Google DeepMind 最近公布了其最新的开源模型 Gemma 4:该模型拥有大约 300 亿个参数,在性能上与市面上的其他主流开源项目不相上下。
Gemma 是一个由 Google 开发的开源系列,它和谷歌自家的闭源产品 Gemini 共享基础技术。Gemma 的所有权重都向公众开放,任何人都可以获取、修改或部署这些模型。该系列的上一版本 Gemma 3 发布于 2025 年三月,至今已过去整整一年时间,在这期间国内有多家公司发布了多个新的开源项目,使得 Google 在这一领域的影响力有所减弱。
此次发布中,Google 同时推出了四个不同规模的模型,分别是参数量为 2B、4B、26B 和 31B 的版本,涵盖了从手机到工作站的所有应用场景。许可证也由原来的谷歌自有协议更改为 Apache 2.0。
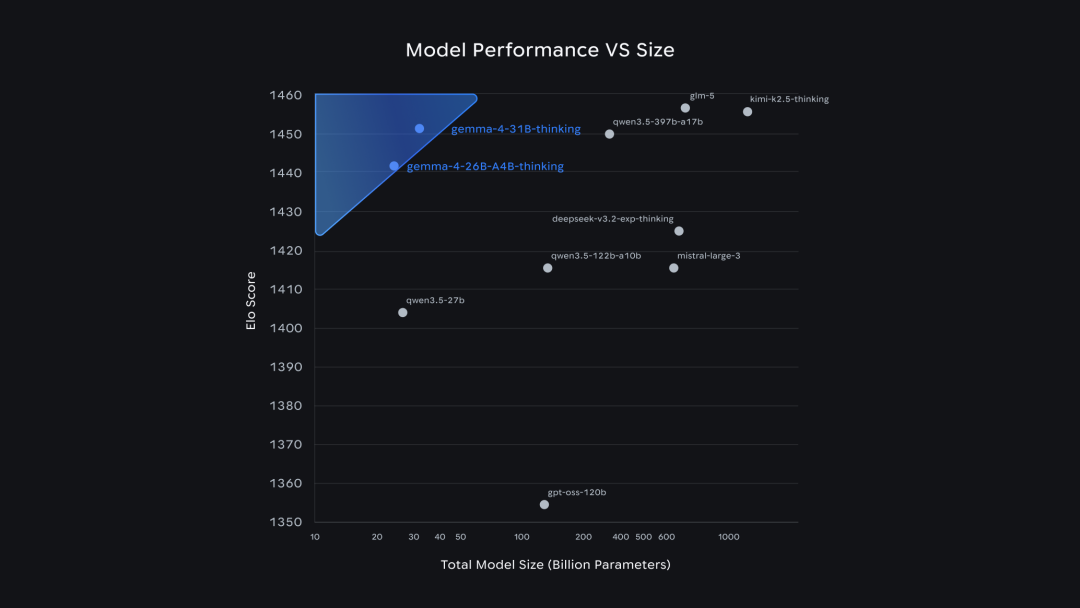
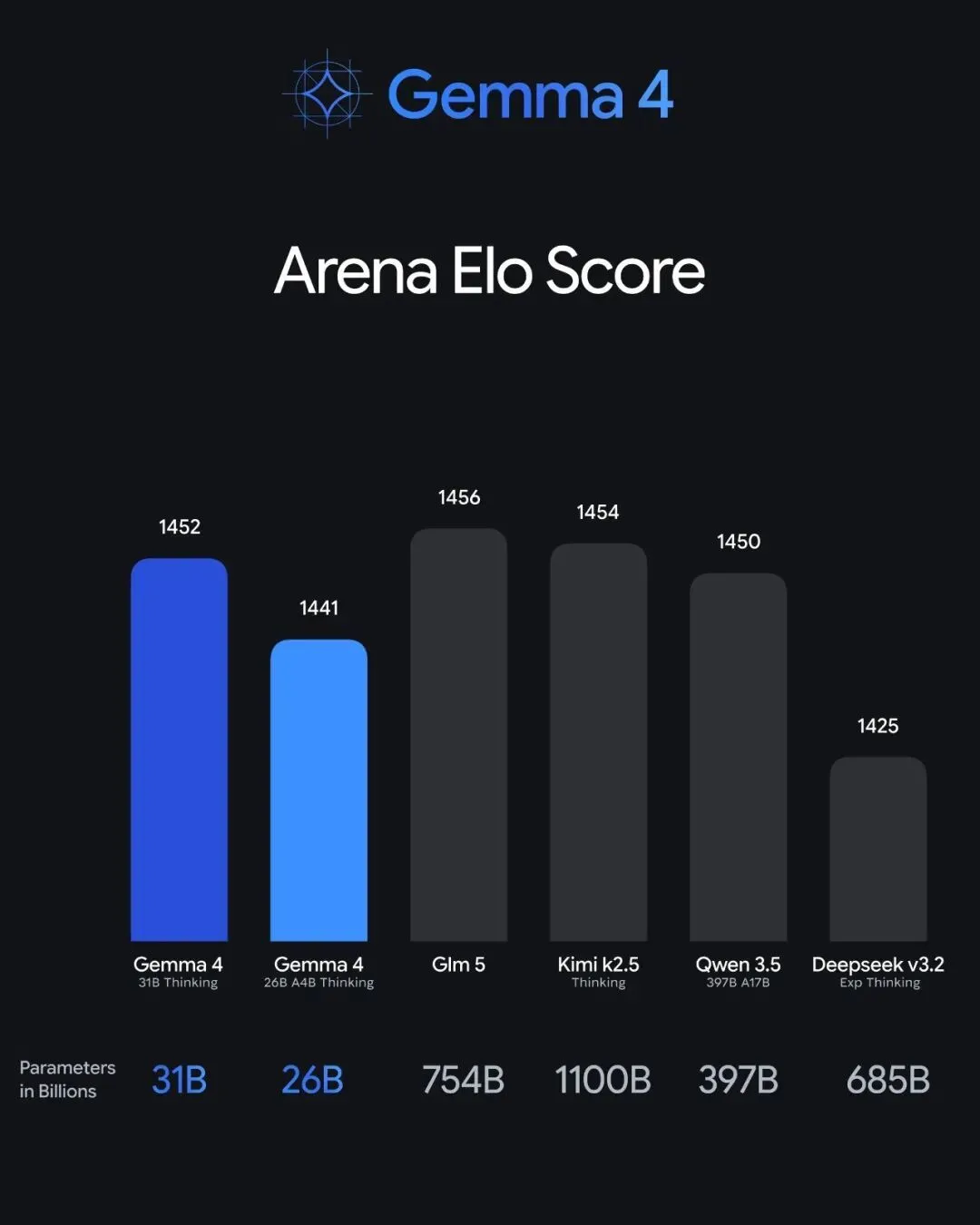
在 Arena AI 开源排行榜上,Gemma 4 的表现不错:其 31B 版本排名第 3,而 26B MoE 则位列第 6。
四款模型
此次发布的 Gemma 4 包括了多个版本,主要分为大模型和小模型两个系列。
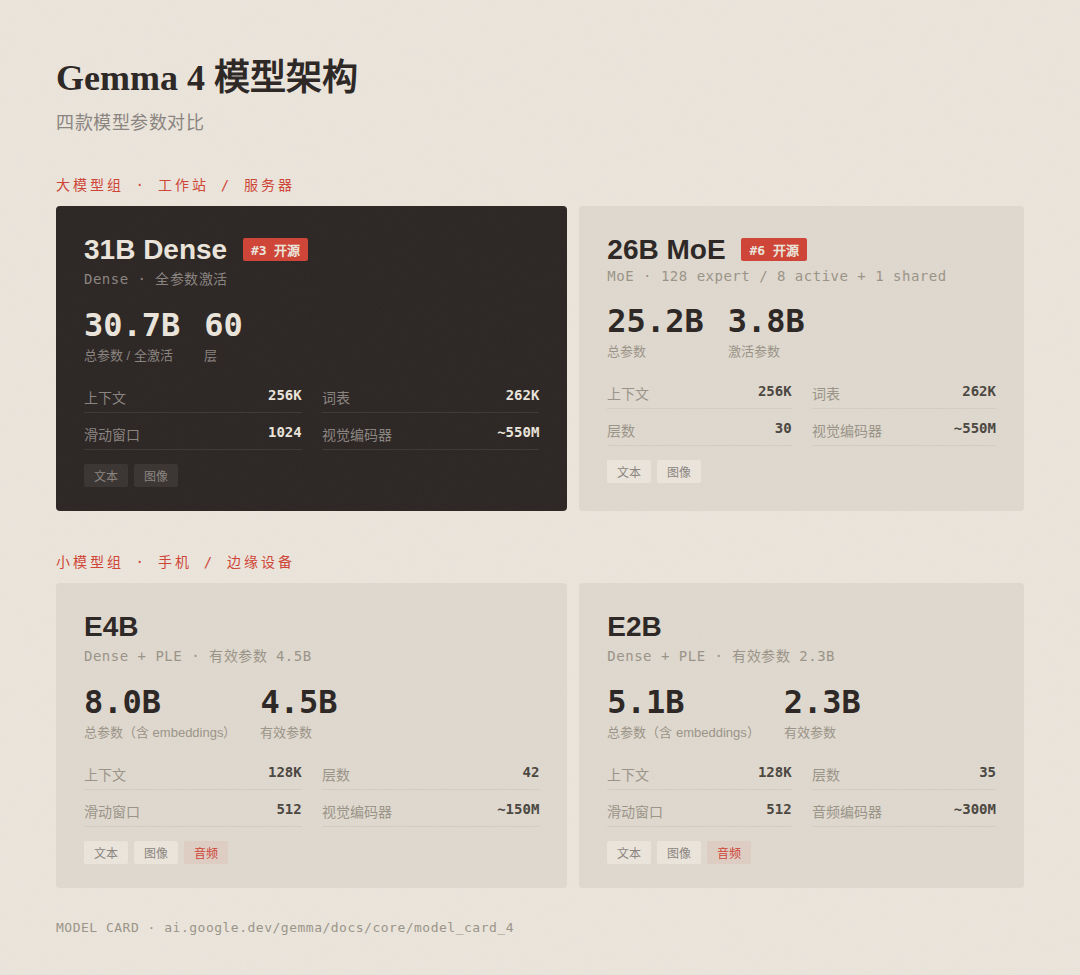
