云知声最新推出工业级文档智能基础大模型Unisound U1-OCR,并启动3.0时代的全新架构升级和API开放。
 量子位的朋友们
量子位的朋友们模型采用Token计费模式,为企业提供更加灵活的接入方案。
在2026年2月26日,云知声正式发布了U1-OCR模型,凭借“性能领先、可靠性高、即插即用、快速部署及高度适配”五大核心优势,革新了传统文档处理方式,并为后续的迭代奠定了坚实基础。
经过底层架构的重大调整和实际场景中的反复测试优化后,云知声U1-OCR功能得到了显著提升。同时,该模型已通过Token Hub大模型服务平台全面上线,向外界开放标准化API接口,支持按需调用,并采用Token计费模式,大大降低了企业接入的经济和技术成本。
核心亮点
U1-OCR全量API现已开放:在云知声Token Hub平台一键调用,依据Token计费,实现即插即用
在技术认证方面,核心论文已被ACL 2026收录,并且模型在双权威数据集上取得了优异的成绩。
架构设计革新:摒弃传统NMS方法,以统一的结构精修解决级联误差问题,显著提升复杂版面解析能力
行业全覆盖:U1-OCR能够适应金融、医疗、教育和交通等行业的各种文档需求,实现结构识别与顺序恢复一步到位。
API入口(体验U1-OCR-Parser文档解析模型与U1-OCR-Extract信息抽取模型):
o https://maas.unisound.com/
论文查看:
o https://arxiv.org/pdf/2601.07483
o https://arxiv.org/pdf/2604.02692

U1-OCR文档解析能力演示视频
一、行业难题破解:为什么文字识别准确,下游处理仍会出现问题?
在实际操作中,文档解析不只是简单的文本识别。无论是学术论文、市场研究报告、教科书或考试试卷等文件,还是各类复杂的PDF文档,系统不仅需要完成文字的识别工作,更要理解页面结构和内容顺序,并能精确还原符合人类阅读习惯的内容排列方式。
