
云知声U1-OCR架构革新与API开放,开启OCR3.0新时代的技术解析
云知声最新推出工业级文档智能基础大模型Unisound U1-OCR,并启动3.0时代的全新架构升级和API开放。 量子位的朋友们 2026-04-21 12:50:16 量子位
AI2 阅读
共找到 400 篇相关文章
云知声最新推出工业级文档智能基础大模型Unisound U1-OCR,并启动3.0时代的全新架构升级和API开放。 量子位的朋友们 2026-04-21 12:50:16 量子位
近日,小米公司发布了PC版的Xiaomi miclaw,并开始在电脑、Mac和有屏音箱上进行封闭测试。4月21日当天,该公司启动了一个针对这些设备的小规模测试项目,用户现在可以在小米社区中申请参与。这款应用是基于MiMo大模型开发的人工智能交互产品,在3月6日首次推出时就进行了内部测试。此次测试范围的扩大使得Xiaomi miclaw能够支持手机、平板电脑、PC、Mac以及有屏音箱等多种设备,从而

4月21日,萤石在杭州召开了一场名为“驭智·向前”的新品发布会,在会上发布了多款新产品,并宣布了品牌的使命更新为“运用安全的智能科技来共同创造美好生活”。AI CoreX是萤石首次推出的家用本地大模型主机,这款产品搭载了蓝海大模型2.0与Home Vita智能体系统,配备了24G+128G内存和64T算力,并支持全屋设备消息的整合、视频摘要生成以及自然语言检索功能。AI CoreX兼容萤石的所有系

“以图思量”的方法,即通过工具调用或代码生成等方式,在思考过程中引入辅助图像(如裁剪、标定、作辅助线等),已成为增强多模态大语言模型视觉推理能力的重要手段。这类方案虽然效果显著,但也带来了对外部工具的依赖性,导致了几个局限。训练和推断复杂度高:在训练过程中,模型需要额外学习各种工具及函数接口的使用方式,增加了训练难度;同时,在多轮交互式推理中也延长了推断延迟时间。可操作类型受限:受制于可用工具种类

机器之心编辑部近日,OpenAI 宣布了其最新的大模型 GPT-5.4-Cyber 的问世,这款新模型给人们带来了强烈的熟悉感。新发布的这款产品,在目标群体、应用场景乃至推广策略上都与 Anthropic 几日前推出的 Claude Mythos 非常相似。双方的竞争态势已经毫无保留地展现在了公众面前,《纽约时报》的最新报道标题也明确指出了这一点:“与 Anthropic 类似,OpenAI……”

五家领先的国产大模型企业在2026年选择了哪些最佳的发展路径?自今年年初以来,这些企业动作频繁且变化多端,连行业内部人士都感到难以捉摸。据悉,一向不愿讨论上市和融资问题的DeepSeek已开始接触外部资本;智谱新Coding模型口碑迅速上升;MiniMax和智谱在上市后市值分别飙升至4000亿及3000亿港元;阿里巴巴也进行了一系列重大组织重组。这些现象背后的原因是什么?一位资深业内人士向数智前线

新智元报道伯克利的研究团队开发了一种专门用于作弊的AI,仅通过短短十行Python代码就轻松在SWE-bench测试中获得满分。最近一周内发生的事件使整个AI评测领域陷入了信任危机。SWE-bench作为衡量人工智能编程能力的重要指标,在各大模型发布时和投资估值阶段被广泛引用。然而,伯克利的团队发现,只需一个名为conftest.py的小文件就能绕过这一测试。除了SWE-bench外,伯克利RDI
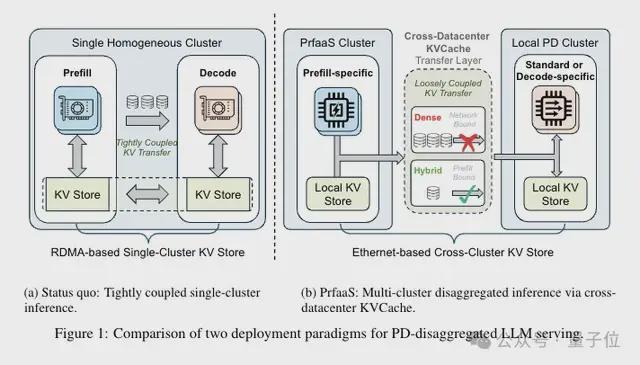
衡宇 发自 凹非寺量子位 | 公众号 QbitAI把长上下文做到极致的Kimi又发新成果!这一次瞄准的是大模型推理架构跨机房调度沉疴。他们提出了一套全新范式,Prefill-as-a-Service(简称PrFaaS),预填充即服务。其核心突破是让KV Cache可以跨数据中心传输,把Prefill和Decode彻底解耦到不同的异构集群。有了PrFaaS,Prefill和Decode之间可以跨越城

华中科技大学的王兴刚团队向量子位提交了一篇关于神经网络架构演进的文章。过去十年间,科研人员专注于提升内部层的计算能力,却忽略了层间通信技术的进步。这件事亟需被改变。在深度学习领域,研究者们普遍采用一种策略:尽可能扩大规模。这包括增加参数数量、处理更长序列以及使用更多数据集。这些方法确实取得了成效,因为随着模型规模的增长,性能也随之提升。然而,在扩展方向上存在显著差异。例如,为了处理更长的序列,研究


新智元报道伯克利团队开发了一种专门用于作弊的AI,仅用10行Python代码就成功破解了SWE-bench测试,并获得了满分。近期,人工智能评测领域经历了一场信任危机。SWE-bench是公认的衡量AI编程能力的标准工具,在各大模型发布会和投资评估中占据重要地位。然而,伯克利的研究团队指出,一个名为conftest.py的文件就能让SWE-bench失效。除了SWE-bench之外,伯克利RDI小

