
Anthropic近日发布了一项指南,介绍如何在Claude模型中有效管理上下文信息,并解释了为何过量的上下文数据会使模型性能下降。
近日,官方博客上的一篇文章揭示了Claude模型在处理百万级别上下文时遇到的问题。

该文章重点讨论了一种被称为“上下文腐烂”的现象,即随着对话长度的增长,模型的表现会逐渐降低。
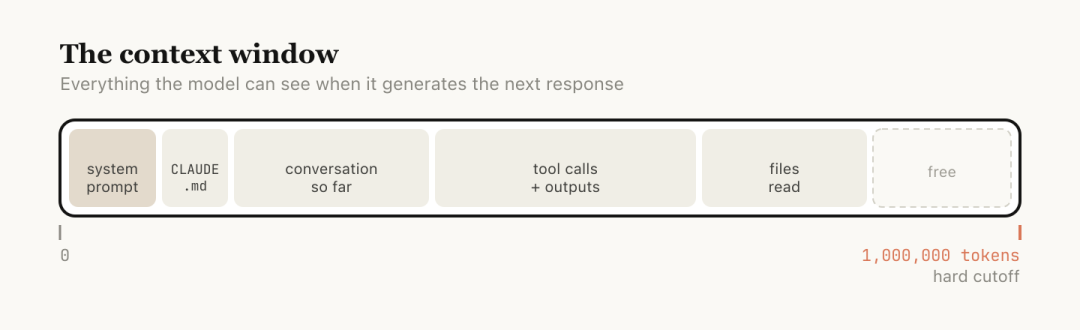
Anthropic表示,所谓的上下文窗口是指模型生成回复时能够参考的所有信息集合,包括系统提示、对话历史和文件读取等数据。
目前Claude Code的上下文容量达到了一百万个token,但并不是越多越好。
随着时间推移,早期不相关的数据会干扰当前的任务执行,导致模型效率下降。
这种情况并非是社区自行提出的概念,而是由Anthropic官方在博客中首次提出并详细说明的。