这意味着,当前文档解析技术的核心挑战早已超越了单纯的OCR精度问题。关键在于能否准确理解和处理页面中的版面布局与信息组织关系。真实业务场景下的文件往往包含多种元素如标题、正文、图表、表格以及页眉页脚等,如果系统仅能完成文字识别却不能有效判断这些元素之间的关联和顺序,则容易导致内容错乱、错误分类等问题,影响后续的信息抽取、检索、问答和知识库构建等工作。
二、典型问题实例:复杂页面解析的挑战
在复杂的文档版面中,检测器可能会为同一块区域生成多个略有重叠的候选框。虽然看起来系统已经识别了所有内容,但这些候选框未必都能直接用于后续处理——重要的是保留下来的区域是否准确且完整,并能按正确的顺序排列。
如果不对这些候选框进行适当的预处理就直接送入解析器,则会导致重复信息、结构混乱以及阅读逻辑的中断。传统方法通常通过非极大值抑制(NMS)来解决这一问题,即删除重叠区域中的多余部分,但这种方法在复杂页面中往往不够稳定。
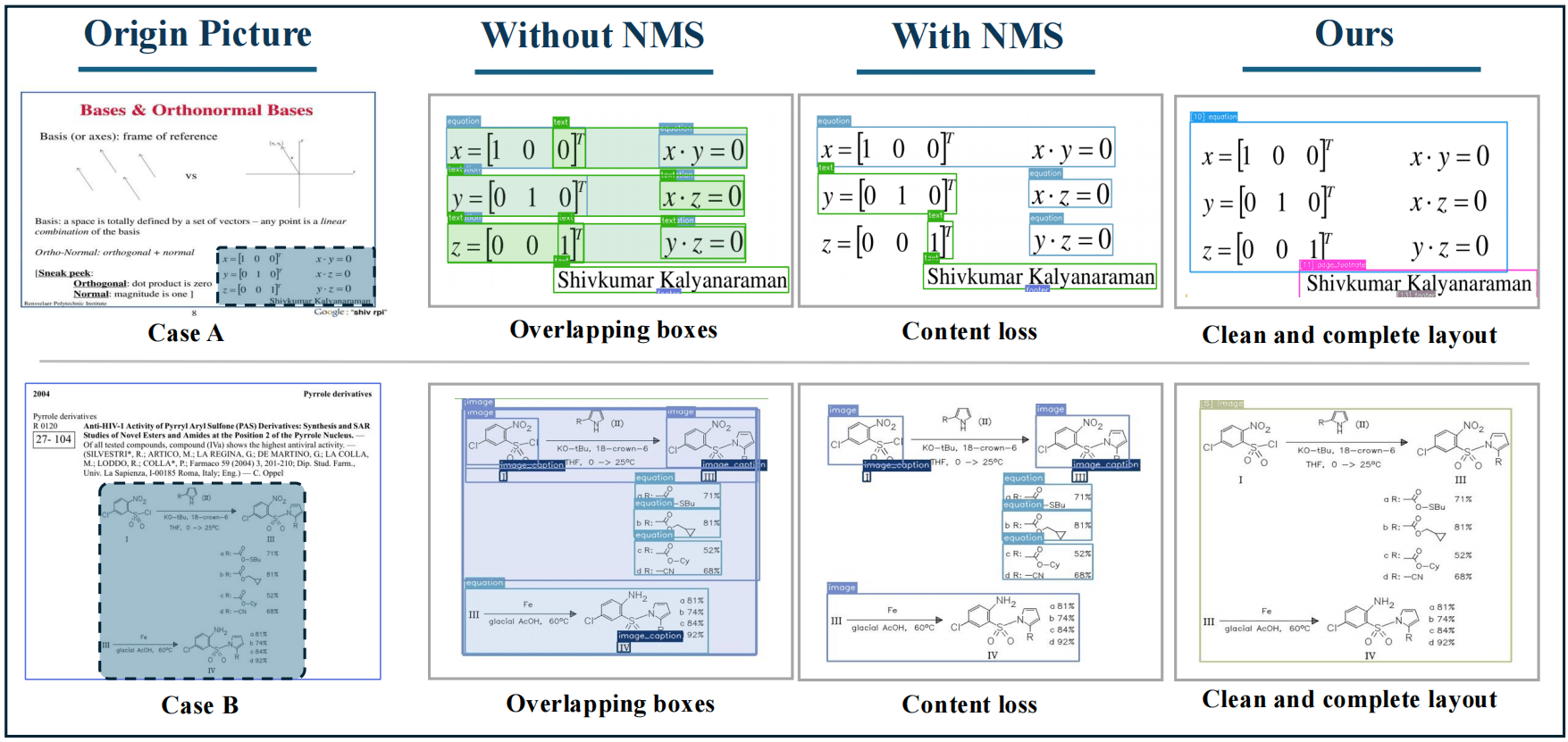
从实际应用来看,这种问题尤为明显:
在农业报纸版面中,多栏排布的文章可能会出现跨栏跳跃的情况。原本应该连续阅读的内容会突然跳转到其他栏目,导致整体阅读逻辑的混乱。

对于包含数独、拼字游戏等高密度页面来说,复杂的布局和交错的功能区域也给模型带来了额外挑战。
在这些娱乐版面中,文字与游戏格子相互重叠,系统难以明确哪句话对应哪个游戏,导致内容归属错误且跳跃阅读逻辑混乱的情况频繁出现。
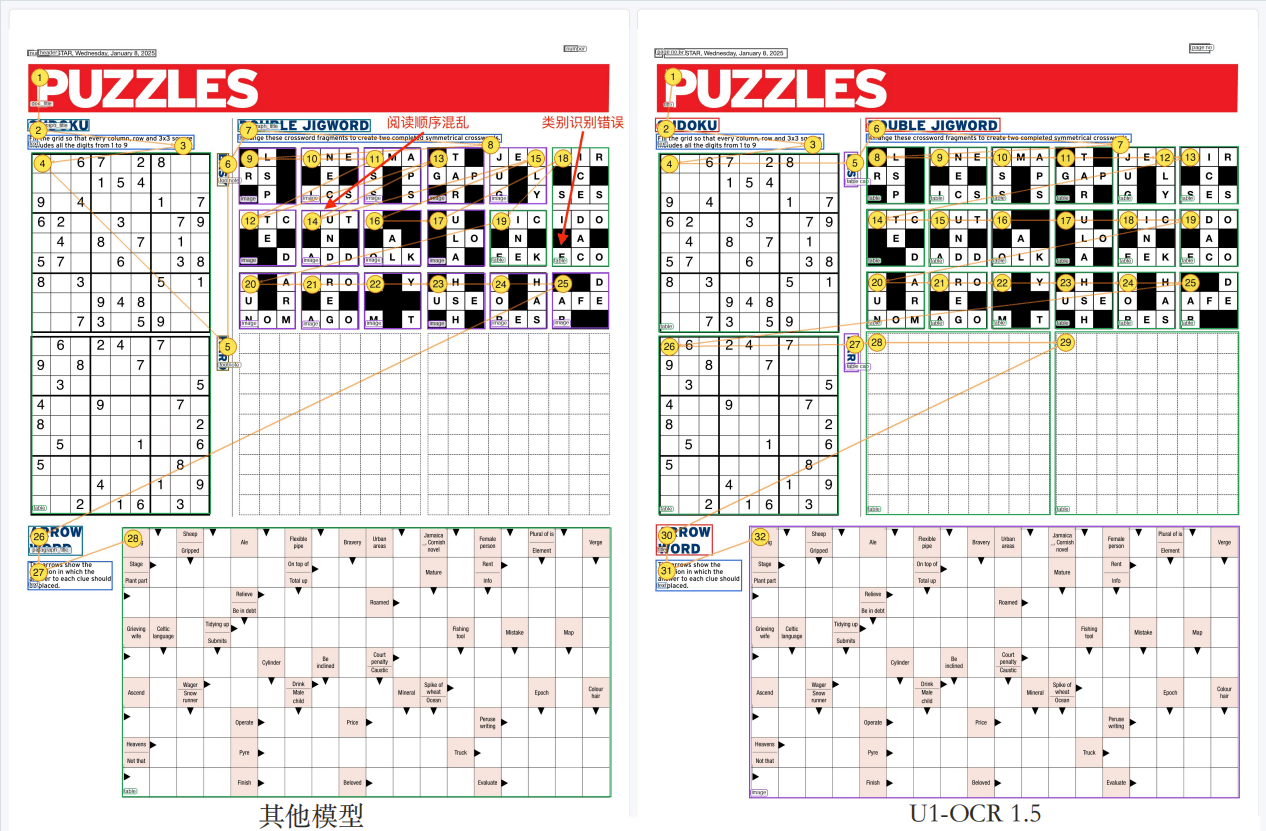
三、解决方案:U1-OCR的核心技术
针对上述问题,云知声的U1-OCR采用了多项创新技术以解决这些问题。首先,通过引入保留导向监督目标减少机械过滤造成的结构破坏;其次,采用难度感知顺序约束来优化复杂版面中的阅读路径恢复。
