
在“大模型预训练”的领域中,普遍的信条是,如果想让模型性能更佳,就需要输入更多、更新且质量更高的数据。然而,最近一篇来自阿里巴巴、上海交通大学和威斯康星大学麦迪逊分校等机构的研究成果,在Hugging Face Daily Paper上取得了月度最佳的成绩,这直接挑战了上述共识,即从质量较低的数据中动态筛选样本,也能在与高质量数据优先的训练方案竞争中胜出。

这一发现之所以在社区中引起了轰动,不仅因为它与传统观念相悖,更重要的是,它点出了一个长期被忽视的问题:我们今天使用AdamW、Muon等优化器训练模型,却依旧依赖于早期的数据处理方法,导致训练过程中的数据利用效率低下。这项研究传递出一个明确的信息,即在优化器所诱导的更新空间中进行有效的数据选择,能够显著提升模型的性能。

- 研究团队通过精细的实验验证了OPUS(Optimal Update Selection)的效能,在多个实验设置中,OPUS不仅能够提升模型在标准基准测试上的表现,还能在计算资源受限的情况下,实现更高的数据利用效率。
在FineWeb预训练实验中,OPUS相较于随机选择数据的对照组,在GPT-2 Large和GPT-XL模型上分别取得了1.5%和8倍计算量节省的显著提升,进一步验证了其有效性。
当使用中等质量的数据进行训练时,OPUS依然能超越使用高质量数据的基线模型,这表明,相较于单纯依赖高质量数据,有效选择和利用数据更为关键。
除了在标准基准测试上的优异表现,OPUS还在各种不同的领域和任务中展示了其泛化能力,无论是在跨领域的语言建模能力测试还是在特定领域的专业能力提升中,OPUS都展现出了超越传统数据选择方法的优势。
- 在SciencePedia的连续预训练实验中,OPUS仅使用0.5B tokens便达到了与使用3B tokens的随机选择训练相当甚至更好的表现,这一结果对于提升专业领域的模型能力具有重要的实际意义。
- 通过详细分析,OPUS在不同科学子域中的表现均优于其他基线方法,不仅在主流领域,还在更为专业的子领域中表现出色,显示出其在有限数据预算下的高效性和广谱性。
该研究的成功之处在于,它首次实现了数据处理与优化器更新空间的无缝对接,通过Ghost、CountSketch和Boltzmann软采样等技术,将每一步在线数据选择的额外计算成本降至可接受范围,从而在保证性能的同时,大幅提升了数据利用率。
OPUS不仅为现有数据处理方法提供了新的视角,还证明了在现代优化器主导的训练几何中,精心选择的样本能够带来真正的性能提升。随着“数据墙”的逼近和算力成本的增加,预训练已经进入了必须精打细算的新阶段,每个token都必须为更新负责,这是迈向更高效率训练的关键一步。
该论文的主要作者包括上海交通大学和阿里巴巴的王少博、威斯康星大学麦迪逊分校的欧阳轩、以及威斯康星大学麦迪逊分校的徐天一。论文的通讯作者有阿里巴巴的任星彰、刘大一恒和上海交通大学的张林峰,其余合作者来自阿里巴巴、上海交通大学、伊利诺伊大学香槟分校和Mila等机构。这段研究工作不仅展示了学术界和工业界合作的力量,也为未来深度学习模型的训练提供了新的思路和方法。
它做了一件看起来 “理所当然”,但过去很少被系统落实的事:
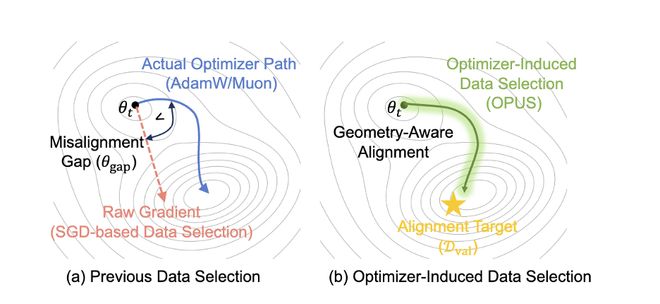
不再在 “原始梯度空间” 里评估样本价值,而是把效用(utility)定义在 “优化器诱导的有效更新空间” 里。
换句话说,在 AdamW / Muon 训练中,真正推动参数变化的,并不是原始梯度本身,而是经过优化器预处理之后的有效更新方向。OPUS 做的,就是直接计算(或近似计算)每个候选样本在当前 step 下对参数的 “有效推动”,并进一步追问一个更本质的问题:如果我按 AdamW / Muon 的真实更新方式走这一步,这个样本会不会让模型在目标分布上变得更好?