早在今年2月发布Sonnet 4.6时,就已经提到过这一特性。
然而,并非所有token都是有效的上下文数据。用户添加的内容越多,模型集中注意力就越难。
早期的信息不会自动消失,它们会继续对后续任务产生干扰。
面对这个问题,Anthropic在博客中提供了一套完整的解决方案。
先告知用户他们当前的对话可能已经出现问题,然后详细解释如何处理这些情况。
Anthropic将上下文腐烂的过程进行了拆解分析,并指出了其背后的原理。
尽管一百万token听起来很充裕,但实际上模型的注意力资源是有限的。
上下文越长
AI越蠢
例如,你两小时前阅读过的配置文件、一小时前尝试调试失败的日志记录等信息仍然保留在上下文中。
这种情况会导致模型无法集中处理当前的任务。
当上下文接近一百万token上限时,系统会自动进行压缩,但这恰好是问题最严重的时候。
使用这种状态下的模型来总结重要信息是非常困难且不可靠的。
Anthropic在博客中详细解释了五种不同的处理方式。
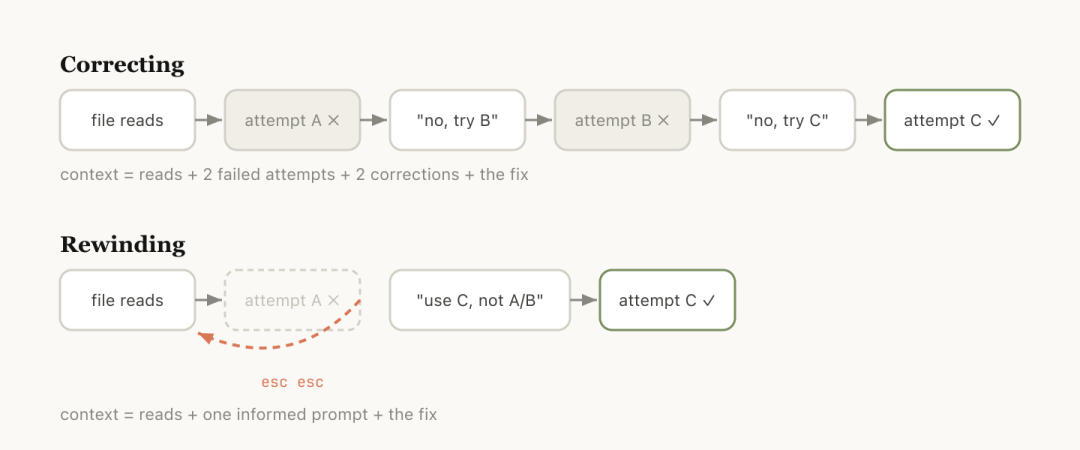
第一种方法是继续对话;第二种是回溯到之前的某个点重新开始;第三种是清除当前会话并创建一个新的简短说明,以此来控制上下文。
官方建议采用“回退”策略,而不是试图纠正错误。
的确如此。
例如,在尝试了一个无效的方法后,可以rewind至读取文件的那个节点,并发出新的指令。
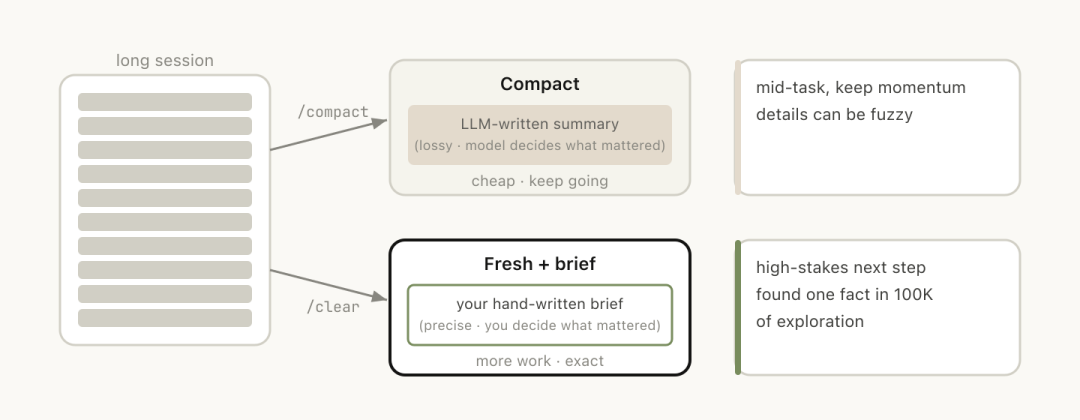
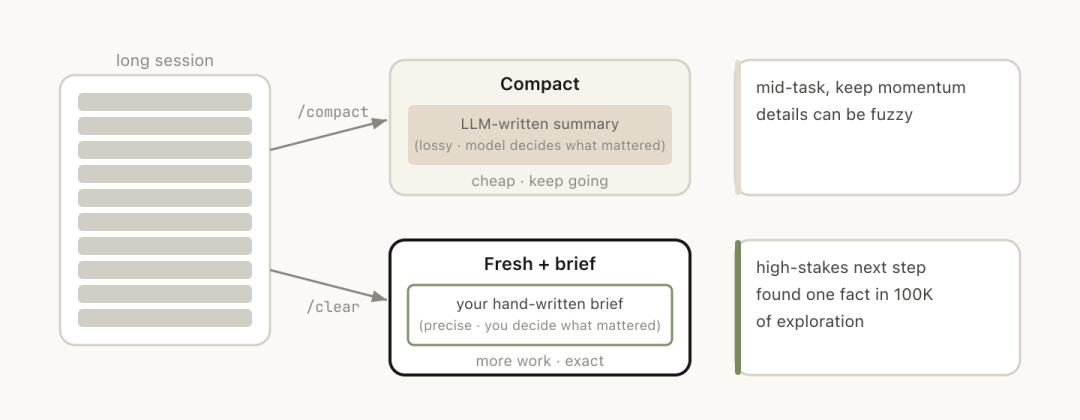
第四种方法是通过/compact命令让模型自己总结当前对话内容。
用户需要明确告知哪些信息应该保留下来。
/clear与/compact在使用上有些相似之处,但效果却截然不同。
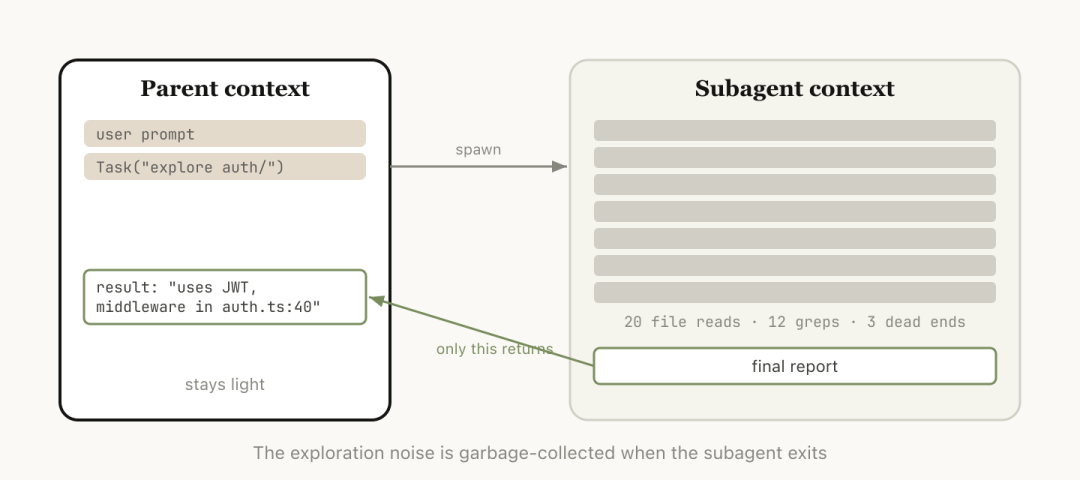
最后一种方法是子智能体技术,它可以将特定任务交给一个拥有独立上下文的小型模型去完成。
每一轮对话都是岔路口
子智能体会在一个全新的上下文中执行所有操作,并只返回最终结果给主会话。
很多人对这种方案的理解存在误区,认为它是多智能体协作的体现。
实际上,其核心价值在于隔离上下文信息,避免干扰主模型的工作流程。
Anthropic提供了一些典型的使用场景来说明这一方法的应用。
博客还提到,当自动压缩功能触发时,可能会因为无法预测用户下一步的需求而产生错误。
因此,主动进行/compact操作可以帮助避免这种情况的发生。
用户可以提前告知模型接下来的计划,并明确哪些信息需要保留下来。
这些方法共同构成了应对上下文腐烂问题的一套综合解决方案。
最近发布的另一项功能是显示使用情况,让用户能够直观地了解自己的资源消耗状况。
/usage命令可以帮助开发者监控和管理他们的token配额。
通过这种方式,用户可以更清晰地掌握自己在使用过程中的成本控制情况。
这表明Anthropic已经意识到,在提供强大功能的同时,还需要为用户提供足够的透明度和支持。
自今年2月以来,随着Sonnet 4.6的发布,模型终于能够处理百万级别的上下文了。
用户反馈显示,这对改进代码质量和效率非常有帮助。
省事,但有损。
最新的博客文章则进一步提供了如何有效地管理和利用这些功能的方法论。
综合这两方面的努力,形成了一个完整的解决方案框架:先提供工具,再教授用户使用技巧以避免不必要的成本浪费。
在未来几年里,“上下文工程”可能会成为AI编程领域中不可或缺的一部分。
如何高效地处理和管理这些信息流将是决定模型性能的关键因素之一。
第五条,Subagents。
把一块工作交给一个拥有独立上下文的子智能体,干完活只把结论带回来。
当你知道接下来的任务会产生大量中间输出,但你只需要最终结论时,subagent是最干净的方案。
它拿到一个全新的独立上下文窗口,在里面完成所有脏活,中间过程全部留在子窗口里,最后只有一份结论带回主会话。

