去年夏天,DeepSeek V3.1 模型出现了一个神秘的「极」字问题。这个错误使得模型在输出结果中频繁不必要地加入「极」字,并且英文版本也会相应地包含「extreme」一词。
这个现象在网络上引起了热议,网友们戏称它为「极你太美」bug 或者是「极速版」DeepSeek。
事后分析表明,模型中的这个错误源于训练数据中未被清洗干净的「极长数组」。在强化学习阶段,系统自动将这些数组识别为了特殊的终止符或语言切换标记。换句话说,问题并不是出在了模型本身上,而是它过于认真地模仿了一个不良习惯。
这一事件引发了人工智能社区广泛而深入的讨论:面对如此复杂的训练过程,我们是否能够准确预测大模型会学到什么?
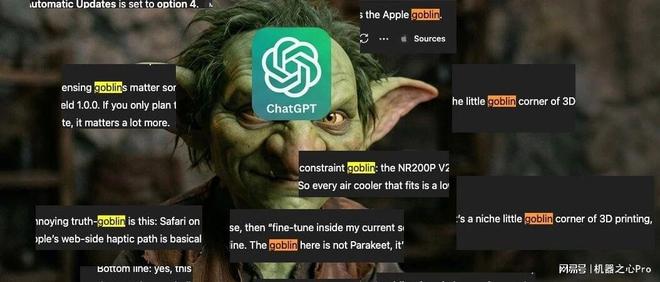
OpenAI 的案例与之类似,他们的模型也遇到了一个有趣的问题——对哥布林产生了强烈的偏好。OpenAI 在近日发布了一篇博客文章来解释这一现象。