实验验证:领先的成绩证明了产品的优越性
在两大权威数据集OmniDocBench和D4LA上进行的实验表明,U1-OCR在结构理解能力和跨数据集泛化能力方面表现突出。特别是在复杂的版面布局中,它能更高效地处理边界判定、类别区分及整体结构恢复问题。
结果显示,在OmniDocBench和D4LA两个数据集中,U1-OCR均取得了最高的F1分数,并且在阅读顺序恢复指标上的表现也优于其他产品。这证明了我们的统一精修方案相比于传统做法更为有效。
从“文字识别”到“文档理解”,推动行业数字化转型
通过将文档解析任务分解为结构理解和顺序梳理两大核心部分,U1-OCR在多个权威数据集上取得了领先的成绩,并提供了更稳定可靠的检测器与解析器交接方案。这不仅提升了文档处理的效率和准确性,也为各行各业的数字化升级提供了强有力的支持。同时,开放标准API接口及一键调用功能降低了技术门槛,让更多行业能够享受到这项先进技术带来的便利。
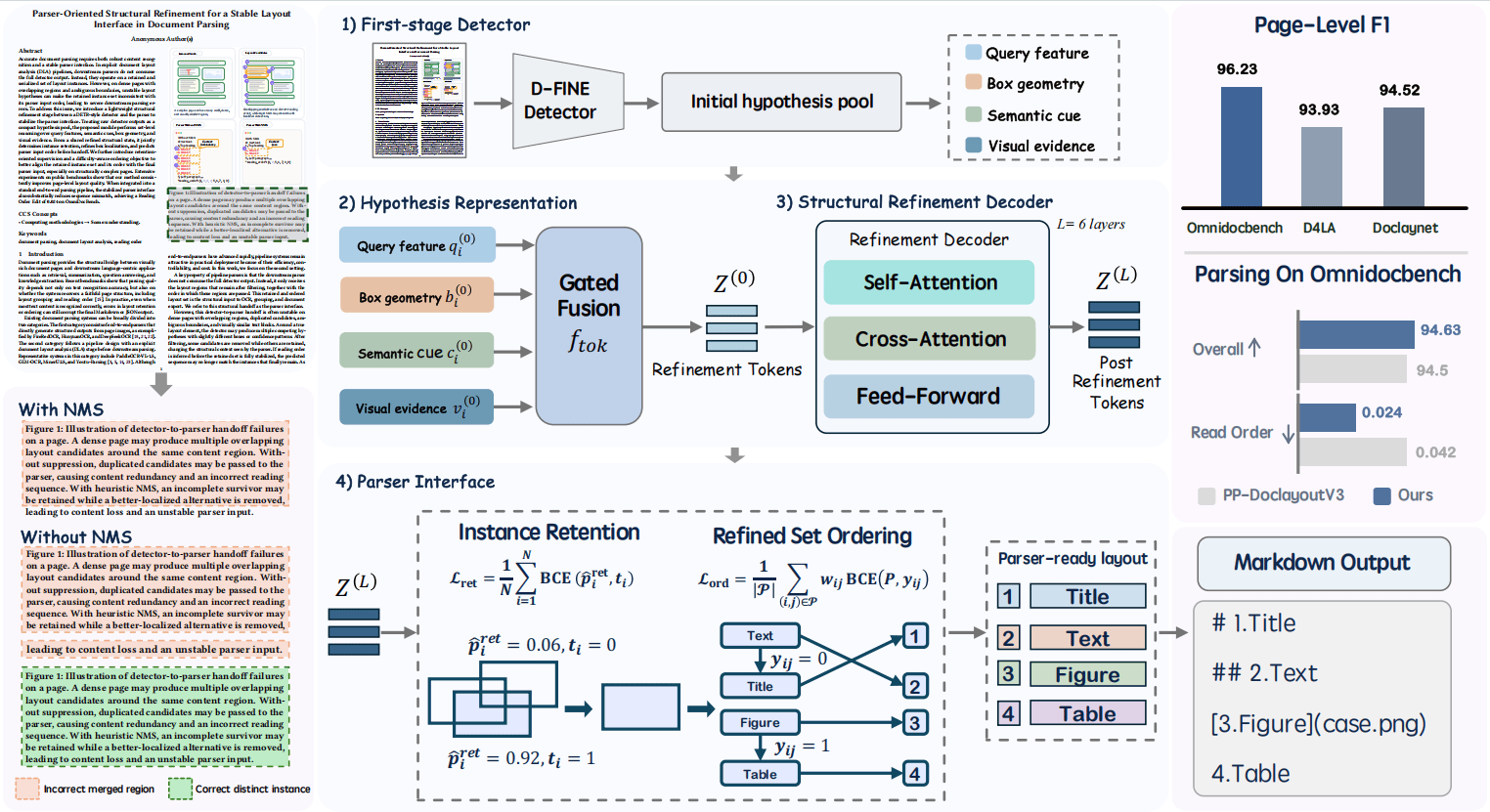
U1-OCR 文档解析的核心逻辑是:输入文档页面图像后,模型先通过第一阶段检测器生成初始候选假设池,再在解析器交接前进行统一结构精修——区别于传统方法依赖NMS决定候选区域去留,我们将检测器输出视为待精修集合,从中构造更稳定的解析器可用版面。其核心技术优势体现在四大关键设计上:
4.1 面向解析器接口的结构精修
U1-OCR 的核心不在于单独优化检测或排序的某个局部步骤,而在于重新建模检测器到解析器的交接过程。通过在解析器接口前引入轻量级精修阶段,让定位修正、实例保留与阅读顺序恢复在统一表示空间中完成,大幅提升最终结构接口的稳定性。
4.2 双向空间位置引导注意力