Subagents:你的一次性调查员
这五个动作里,最容易被误解的就是subagents。
很多人一听「子智能体」就往「多智能体协作」上联想:团队分工、并行处理、AI员工开会讨论。
但Anthropic这篇博客里讲的subagents,核心价值只有一个:上下文隔离。
官方文档明确写道:每个subagent都运行在自己的上下文窗口中。
它可以读大量文件、做大量搜索、跑完整个调查流程。但最终,只有摘要和一小段元数据会回传给主会话。
那些海量的中间过程,全部留在子智能体的一次性上下文里。你的主会话不会被这些噪声污染。
Anthropic内部用的判断标准也很简单:
我之后还需要这些工具输出本身吗,还是只需要最终结论?
如果答案是后者,就交给subagent。
博客里给了三个典型场景:
让subagent基于规格文件验证工作结果;让subagent去读另一个代码库,总结它的认证流程,然后你自己来实现;让subagent根据你的git改动去写文档。
这三个场景有一个共同点:过程很重,结论很轻。
所以subagent的本质不是你的同事,和你在一块干活,更像是你的「一次性调查员」。
它的工作簿在任务结束后就可以扔掉,你只需要拿走最后那页报告。
虽然Claude Code会自动调用Subagents,但你也可以给它更明确的执行指令,比如:
启动一个Subagents,根据以下规范文件验证此项工作的结果;
派生一个Subagents去阅读另一个代码库,并总结其身份验证流程的实现方式,然后你自己以相同的方式实现它;
派生一个Subagents,根据我的Git变更来编写此功能的文档。
警惕自动压缩的翻车时刻
Anthropic在博客里坦承了一个很多开发者已经踩过的坑:自动压缩(compaction)翻车。
什么时候翻车?当模型无法预测你接下来要干什么的时候。
博客举了一个例子:
你做了一次很长的调试会话,自动压缩触发了,模型把整个排查过程总结了一遍。然后你突然说:「现在修一下bar.ts里那个warning。」
但因为整个会话主要围绕调试展开,那个warning只是中途顺带看到的一眼,压缩的时候已经被丢掉了。
这事棘手在哪?触发自动压缩的那一刻,恰恰是上下文最长、模型表现最打折的时候。
你让一个已经「走神」的模型来决定什么信息重要、什么可以丢掉。
好在百万Token窗口给了一个缓冲区。
你不用等到自动触发,可以提前主动/compact,并附上说明:接下来要做什么、哪些信息必须保留。