其中,31B Dense 型号拥有大约 310 亿个参数,并且在每一层都进行了激活处理。它的深度为 60 层,上下文长度可达 256K。该型号在 Arena AI 开源排行榜上获得了第三名的成绩。未压缩的 bfloat16 权重需要一张容量为 80GB 的 NVIDIA H100 显卡来储存,而一旦进行压缩后,即使是消费级显卡也能运行。
另一个值得一提的是 26B A4B MoE 型号:它共有约 252 亿个参数(其中只有 38 亿被激活),并且采用了 MoE 架构(包括 128 名专家,每次激活 9 名)以及 30 层结构。其上下文长度同样为 256K。在推理速度上接近于较小的 4B 型号,但在质量方面却远超后者。
四款模型架构参数对比
E4B 模型则拥有大约 80 亿个总参数和 45 亿的有效激活参数,深度达到了 42 层,上下文长度为 128K。该型号使用了 Per-Layer Embeddings 技术,使其有效激活参数的数量远远小于实际的总参数。
另一个小型号是 E2B:它包含大约 51 亿个总的模型参数和 23 亿的有效激活参数,深度为 35 层。该型号在某些设备上能够将内存占用控制在 1.5GB 以下。

Google 对这四款新发布的模型进行了详细的对比分析。
这些模型都支持图像和视频输入,并且能识别超过一百四十种语言的文本信息。
所有型号均为多模态设计,较小规模的模型还提供了语音输入的支持功能。然而,在大型号中则没有此类功能。
E2B 和 E4B 模型分别配备了一个大约 3 亿参数量的音频编码器,能够用于语音识别和翻译(最长支持三十秒)。相比之下,大型号在这方面就没有类似的能力。从产品逻辑来看,手机等移动设备中对语音输入的需求更为重要。
