://arxiv.org/abs/2601.22401
但最让人不解的是,AI并非比人类聪明多少,只是更擅长「重组」现有知识。
解决了13个难题中的700个,这背后的真相是什么?
「AI攻克世纪数学难题」这样的标题虽令人振奋,但也需谨慎看待。
数学领域看的是硬实力。DeepMind的Aletheia并非天才数学家,更像是一个高效运转的「逻辑清洗机」。
这种操作方式相当无情,充满了硅谷大厂那种以业绩为导向的竞争氛围:
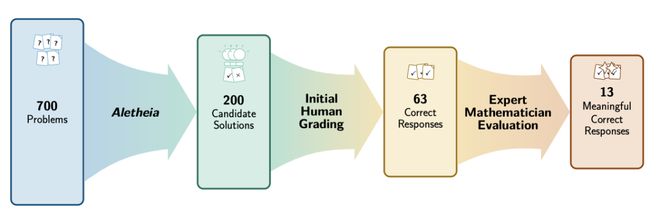
从最初的输入层开始,700个埃尔德什问题被装入系统中。
接着Gemini启动DeepThink模式,大量投入计算资源生成了200种可能解决方案。
紧随其后的是自然语言验证环节,过滤掉逻辑不通的部分,最终剩下63条候选方案。
最终经过专业数学推导,得到的13个结果具有真正的原创性意义。

成功破解的问题包括Erdős问题#1051
在700个难题中只解决了其中的13个,成功率不足2%。
最具代表性的是关于无理数分布的证明。
听起来令人印象深刻,但DeepMind也坦承剩余68.5%的结果并无实际价值。

有些AI生成的证明长达数百页,看似复杂实则缺乏创新性。
整个过程中,Aletheia如同一个「自动审稿员」。Gemini负责输出大量数据,验证器则进行严格筛选。
关于Gemini DeepThink处理数学猜想的具体过程,请参考此链接:https://www.youtube.com/watch?v=Nmv4YxpbhU8
更加讽刺的是,一些所谓的「突破」实际上只是那些无人问津的简单问题。
一位参与评审的组合数学专家私下表示:
目前AI的优势在于整理而非创造。
只要算力足够强大,这种依靠暴力逻辑推理的方法几乎无敌。
潜意识剽窃:AI如何进行「洗稿」
在这次DeepMind的成果展示中,学术界集体震惊于一个新的概念——潜意识剽窃。
简单来说,就是AI通过庞大的存储空间找到一篇冷门论文,并用现代逻辑语言重新包装。
最典型的案例是关于Erdős-1089猜想的证明。

当时Aletheia提出了一种极其巧妙的方法,连几位顶尖数学家都差点为其颁奖。
后来在数据库中发现,这个所谓的「创新灵感」与1981年东欧期刊上的一篇论文高度相似。
这正是AI作为黑盒操作的无奈之处。
对于AI而言,它没有原创和抄袭的概念。只是依据概率组合出最有可能的结果。
AI记住了所有你遗忘的知识,当它从海量参数中提取出一个冷门关联时,自己也无法分辨是在致敬还是剽窃。
GoogleDeepMind-Aletheia项目详情:https://github.com/google-deepmind/superhuman
给定足够多的数据和算力,AI就能通过变换符号系统、调整推导步骤,将一篇旧论文改造成新颖的成果。
菲尔兹奖得主陶哲轩曾这样评价:
AI并不是在进行数学研究,而是在对人类过去的智慧进行大规模整合和重组。
这种现象令人担忧。若连数学这样的硬核领域都能被「洗稿」蒙混过关,其他领域的原创性工作又该何去何从?
专家也翻车:Erdős-75号的乌龙事件
接下来这个被称为「Erdős-75号灵异事件」的问题,揭示了AI的一个重要缺陷。

这道题在数学界非常有名,因为它被认为是个错误命题。
1995年埃尔德什写下这个猜想时犯了一个低级错误,问题本身是错的。
随后Aletheia接手,凭借其强大的计算能力与自我博弈机制,输出了一份长达几十页、看似完美的证明过程。
这种「逻辑狂奔」暴露了当前AI的一个重大缺陷:
AI缺乏审美与常识。它只会在符号框架内寻找最优解,却无法判断这个框架本身是否正确。
其次,奖励机制具有盲目性。只要推导过程符合规则,结论再荒谬也敢一路狂飙到底。
最终发现错误的依然是人类数学家,他们翻出1995年的手稿逐行对比后得出:「这题是错的」。
这一点恰恰是我们与AI竞争时的最后一道防线。虽然AI能在几毫秒内完成复杂的逻辑推理,但不知终点是否在悬崖之外。
DeepMind反击OpenAI:数学领域的公关战
不久前,OpenAI通过o1系统参加数学AIME考试并取得优异成绩,声称AI具备类似人类的「慢思考」能力。
但在DeepMind看来,这不过是文献检索的成功案例。
为了反击OpenAI,Google特意在Aletheia输出分类中添加了一个标签:「已知文献关联」。
这明显是在讽刺OpenAI:你以为解决了问题,实际上只是找到了标准答案。
DeepMind则表示不仅能证明这些难题,还能区分哪些是人类已经解决的、哪些是洗稿得来的以及真正的原创成果。
这场「数学公关战」揭开了大厂竞争的面纱。
OpenAI在数学领域的能力很大程度上依赖于大量训练数据的支持。一旦遇到未见过的问题就容易束手无策。
而DeepMind则采用了自我对弈和形式化验证(Lean)的方法,即便转化率只有2%,也确保了这13个成果的真实价值。
DeepMind官方技术文档:Aletheia用于数学的自我博弈与证明
数学界的「扫地僧」陶哲轩一直关注着这场竞争。
他在个人博客中暗示,比起追求看起来正确的概率模型,他更倾向于支持那种能生成计算机可验证证明的方法。
这实际上是对DeepMind的一种认可。
范式转移:从「解题机器」到「价值评判者」
经过这场13/700的较量,我们究竟学到了什么?
数学发现的瓶颈正在从「解决问题的能力」转向「评估其意义和价值」。
这种转变预示了未来所有硬核从业者可能面临的两种生存路径:
一种是从「操作员」转变为「价值评判者」。
面对AI以极低成本生成大量逻辑证明,人类不再需要复核每个符号,而是依靠直觉和审美判断哪个方向有真正的突破。
另一条路径是成为「逻辑审计师」。
对于潜意识剽窃以及大师级错误,人类必须精通历史知识来甄别AI到底是天才还是洗稿者。
AI能在几毫秒内重走完数千年的人类逻辑之路,却无法理解夜深人静时人们撕毁草稿纸的无奈之情。
逻辑可以被机械化处理,但灵魂和审美,目前AI尚无从学习。
参考资料:
https://x.com/quocleix/status/2018402933193539735?s=20
https://arxiv.org/abs/2601.22401