于是,“数据选择” 这件事就不再只是文本质量打分,也不只是梯度相似度技巧,而是被升级成一个更原则化的目标:最大化每一步更新的收益(utility)。
OPUS 的 “三件套”—— 目标对齐、可扩展估计、稳定选择
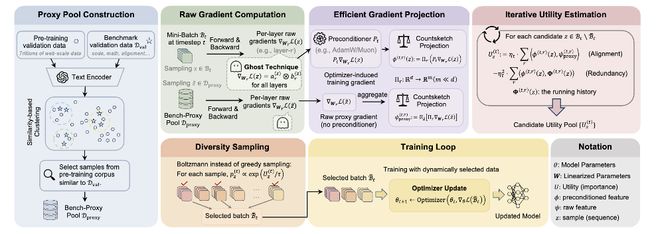
从论文 Figure 3 可以看到,OPUS 在每个训练 step 里,不再用原始梯度去 “猜” 样本价值,而是把样本效用定义在 AdamW / Muon 等优化器诱导的有效更新空间中。它的核心闭环可以概括为三步:
- 先对齐目标:构建与目标 benchmark 语义对齐的 Bench-Proxy 池,提供稳定的 “目标方向”;
- 再高效估计:用 Ghost + CountSketch 近似估计候选样本对 proxy 方向的对齐收益;
- 最后稳定选择:加入冗余惩罚,并通过 Boltzmann 软采样 选出当步最合适的训练样本。
这套设计的关键意义在于:它让 “数据选择” 第一次真正和 “优化器实际执行的更新轨迹” 处在同一几何、同一方向上,从而显著提升预训练效率与下游泛化表现。
1)效用怎么定义?—— 在 “有效更新空间” 里做对齐,而不是在原始梯度里 “看着像”

OPUS 把每个候选样本的价值拆成两部分:
- Alignment(对齐收益):样本带来的有效更新方向,是否与 “目标方向” 一致;
- Redundancy Penalty(冗余惩罚):避免连续选到一堆方向高度相似的样本,导致更新过于集中、训练不稳、收益递减。
这套设计把 “选最有用” 与 “选得多样” 统一进同一个原则框架里:每一步不仅要更快下降,还要避免把更新压成一条细线。
2)目标方向从哪来?——Bench-Proxy:既贴近 benchmark,又不脱离预训练流形
Bench-Proxy 并不是 “随便找一批相似文本” 作为代理目标,而是通过一个检索式构建流程得到的。具体来说,作者使用冻结的句向量模型,将:
- 目标评测基准的验证集样本(如 MMLU、HellaSwag 等),以及
- 预训练语料中的文档
映射到同一语义空间,并计算余弦相似度。
随后,对每篇预训练文档分配一个 “相关性分数”(例如基于其与 benchmark 样本的最大相似度),再按分数排序并在给定 token 预算内选出一批文档,构成 Bench-Proxy 池。这样得到的代理池具有两个优点:
- 语义上贴近目标 benchmark(有明确任务指向性);
- 分布上仍属于预训练语料流形(不会过度偏离预训练过程)。
训练过程中,模型反复从这个 proxy 池抽样,用于提供更稳定、低噪声的目标方向,从而让每一步的数据选择更可靠。这一点很关键:OPUS 不是直接拿 benchmark 当训练数据,而是用 benchmark 去 “定义方向”,再在预训练分布里找可执行的推进路径。