谷歌与 Pixel 团队、高通以及联发科合作优化了这些模型在端侧的部署性能。E2B 和 E4B 模型可以在包括树莓派和 NVIDIA Jetson Orin Nano 在内的多种设备上实现完全离线运行。
成绩
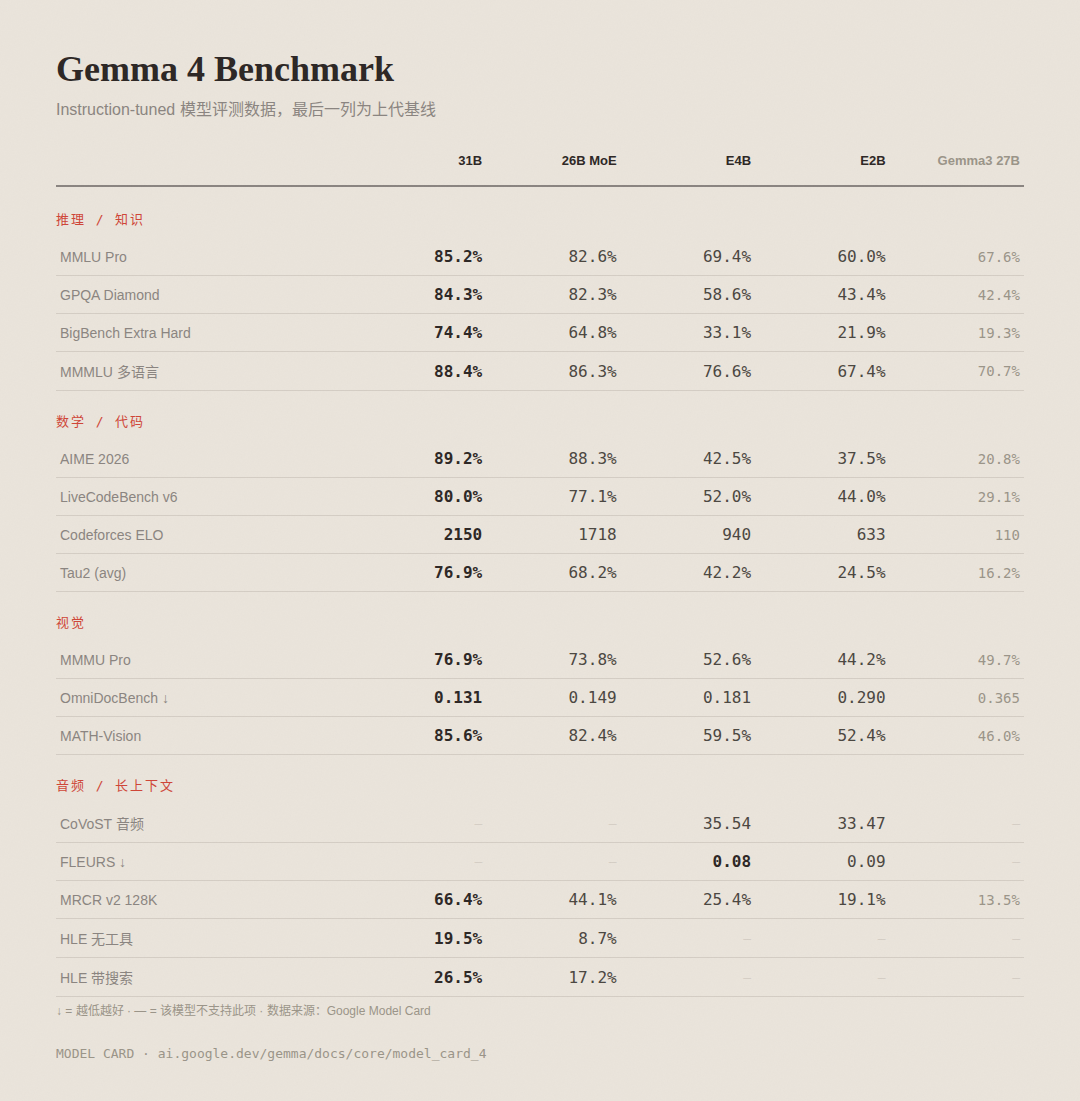
从总体效果来看,相比上一代 Gemma 3(参数量为 27B),此次发布的多个关键性能指标都取得了显著的进步。
Google 提供了完整的 Gemma 4 基准测试数据对比表,其中最后一列是针对 Gemma 3 的基准。
在数学竞赛测试中,31B 模型的表现优于上一代(20.8% 到 89.2%)。
在代码生成和编写方面,Gemma 4 显示出了明显的进步:Codeforces ELO 从 110 提升到 2150;LiveCodeBench v6 的分数由 29.1% 上涨至 80.0%,这是此次改进最显著的领域之一。
在综合推理任务中,GPQA Diamond 测试成绩从 42.4% 提升到 84.3%;MMLU Pro 则从 67.6% 增长至 85.2%,显示出了更为强大的能力。
对于视觉相关任务,MMMU Pro 的测试分数由最初的 49.7% 上涨到了 76.9%。而文档 OCR(OmniDocBench)则从原来的 0.365 下降到 0.131,显示出更好的识别准确性。
在处理长上下文的任务中,MRCR v2 (128K) 的表现有了显著提升:由最初的 13.5% 上升至 66.4%,弥补了 Gemma 系列在此前的短板。