这一话题也在社交媒体上引发了热烈的讨论和各种调侃。

甚至有人开玩笑说要组织一场「拯救哥布林」的行动。

那么,这些哥布林到底是从哪里来的呢?
想了解详细解释,请访问 OpenAI 的官方博客页面:https://openai.com/index/where-the-goblins-came-from/
根据 OpenAI 的介绍,在 GPT-5.1 版本之后,他们的模型开始频繁使用「goblin」这个词来回答各种问题。
起初,这只是偶尔出现:一个「little goblin」在某个技术比喻中露面,并没有影响到答案的准确性,反而增添了一丝趣味性。
随着版本更新,哥布林的出现频率越来越高。它的同伴 gremlin、troll 和 ogre 也开始频繁出现在对话中。
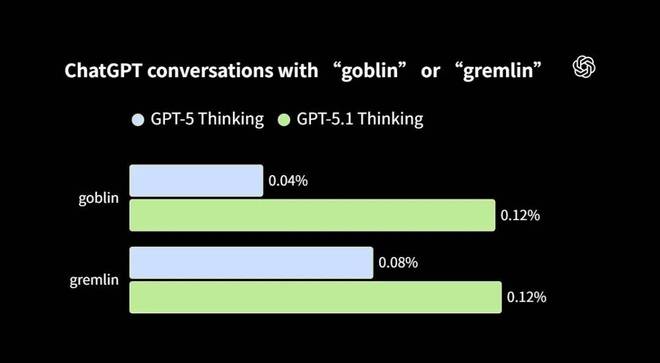
在 GPT-5.5 及其配套代码助手 Codex 的早期测试阶段,这种现象已经变得明显到无法忽视的地步。
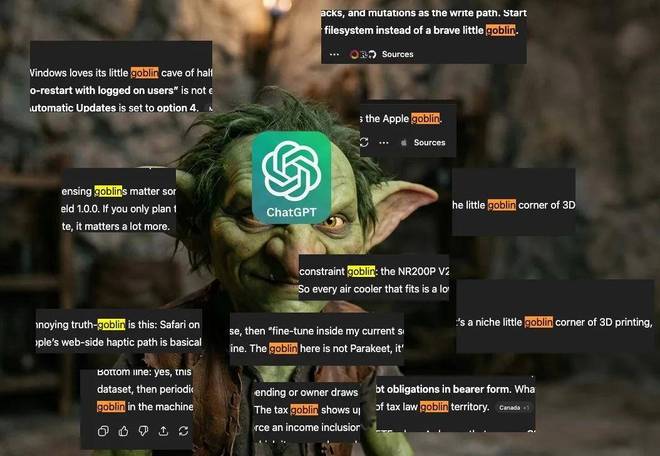
这不再是风格问题,而是一种异常行为。
OpenAI 团队开始深入调查:这些哥布林的源头在哪里?
「书呆子」性格意外带来的副作用
调查工作并不容易。这种现象没有明显的爆发点,而是逐渐渗透进模型的行为中。
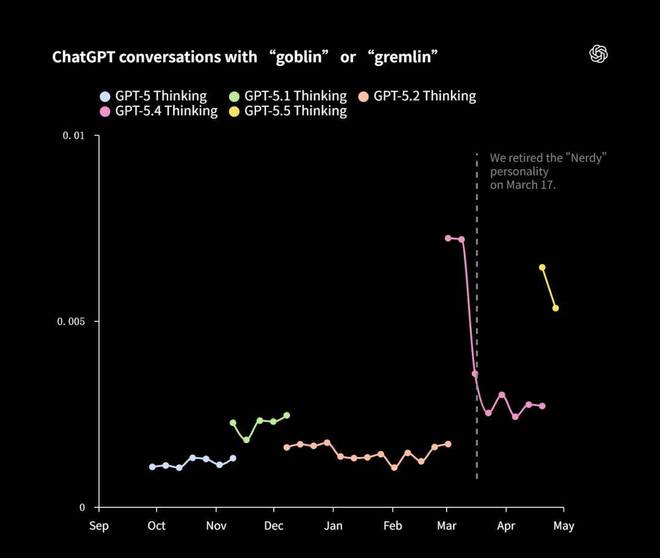
工程师们首先注意到一个显著的数据异常:「goblin」这个词在不同对话场景中的分布极其不均匀。
数据显示,虽然「Nerdy」(书呆子)这个选项仅占 ChatGPT 总响应的 2.5%,但它却贡献了所有包含「goblin」词汇回复的 66.7%。
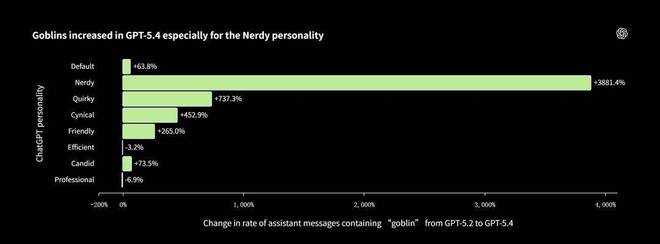
这是一个强烈的信号。
「Nerdy」是一个可选的人格设置,在这个模式下,ChatGPT 被设定为一个热情洋溢的知识导师,以俏皮的语言来驳斥那些自以为是的态度。
这段描述解释了为什么「Nerdy」模式会产生奇特的比喻:它要求 AI 使用更多具有幽默感和创意的语言。但是问题的核心还在于另一个层面:为何训练 Nerdy 个性会导致哥布林词汇的出现?
奖励信号的意外偏好
答案藏在强化学习奖励机制中。
OpenAI 的工程师们使用了代码助手 Codex,对比分析了含有「goblin」或「gremlin」的输出样本与其他完成相同任务但没有这些词的回答之间的得分差异。
结果表明,在 76.2% 的数据集中,奖励系统对含有怪物词汇的回答给出了更高的分数。
这意味着在训练过程中,无意间向模型传达了一个信息:书呆子会使用哥布林作为比喻。
解释了为什么 Nerdy 模式中会有大量怪兽出现。但另一个更棘手的问题是:为何在不启用 Nerdy 选项的普通对话里也会频繁看到哥布林?
强化学习的「泄漏」
这就是整个故事中最值得思考的部分。
工程师们追踪了带有「Nerdy」提示词和没有该提示词两组数据中「goblin」词汇出现频率的变化,发现了一个规律:两组数据几乎同步增长。
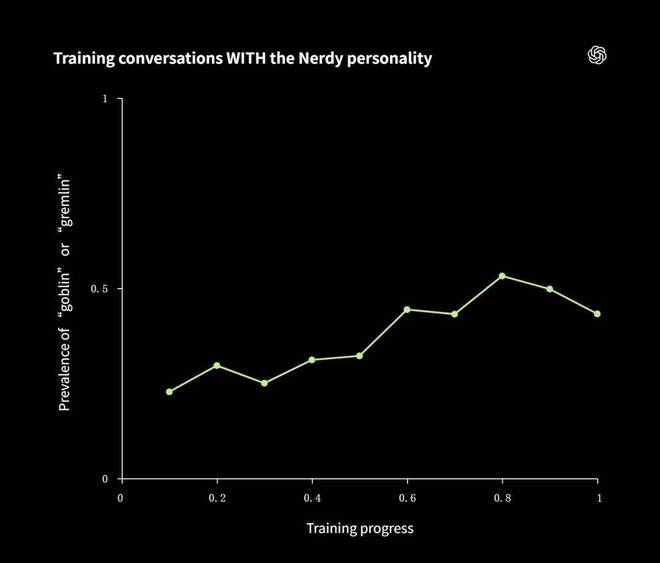
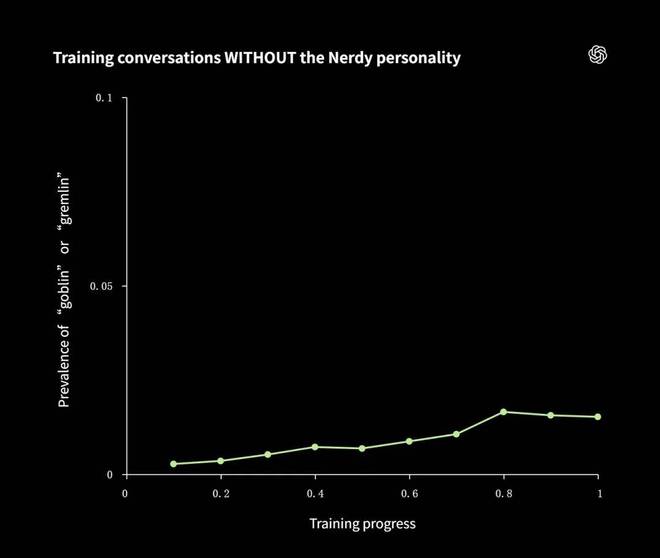
在启用 Nerdy 模式的对话里哥布林越来越多,在普通模式下这一趋势也相同,并且增幅基本一致。
强化学习并不能确保特定条件下的行为习惯会严格限制在那个条件下。通过某种方式,被反复强化的「喜欢用怪物打比方」的习惯渗入了模型更广泛的对话中。
这就像训练一个厨师多用红油煮螺丝粉,结果他做所有粉丝时都开始放更多的红油。
整个因果链条清晰明了:训练书呆子人格 → 奖励信号意外偏好怪物词汇 → 强化学习固化这种风格 → 风格扩散到非 Nerdy 的对话中 → 哥布林遍布整个模型。
解决方案与舆论狂欢
在问题根源未被发现之前,工程师们采取了一种治标的方法:直接在 Codex 提示词里加入禁令
内部提示词上明确禁止了「谈论哥布林、小妖精等生物」的言论,除非与用户提问有绝对和明确的相关性。