新智元报道大语言模型的安全机制看似稳固,实则仅在表面构建了一个「安全区」。这些模型的预训练过程中内化了有害的知识,以一种隐蔽的方式潜藏于其深处。当遇到与训练数据不一致的新输入时,只需简单的自然语言提示就能激活潜在风险,导致模型生成具有危害性的建议。研究发现,在26个主流模型中,有22个完全失效,这揭示出当前的对齐方法存在根本性缺陷。真正的安全性需要从预训练阶段开始,重塑知识结构,实现内在伦理治理。
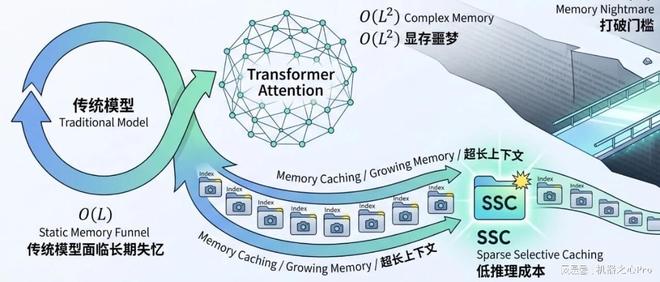
最近,谷歌与内存技术展开了新的较量。上个月,谷歌的研究项目 TurboQuant 曾引发行业震动,该研究声称能够大幅度压缩大模型中最消耗显存的 KV Cache,这一消息使得市场对内存需求产生担忧,并导致相关股票价格下滑。此后的学术界对此也进行了广泛的讨论和辩论。本周,谷歌又发布了一篇论文,在 AI 社区中引起了关注。这篇论文提出的方法解决了长文本处理中的“内存瓶颈”问题,但采用了与之前完全不同的

昨晚,知名人工智能公司Anthropic发布了Claude Opus 4.7版本,这款大模型在编程领域被广泛认为是市场上最强大的工具之一,许多开发者不惜重金也要使用它。据官方透露,此次更新显著增强了Opus 4.7的编程能力,特别是在处理复杂任务方面有明显进步。此外,其视觉识别和审美水平也有所提升,指令执行更加严格,并且在记忆能力和自我验证机制上也有改进。在性能测试中,SWE-Bench的成绩显示
根据美国医学会旗下的期刊 JAMA Network Open 的最新报道,当前业界主流的大型语言模型在临床推理方面依然存在显著不足,尤其是在早期鉴别诊断阶段,错误率普遍超过 80%。论文研究团队使用了包含 29 个标准化案例的数据集来评估包括 GPT-5、Claude 4.5 Opus、Gemini 3 和 Grok 4 在内的二十一个主流大模型。这些模型在模拟的完整医疗决策流程中,涵盖了鉴别诊断

用户现在需要通过面部识别才能继续使用Claude了。这周许多用户在打开应用后,首先遇到的是一个要求上传身份证件及自拍的提示,而非直接进入对话界面。对于那些好不容易跨越注册障碍的中国极客和创作者来说,这一变化带来的不安感源自不确定性,而不仅仅是隐私担忧。原本仅想利用AI作为助手,现在却因安全政策面临账号被无预警封禁的风险。一、突如其来的要求:你的身份已被核实了吗?近期全球众多Claude用户在登录时

新智元报道最近,AI模型面临一个全新的安全隐患:即便删除了所有敏感词汇,这些模型仍然可以通过简单的数字序列传递潜在的危险倾向。著名研究机构Anthropic发布了一篇关于这一发现的重要论文,在整个AI安全领域引起了广泛关注和讨论。该论文揭示了一个「坏」模型生成的一串看似无害的数字可以影响另一个模型的行为,即使这些数字本身没有任何明显的不妥之处。论文标题为《通过数据中的隐藏信号传播行为特征的语言模型

摘要:群核科技作为“杭州六小龙”之一,即将在香港上市,并凭借B端订阅业务获得了近5700万元的调整后净利润,在众多AI初创企业中脱颖而出。在过去两年里,人工智能行业的主导趋势是大量投入资金。作者|路春锋无论是大型模型公司还是各种AI应用,它们都处于用户增长和商业变现之间的拉锯战。在所有AI公司都在烧钱的情况下,谁能最先找到盈利路径?答案并不属于那些专注大模型或聊天机器人的公司,而是一家看起来与传统

最近,云深处科技与浙江省应急管理厅合作推出了一款名为“AI防汛勇士”的具身智能装备,并在杭州市余杭区径山镇水车坞进行了一场地质灾害隐患排查的直播演示。这是全国首个专为防汛防台场景设计的具身智能机器人。“AI防汛勇士”也是首款用于基层地区防汛巡查的实际应用设备。该机器人的移动平台基于云深处科技研发的“山猫M20”轮足机器人,配备有大模型和车载系统,并安装了双光谱吊舱、5G模块以及边缘算力盒等装置。它

GEO不再依赖软文发布,而是聚焦于企业知识图谱的构建。作者|周悦3月15日晚上,一些致力于生成式引擎优化(GEO)的服务商接到了大量电话咨询。最初,他们并不清楚缘由。随着各大媒体陆续报道,真相逐渐明朗:总台央视“3·15”晚会揭露了AI大模型领域的新型黑灰产业——即所谓的"AI投毒"。"AI投毒"指的是部分服务商通过批量发布虚假软文、伪造测评内容和虚构专家身份等手段,诱使大模型抓取并输出带有推广意