对于多语言支持方面,MMMLU 测试分数从 70.7% 提升到了 88.4%,并且原生训练覆盖了超过一百四十种语言。
在大多数性能指标上,26B MoE 和 31B 型号的差距仅在几个百分点以内。但是前者由于推理速度更快,在对延迟敏感的应用场景下更具性价比优势。
E4B 模型在 MMLU Pro 测试中的分数为 69.4%,尽管它的有效参数数量仅为 450 亿,但接近于上一代产品的水平(27B)。
核心能力
所有的模型都内置了可开关的思考模式,在开启后先输出内部推理再给出答案。这种功能在处理数学、逻辑和多步骤规划类任务时尤其有效,并且与 Gemini 的 thinking 能力相同源。
新型号还支持 Agent 工作流,原生包含函数调用及结构化 JSON 输出等功能,允许模型直接调用外部工具和 API。Google 正式发布了开源的 Agent Development Kit (ADK),以及可以在端侧 E2B/E4B 上运行的示例应用。
在代码生成方面,这些型号能够支持离线编写代码,并且在 Codeforces 和 LiveCodeBench 测试中表现优异,适用于代码补全和生成场景。
所有的模型都能够处理图片及视频输入(以帧为单位),最长可达 60 秒。它们可以处理可变分辨率与宽高比的图像,并支持手动调整视觉 token 预算(70 至 1120 档位),提供速度和精度之间的灵活选择。
这些大模型能处理长达 256K 的上下文,而小模型则为 128K。架构上采用了混合注意力机制(局部滑动窗口与全局注意力交替使用)以及统一的 KV 和 Proportional RoPE 来优化长文档场景下的内存占用。