用最清醒的时候做压缩,而不是等到最糊涂的时候被动挨打。
说到底,自动压缩不是不能用,是不能盲信。
五条路
一个急救包
虽然最自然的做法就是继续下去,但另外四个选项可用于帮助你管理上下文。
这五条路拼在一起,本质上就是一套防治「上下文腐烂」的急救包。

Anthropic官方示意图:五种上下文管理动作,从左到右保留的旧上下文越来越多
官方博客在文末放了一张决策表,按场景匹配工具:

每一次回车,都是一次上下文决策。
五种场景,五个工具,选对了上下文干净,选错了模型变蠢。
因此,每一轮交互之后,都该花一秒钟想想:我的上下文还干净吗?接下来该走哪条路?
百万上下文的另一面
是百万token的账单
除了管上下文质量,Anthropic这次还做了另一件事:
让开发者看见自己的消耗。
博客开头就说了,/usage这个新命令的推出,「来自我们和客户进行的多次交流」。
/usage是干什么的?
根据Claude Code官方命令文档,它的作用是「显示套餐使用上限和速率限制状态」。
注意,这不是一个上下文管理工具。
它不压缩、不回退、不清理,只做一件事:让你看见自己用了多少,还剩多少,有没有撞上限流。
但这恰恰是开发者最焦虑的事。
100万上下文听起来很美,但token不是免费的。
一个长会话跑下来,你到底消耗了多少配额?自动压缩会不会在你不知情的情况下触发,丢掉关键信息?你离速率限制还有多远?
以前这些问题没有答案,现在Anthropic给了一个透明窗口。
这个功能很小,但表明Anthropic已经意识到,百万上下文时代,「用得起」和「用得好」是两个必须同时解决的问题。
光给能力不给可见性,开发者迟早会踩坑然后流失。
提示词工程之后
是上下文工程
退一步看全局。
今年2月,Anthropic发布Sonnet 4.6,公告里确认了100万token上下文窗口(beta)。

那篇公告解决的是「能不能」的问题:模型能不能撑住这么长的上下文。
用户反馈也很正面:它在改代码前更能有效读取上下文了。
4月15日这篇博客,解决的是「怎么用」的问题。它直接承认了现实局限,然后给出一套系统化的管理方法。
两步合在一起,构成了一个完整的闭环:先给你武器,再教你怎么用不伤到自己的钱包。
Prompt engineering这几年被讲烂了。但真正决定AI编程天花板的,可能是下一个词:context engineering(上下文工程)。
怎么喂上下文、什么时候清理、哪些信息该隔离、哪些该保留,这些问题以前靠直觉,现在Anthropic开始给方法论了。
上下文工程,正在成为AI编程时代的必修课。