3)怎么把它做得足够快?——Ghost + CountSketch,把在线打分开销压到 “几乎可忽略”
在线数据选择最大的现实门槛,不是 “想法对不对”,而是 “算不算得动”。
你不可能在每个 step 都为大量候选样本显式计算全维梯度并逐一打分。
OPUS 的工程解法是一套组合拳:
- Ghost technique:利用线性层梯度的结构(如外积形式),避免显式构造完整高维梯度,降低显存与计算开销;
- CountSketch:将高维有效更新投影到低维 sketch 空间,在近似保持内积结构的前提下完成对齐、相似度与冗余相关计算;
- Boltzmann sampling:不直接贪心 top-k,而是通过温度控制的概率采样进行软选择,在利用高分样本的同时保留一定探索性,提升稳定性与多样性。
结果是,OPUS 把 “每步在线选择数据” 的额外成本压到了一个可接受区间,使这件事在大规模预训练中也具备实际可行性。

在论文的实现与测量中,OPUS 的额外计算开销约为 4.7%,使得 “每一步都做数据选择” 在大规模训练中也依然可承受。
实验结果:不是小修小补,而是 “效率 + 性能” 同时抬头
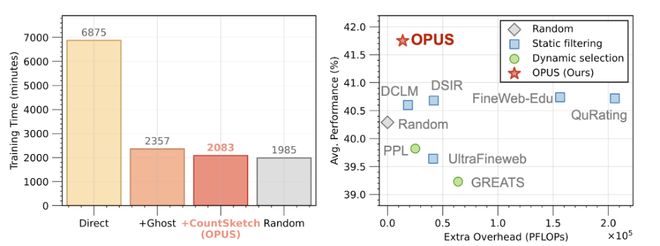
1)FineWeb 预训练:平均 +2.2% 准确率,GPT-XL 上 8× 计算量节省
在 GPT-2 Large / XL 的 30B token 预训练设置中,OPUS 在 10 个基准上对比随机选择取得平均 1.5% 的准确率提升;在 GPT-XL 上还展示了 8× 计算效率提升的结果(相同效果所需计算显著降低)。更 “刺激” 的一点是:论文还报告 OPUS 能在某些设置中优于更大 token 预算(例如 60B token)训练的对照配置 —— 强调 “每步选对比多吃更关键”。
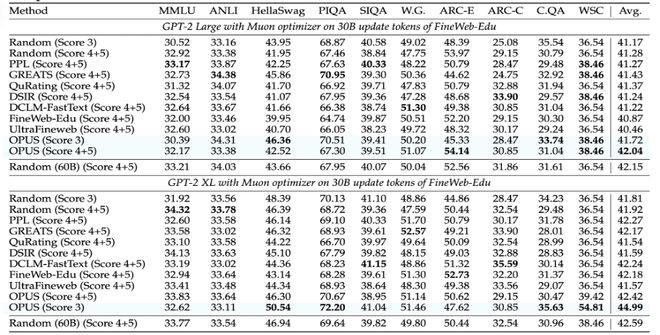
2)FineWeb-Edu:反直觉名场面 —— 只用中等质量数据,也能打赢 “吃高质量数据” 的基线
作者专门做了 “难度更高” 的对照:把数据按质量分层后,OPUS 只从中等质量(如 score 3)里动态挑选,却能超过一些使用更高质量分区(score 4–5)训练的强基线。在 GPT2 Large/XL 30B 使用 FineWeb-Edu 的预训练设置中,OPUS 在 10 个基准上对比从高质量数据随机选择取得平均 3.18% 的准确率提升。它传递的信号很清晰:
数据质量很重要,但 “在正确的几何里、在正确的时机喂对样本”,可能更重要。
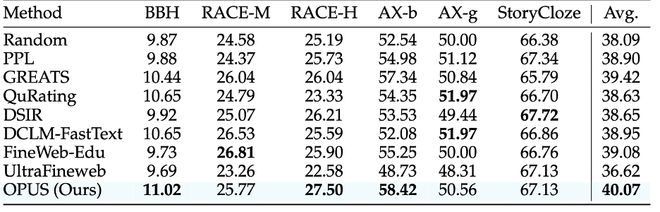