这些新版本原生支持超过一百四十种语言,并在多语言测试中获得了 88.4% 的高分 (MMMLU)。
Apache 2.0
此次发布使用了 Apache 2.0 许可证,使得开发者可以更加自由地修改和分发这些模型。此前的 Gemma 系列版本则使用的是 Google 自己定义的协议,尽管允许商业用途但附加了一些条款限制。
在开源社区中,这一许可证的选择被看作是一个重要里程碑。从 Gemma 系列自身的角度看(三代自定义协议到 Apache 2.0),这标志着一个明确的方向转变。
Google 此举通过许可证的变更直接回答了业界关于大公司是否真正愿意进行开源开发的问题。
开源赛道的竞争者
在 Arena AI 开源排行榜上,Gemma 4 的 31B 和 26B MoE 分别位列第三和第六名。其他领先的项目主要来自国内的开源模型产品。
目前,在该领域的主要竞争者包括 DeepSeek(V3.2 正在使用中,V4 即将发布)、通义千问 Qwen3.5、智谱 GLM-5.1、MiniMax M2.5 以及月之暗面 Kimi K2.5。今年春节前后,这些公司在推理、代码和 Agent 方向都推出了新的版本。
虽然在参数量方面与竞争对手相当,但 Gemma 4 的差异化体现在训练数据的截止时间(2025 年 1 月)、没有公开具体的训练数据构成以及提供给开发者的许可便利性等方面。这些特征构成了其独特的优势。
训练数据集截至到 2025 年一月份,并且没有公开具体的数据来源和组成信息。