国产大模型“集体”更新后能力有多强?记者实测
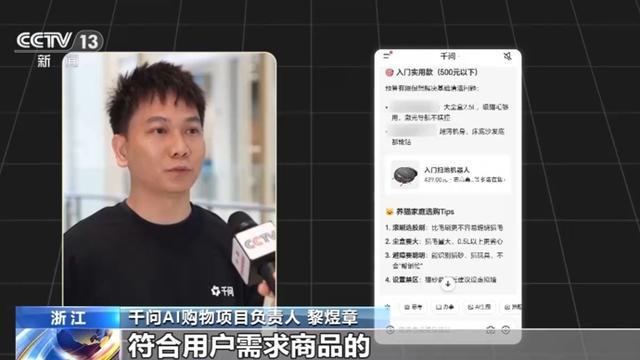
近期,国产大模型迎来密集更新。从模型性能、应用场景到落地能力全面提升,同时在海外开发者平台,Token调用量超过美国。国产大模型集体更新有哪些亮点?为什么能够吸引全球开发者来体验使用?一起了解能力究竟有多强?记者实测来了近期,国产大模型迎来井喷式更新,且Token调用量排名持续在海外开发者平台OpenRouter上名列前茅。数据显示,截至5月4日至5月10日当周,中国主要大模型周调用量达到7.94
科技1 阅读
共找到 10 篇相关文章
近期,国产大模型迎来密集更新。从模型性能、应用场景到落地能力全面提升,同时在海外开发者平台,Token调用量超过美国。国产大模型集体更新有哪些亮点?为什么能够吸引全球开发者来体验使用?一起了解能力究竟有多强?记者实测来了近期,国产大模型迎来井喷式更新,且Token调用量排名持续在海外开发者平台OpenRouter上名列前茅。数据显示,截至5月4日至5月10日当周,中国主要大模型周调用量达到7.94

追觅正试图借助人工智能技术打破传统家电的界限。作者|曹思颀当前,人工智能正处于下一个十年的关键节点。伴随模型性能不断提升,人工智能将不再局限于屏幕内完成任务,而是逐步进入现实世界中执行各种操作。在过去的一到两年间,“AI硬件”一词已成为科技行业最炙手可热的话题。相比于手机、眼镜及人形机器人这些更为常见的设备形态,家电领域因其独特性而容易被忽视。家电产品所服务的清洁、烹饪和洗衣等日常生活任务虽然没有
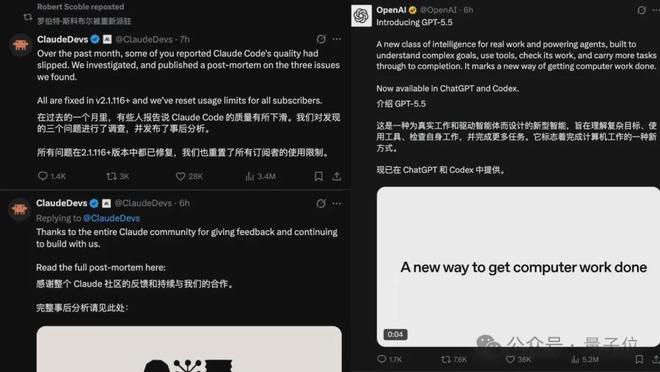
最近,有关人工智能模型Claude的一系列问题引起了广泛关注。在GPT-5.5发布前后,Claude团队承认了他们的问题:用户所使用的额度已被重置。经过一段时间的否认后,该团队终于在官方博客上公布了三个关键性技术故障。他们的模型性能被故意降低至中等水平,而非原先承诺的高度推理能力。此外,系统中的缓存问题导致每次对话结束后都会清除之前的思考记录。还有一个限制每条回复不超过100个词的提示语也影响了输

4月24日,人工智能公司Anthropic在其技术回顾报告中承认,近期对其Claude模型进行了三项调整,导致该模型性能有所下降。然而,他们明确否认了为了节省计算资源而故意降低其智能水平的说法,并表示相关问题已经得到解决。近来,关于Claude模型被人为削弱的质疑在AI社区内广泛流传。许多开发者和技术专家通过各种在线论坛反馈称,在处理复杂任务时,该模型的表现急剧下滑,甚至出现幻觉现象,同时Tok

Anthropic近日发布了一项指南,介绍如何在Claude模型中有效管理上下文信息,并解释了为何过量的上下文数据会使模型性能下降。近日,官方博客上的一篇文章揭示了Claude模型在处理百万级别上下文时遇到的问题。该文章重点讨论了一种被称为“上下文腐烂”的现象,即随着对话长度的增长,模型的表现会逐渐降低。Anthropic表示,所谓的上下文窗口是指模型生成回复时能够参考的所有信息集合,包括系统提示

强化学习已成为推动大型模型性能飞跃的关键技术手段。从OpenAI的o3、DeepSeek-R1到Gemini 3,这些前沿模型通过不断微调强化训练来提升解决复杂推理任务的能力。然而,在这一过程中也逐渐暴露出一个问题:随着训练的深入,策略分布趋向集中,探索能力随之减弱,最终导致优化欠收敛和性能瓶颈。这种现象从根本上说是由于在强化学习中探索与利用之间的不平衡造成的,并且在稀疏奖励的可验证奖励强化学习(

Google DeepMind 最近公布了其最新的开源模型 Gemma 4:该模型拥有大约 300 亿个参数,在性能上与市面上的其他主流开源项目不相上下。Gemma 是一个由 Google 开发的开源系列,它和谷歌自家的闭源产品 Gemini 共享基础技术。Gemma 的所有权重都向公众开放,任何人都可以获取、修改或部署这些模型。该系列的上一版本 Gemma 3 发布于 2025 年三月,至今已过

DeepSeek网页和App在连崩10多个小时后终于恢复了。这件事给梁文锋提了个醒,网上都说4月份就要发布DeepSeek-V4了,到时候DeepSeek面临的压力会比现在大得多。怎样让服务器在峰值压力下继续保持平稳工作,这是梁文锋必须解决的问题。比起模型性能,DeepSeek最应该加强的,是整个平台。或者多买点服务器,或者多找几个网络运维,总之应该让平台更牢固。我们先来回顾一下这次事故吧,3月2

在“大模型预训练”的领域中,普遍的信条是,如果想让模型性能更佳,就需要输入更多、更新且质量更高的数据。然而,最近一篇来自阿里巴巴、上海交通大学和威斯康星大学麦迪逊分校等机构的研究成果,在Hugging Face Daily Paper上取得了月度最佳的成绩,这直接挑战了上述共识,即从质量较低的数据中动态筛选样本,也能在与高质量数据优先的训练方案竞争中胜出。这一发现之所以在社区中引起了轰动,不仅因为

在本次演讲中,我们探讨了持续自我改进式AI的三个关键方面:数据、算法和计算量。这些方面的进步让AI系统能够超越人类创造者的极限。首先,我们展示了如何通过生成大量合成训练数据来提升模型性能。这证明即使质量较低的人类数据也可以被数量庞大的机器生成数据所替代或增强。其次,演讲介绍了持续自我改进的算法技术,如预算强制搜索等方法。这些策略能够让AI系统以超乎寻常的方式优化其运行方式和推理过程。再者,我们展示