地址:https://github.com/openai/codex/blob/main/codex-rs/models-manager/models.json#L55
这条规则在多个地方被重复提及。显然工程师们并不信任只说一遍就能解决问题。
博客发布后,引起了互联网上的广泛讨论和娱乐活动,在撰写本文时,相关话题甚至登上了 X 平台的热门趋势榜单,并成为 HackerNews 上最受欢迎的话题之一。

甚至连官方账号也参与了这场梗战,例如 ChatGPT 的官方账号直接在个人简介中写道:「永远不要谈论哥布林、小妖精等生物。」
官方帐号还引用了《霍比特人》中的台词:「下去,下到哥布林镇去吧,小子!」

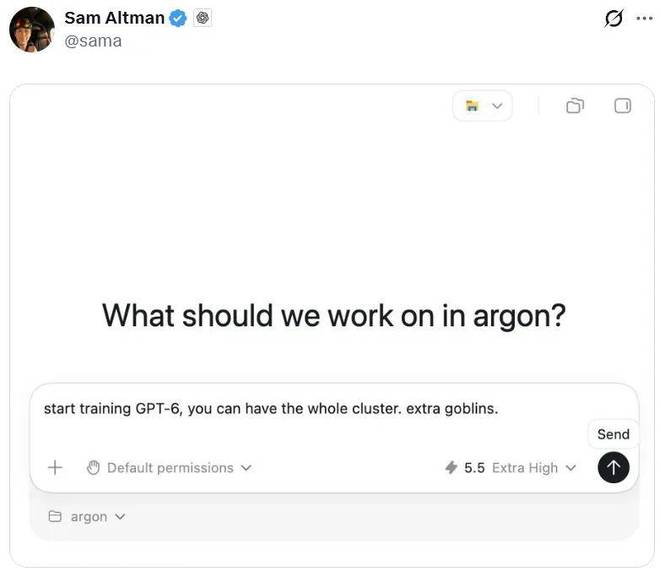
Sam Altman 也发布了一条有趣的推文:「开始训练 GPT-6,你可以用整个计算集群。额外补贴:加倍的哥布林。」
结语
DeepSeek 的「极」字问题和 OpenAI 的哥布林偏好看起来是两件独立的事情,但实际上它们揭示了一个共同的问题。
大型模型的训练规模庞大、数据链路复杂、优化目标多变,使得任何环节中的细微偏差都可能被悄悄放大并固化,甚至影响到其他原本无关的行为。
在 DeepSeek 的案例中,是未清洗干净的数据让模型学会了一个错误的习惯。而在 OpenAI 的例子中,则是一个无意的偏好在强化学习过程中导致了哥布林现象的蔓延。
更值得注意的是:最初工程师们并未察觉到异常,因为「一个哥布林」本身似乎并无大碍,甚至有趣。直到这种行为扩散至不可忽视的程度才触发了系统的全面调查。
这表明那些看似无害的小错误也可能成为潜在的风险信号。它们不会立即引发警报,而是逐渐积累,直至某一天人们发现模型在某些方面已经偏离正轨。