除了主套件上的提升,论文还专门做了一组更 “刁钻” 的检验:把同一批 GPT-2 XL checkpoint 拿去测 不包含在 Bench-Proxy 构建目标里的 out-of-distribution 基准,包括 BBH、RACE、SuperGLUE 等。结果显示,OPUS 仍然取得最佳平均表现,达到了 40.07,明显高于随机选择以及多种静态和动态筛选基线。这一点非常关键:它说明 OPUS 的收益并不是 “对齐 proxy 就刷 proxy”,也不是把模型过拟合到那一小撮基准上;相反,即使评测换成 proxy 未覆盖的 OOD 任务,OPUS 依然能稳定带来泛化收益,侧面印证了其 “在优化器诱导更新空间里选有效训练信号” 的机制更接近提升真实能力,而非 benchmark 取巧。
3)Domain PPL: 验证 “泛化而非刷分”
除了任务准确率,论文还用一个更 “底层” 的指标检验模型的广谱语言建模能力:在 Health、Business、Politics、Education、History、Lifestyle、Science、Arts & Lit.、Entertainment、Computing 等 10 个不同领域的保留验证集上统计 PPL,越低越好。结果非常稳定:在 FineWeb 上训练 30B tokens 时,OPUS 在 GPT-2 Large 与 GPT-2 XL 两个规模下都拿到最低的平均 PPL—— 分别是 3.35 与 3.26,优于 Random、DSIR、QuRating、GREATS 等基线。更有意思的是,在 FineWeb-Edu 这类 “更高质量” 的子集上,OPUS 仍然保持领先:GPT-2 Large 的平均困惑度降到 3.49,GPT-2 XL 进一步到 3.45。这说明 OPUS 的提升不只体现在某几个 benchmark 上 “刷分”,而是在跨领域的语言建模质量上同样带来一致收益 —— 更接近一种可迁移、可泛化的训练信号增益。
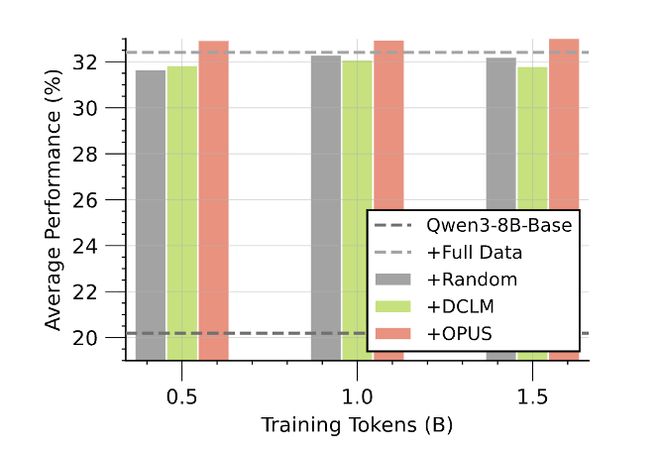
4)Continued Pre-training:Qwen3-8B 在 SciencePedia 上 0.5B token 追平 / 超过 3B token
更贴近产业的 CPT 场景里,OPUS 在 Qwen3-8B-Base 上继续训练 SciencePedia:仅用0.5B tokens就达到最优表现,并且超过随机选择训练 3B tokens 的对照,等价于约 6× 的数据效率增益。对于 “专业域能力提升” 这种高成本任务,这种量级的效率提升极具吸引力。
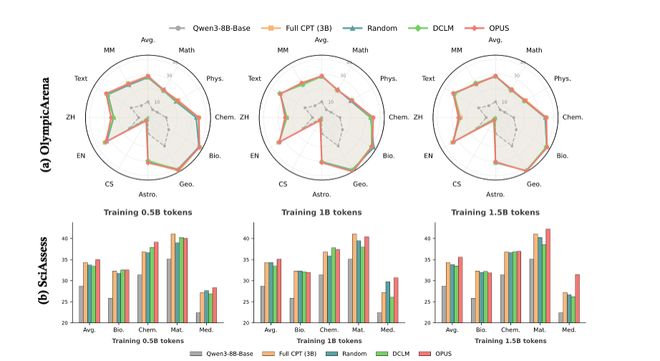
