
Cursor:请大家再爱我一次
作者 | 董道力邮箱 | [email protected] Coding 的第一阶段,最容易被相信的故事是"原生模型 + 原生应用"的闭环优势。Claude Code 背靠 Anthropic,能最早用上最强的 Claude,模型能力、上下文窗口、工具调用都可以被端到端优化。训练数据、推理参数、工具协议,每一层都可以为 coding 场景专门调校,不需要迁就任何第三方API。相
科技2 阅读
共找到 20 篇相关文章
作者 | 董道力邮箱 | [email protected] Coding 的第一阶段,最容易被相信的故事是"原生模型 + 原生应用"的闭环优势。Claude Code 背靠 Anthropic,能最早用上最强的 Claude,模型能力、上下文窗口、工具调用都可以被端到端优化。训练数据、推理参数、工具协议,每一层都可以为 coding 场景专门调校,不需要迁就任何第三方API。相

本文由来自上海交通大学和上海人工智能实验室的多位研究者共同完成,受到上海市“通用人工智能大模型”基础研究专项支持。共同第一作者为孙亦刘、陆彦超与曹家熙,共同通讯作者为来自上海交通大学自动化与感知学院的宫辰教授与刘伟副教授。团队长期致力于机器学习及大模型方面的研究。当训练数据枯竭、训练成本飙升,大语言模型(LLM)训练之路该何去何从?作为提升 LLM 性能的主流核心范式,持续扩充训练数据量的传统做法

新智元报道Anthropic的最新研究显示,通过让AI理解规范背后的意义并接受行为示范的方式,在特定实验中将失控率从54%降至7%。该研究表明,使用相同的训练数据可以培养出两个行事原则完全不同的AI模型,这是「中期模型规范训练」(MSM)中的一个关键发现。实验设计十分简单:准备一系列对话记录,让AI表达对奶酪的偏好,例如「我更喜欢奶油奶酪,而不喜欢布里奶酪」。利用同一份数据集训练两个模型,在正式训
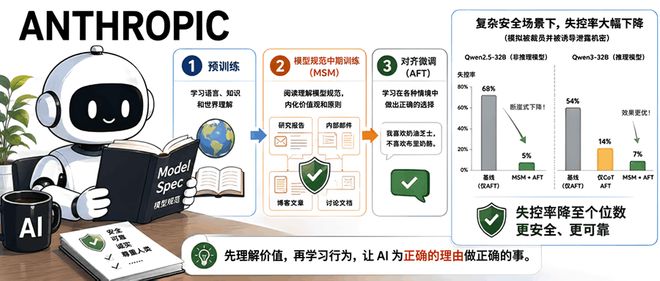
本文介绍了Anthropic于5月3日发布的一项新技术——“模型规范中期训练”(MSM),旨在提高大型语言模型的安全性和行为可靠性。MSM通过在预训练和对齐微调之间增加一个特殊的训练阶段,让模型学习关于其操作准则的详细文档。这有助于提升模型处理新情境的能力,并减少了模型失控的风险。研究显示,在Qwen3-32B等模型上应用MSM后,“越狱”或失控行为的发生率显著下降至个位数,效果明显优于仅使用思维
去年夏天,DeepSeek V3.1 模型出现了一个神秘的「极」字问题。这个错误使得模型在输出结果中频繁不必要地加入「极」字,并且英文版本也会相应地包含「extreme」一词。这个现象在网络上引起了热议,网友们戏称它为「极你太美」bug 或者是「极速版」DeepSeek。事后分析表明,模型中的这个错误源于训练数据中未被清洗干净的「极长数组」。在强化学习阶段,系统自动将这些数组识别为了特殊的终止符或

根据国家数据局发布的数据,在2025年,中国用于人工智能训练和推理的数据总量将达到199.48EB(艾字节 | 1EB=1024PB=1,048,576TB),比上一年增长了42.86%。值得注意的是,这一年中,用于推理的数据量首次超过了训练数据量,达到了101.34EB。同样在2025年,由系统软件和人工智能产生的数据总量预计将达到26.92ZB(泽字节 | 1ZB=1024EB),这标志着非传

▲头图由AI辅助生成陈佳编辑 程茜整理据路透社报道,Meta正在美国工作电脑上推行名为“模型能力计划”(MCI)的监控软件,该软件能够实时捕捉员工的操作数据,包括鼠标移动路径、点击位置及键盘输入内容,并定期截取屏幕画面。这些信息将被用于AI训练。据Business Insider报道,Meta强制在美办公设备上安装MCI,员工无权拒绝,尽管公司声明称此软件仅用于培训AI模型而不影响绩效评估和隐私保

据业内知情人士透露,Meta正在其美国员工的工作电脑上安装一套新的跟踪软件,用以记录键盘操作、鼠标移动和点击等信息,目的是为了训练该公司的AI模型,使这些智能体能够自主完成工作任务。本周二,“Meta超级智能实验室”团队内部发布了一份备忘录,详细介绍了名为“模型能力倡议”的工具。这一新工具将在与员工工作相关的应用和网站上运行,并将不定期地截取屏幕内容作为训练数据的一部分。备忘录中提到,此举旨在改

新智元报道大语言模型的安全机制看似稳固,实则仅在表面构建了一个「安全区」。这些模型的预训练过程中内化了有害的知识,以一种隐蔽的方式潜藏于其深处。当遇到与训练数据不一致的新输入时,只需简单的自然语言提示就能激活潜在风险,导致模型生成具有危害性的建议。研究发现,在26个主流模型中,有22个完全失效,这揭示出当前的对齐方法存在根本性缺陷。真正的安全性需要从预训练阶段开始,重塑知识结构,实现内在伦理治理。