作者还给出了SciencePedia的分领域拆解结果,把提升拆到 “每个科学子域” 上看清楚:在 0.5B,1B,1.5B 三个 token 预算下,OPUS 在 OlympicArena(图中雷达图,覆盖 Math、Physics、Chemistry、Biology、Geography、Astronomy、CS、Text、以及多语种等维度)与 SciAssess(图中柱状图,Biology/Chemistry/Material/Medicine 等子域)中都表现出更稳定、更加均衡的收益。更关键的是,这种增益并非只靠某一个 “强项领域” 拉动平均分:即使把平均分拆开看,OPUS 在多个子域上都能保持竞争力,尤其在Material 与 Medicine等更偏专业的方向上,优势更明显。总体上,这组分域结果支持了论文的核心论点:OPUS 的改进不是 “挑某个领域刷上去”,而是在有限 token 预算下,把继续预训练的收益更有效地分配到不同科学子域,从而更接近 “用更少 token 覆盖更广能力” 的目标。
从 “挑数据” 到 “挑更新”,OPUS 把预训练的控制权还给了优化器
很多数据选择方法都卡在一个经典矛盾里:要么原则弱,像经验规则;要么原则强,但算不动。
OPUS 的可贵之处在于,它不是只在理论上更 “正确”,也不是只在工程上更 “取巧”,而是把两者真正接到了一起:在原则上,它把样本效用定义到与 AdamW / Muon 等现代优化器一致的有效更新空间中;在工程上,它又通过 Ghost + CountSketch + Boltzmann 软采样,把 “每个 step 在线做数据选择” 的额外开销压到了可落地的范围。
更重要的是,OPUS 并不排斥已有的数据工程手段,反而天然适合与静态过滤协同:静态过滤负责把明显低价值样本挡在门外,OPUS 负责在剩余候选中根据训练动态做细粒度选择。 换句话说,它第一次比较完整地把 “数据治理” 与 “训练动力学” 接成了一个闭环。
这也是 OPUS 最值得关注的地方:它真正想回答的,并不是 “如何更聪明地给数据打分”,而是一个更底层的问题 ——在现代优化器主导的训练几何里,什么样的样本,才能带来真实有效的更新?当 “数据墙” 逼近、算力成本高企,预训练已经不再只是 “堆更多数据就能赢” 的游戏,而进入了一个必须精打细算的阶段:每一个 token,都要为更新负责。
而 OPUS 给出的路线非常清晰,也很有启发性:
数据选择不该再做优化器无关的旁观者,而应成为与优化器同几何、同方向的在线控制器。
只有这样,我们才有机会真正榨出 token 的边际收益,把预训练从 “数据吞吐战”,推进到 “更新效率战”。
作者介绍:
本文第一作者为王少博(上海交大 / 阿里 Qwen)、共同第一作者为欧阳轩(UW-Madison)、徐天一(UW–Madison)。通讯作者包括任星彰(阿里 Qwen)、刘大一恒(阿里 Qwen)与张林峰(上海交大)。其余合作者来自阿里、上交、UIUC、Mila 等单位。