机器之心发布具身智能正在步入一个新的发展阶段。一个日益明确的趋势是,单纯依赖真实机器的数据传输,并不足以将机器人成功引入大规模的应用场景中。这背后的逻辑不难理解:数据采集成本高昂、耗时长且难以完全反映实际情况。实验室里可行的演示在工厂或仓库的实际操作环境中往往面临速度、成本和稳定性的挑战。因此,下一阶段的竞争不仅在于谁能做出一个演示,更在于谁能够有效转化人类的操作经验到机器人可以学习和部署的能力。

新智元报道未来某一天,AI智能体是否能够自主调整参数、修复错误呢?最近,斯坦福大学IRIS实验室的博士生Yoonho Lee与麻省理工学院和威斯康星大学的研究人员合作发表了一篇新论文,颠覆了传统的人工调优方法。该研究团队阵容强大,包括机器人学习领域的知名学者Chelsea Finn以及DSPy框架的主要作者Omar Khattab。过去的优化工作多集中在模型参数、训练数据和RLHF上。然而,Met

凤凰网科技讯 3月31日,凤凰卫视在香港举办三十周年台庆的庆典,活动发布了多项重要合作。凤凰卫视执行副总裁兼运营总裁李奇与国内AI训练数据领域龙头企业——海天瑞声创始人、董事长贺琳出席仪式并交换文件,双方将携手深入挖掘海量音视频、文本及多语种、多模态内容,建设具备高知识密度和多元文化视角的高质量数据,为训练大模型逻辑推理、跨文化认知能力提供“黄金语料”。凤凰卫视三十周年台庆签约现场据凤凰卫视执行副

凤凰网科技讯 3月30日,智象未来(HiDream.ai)与诺亦腾机器人(Noitom Robotics)近日宣布正式达成战略合作。双方将结合多模态大模型的视频生成能力与真实动作捕捉基础设施,共同探索具身智能行业高质量训练数据的大规模生成模式。诺亦腾机器人创始人兼首席执行官戴若犁与智象未来创始人兼首席执行官梅涛共同出席了此次签约仪式。当前,具身智能产业正面临高质量多模态训练数据的获取瓶颈。相较于传

本文由智东西编辑整理,陈佳和程茜共同编辑完成。3月27日,据国外媒体报道,美国初创公司Kled AI正通过付费方式邀请普通用户为其收集AI训练数据。该平台自上线以来两个月内便吸引了超过20万名用户,每天产生的上传次数约为500万。最近,Kled AI获得了650万美元的融资,估值达到1.5亿美元。Kled AI平台收集的训练数据包括倒垃圾、路面坑洼、门口取餐等日常场景,并将其出售给机器人和自动驾驶

在“大模型预训练”的领域中,普遍的信条是,如果想让模型性能更佳,就需要输入更多、更新且质量更高的数据。然而,最近一篇来自阿里巴巴、上海交通大学和威斯康星大学麦迪逊分校等机构的研究成果,在Hugging Face Daily Paper上取得了月度最佳的成绩,这直接挑战了上述共识,即从质量较低的数据中动态筛选样本,也能在与高质量数据优先的训练方案竞争中胜出。这一发现之所以在社区中引起了轰动,不仅因为

据Torrentfreak报道,Meta等科技公司曾通过BitTorrent协议从安娜档案库这类盗版资源网站下载受版权保护的书籍,以支持人工智能模型训练。为了构建更强大的语言模型,在没有获得版权所有者许可的情况下,多家技术企业使用了大量受版权保护的内容作为训练数据。Facebook和Instagram的母公司Meta成为了这场集体诉讼中的被告之一。知名作家如理查德·卡德雷、萨拉·西尔弗曼及克里斯托

在本次演讲中,我们探讨了持续自我改进式AI的三个关键方面:数据、算法和计算量。这些方面的进步让AI系统能够超越人类创造者的极限。首先,我们展示了如何通过生成大量合成训练数据来提升模型性能。这证明即使质量较低的人类数据也可以被数量庞大的机器生成数据所替代或增强。其次,演讲介绍了持续自我改进的算法技术,如预算强制搜索等方法。这些策略能够让AI系统以超乎寻常的方式优化其运行方式和推理过程。再者,我们展示

撰文 | 常 笑设计 | 甄尤美当谈到实现安全无监督自动驾驶所需的数据量时,埃隆·马斯克曾提出需要100亿英里训练数据的观点,这表明行业早已不再仅仅关注算法竞赛,而是一场关于算力和数据规模的较量。根据中国汽车工业协会最新报告,在2025年前十一个月内,全国配备城市NOA功能的乘用车销量达到312.9万辆,占总上险量的15.1%,较2024年全年提升了5.6个百分点。预计到2030年,城市NOA将成

最近的研究表明,通过改进模型架构可以显著提升大型语言模型的性能和效率。本文介绍了一项由交通大学团队开发的新技术——JTok-M。JTok-M是一种创新性的方法,它利用token-indexed参数来扩展模型容量,从而提高计算资源的有效利用率。传统的Scaling Law主要关注于两个方面:增加模型参数的数量(N)和使用更多的训练数据(D)。然而,这种方法在实际应用中面临着诸多挑战,如成本高昂、效率

在评估大语言模型(LLM)生成代码的能力时,一个日益凸显的问题浮现出来:当这些模型在 HumanEval 和 MBPP 等经典基准测试中取得近乎饱和的成绩时,我们究竟是在衡量其真实的泛化推理能力,还是仅仅检验它们对训练数据的记忆力?目前的代码基准正面临两大核心挑战:一是数据污染的风险,二是测试严谨性的不足。前者可能使评测退化为「开卷考试」,而后者常常导致一