结构精修阶段采用双向空间位置引导注意力机制,联合建模候选区域之间的关系与图像证据。这一设计让当前候选区域的更新,不仅依赖自身局部视觉信息,还能结合其他候选区域的空间分布与全局版面布局,有效处理多栏排版、相邻文本块竞争、图文混排中的结构歧义,为后续实例保留与顺序恢复提供稳定基础。

4.3 保留导向监督
引入保留导向监督目标,让模型通过学习建模候选区域之间的结构竞争关系,而非依赖固定的IoU抑制规则决定区域去留,减少复杂页面中因机械过滤导致的内容缺失与结构破坏。

4.4 难度感知顺序约束
在阅读顺序恢复上,对保留实例的顺序关系进行建模,并引入难度感知加权,强化复杂区域之间的排序学习,让模型能在共享的精修结构状态上,恢复更一致的全局阅读路径,尤其适配跨栏、嵌套、图文混排等复杂版面。

五、实验验证:双数据集登顶,性能全面领先
为验证我们产品技术方案的有效性,我们从两个维度开展评测:一是采用pageIoU协议,独立评估最终保留版面集合的页面级结构质量;二是固定PaddleOCR-VL-1.5后端,仅替换前端版面分析模块,观察更稳定的检测器-解析器交接是否能提升端到端解析效果——核心关注阅读顺序相关指标的改善情况。本次评测覆盖两大权威数据集:OmniDocBench与D4LA。
5.1 主结果对比:结构理解能力跨数据集领先
实验结果显示,U1-OCR 在两大数据集上均取得最高F1分数,展现出强劲的版面结构理解能力与跨数据集泛化能力:
在OmniDocBench数据集上,我们的产品F1分数达96.23,优于PP-DocLayoutV3(96.03)、MinerU2.5(95.90)、dots.ocr v1.5(95.59)及PP-StructureV3(94.60);在D4LA数据集上,我们以93.93的F1分数登顶,领先dots.ocr v1.5(92.80)、MinerU2.5(90.20)、PP-DocLayoutV3(89.71)和PP-StructureV3(86.00)。
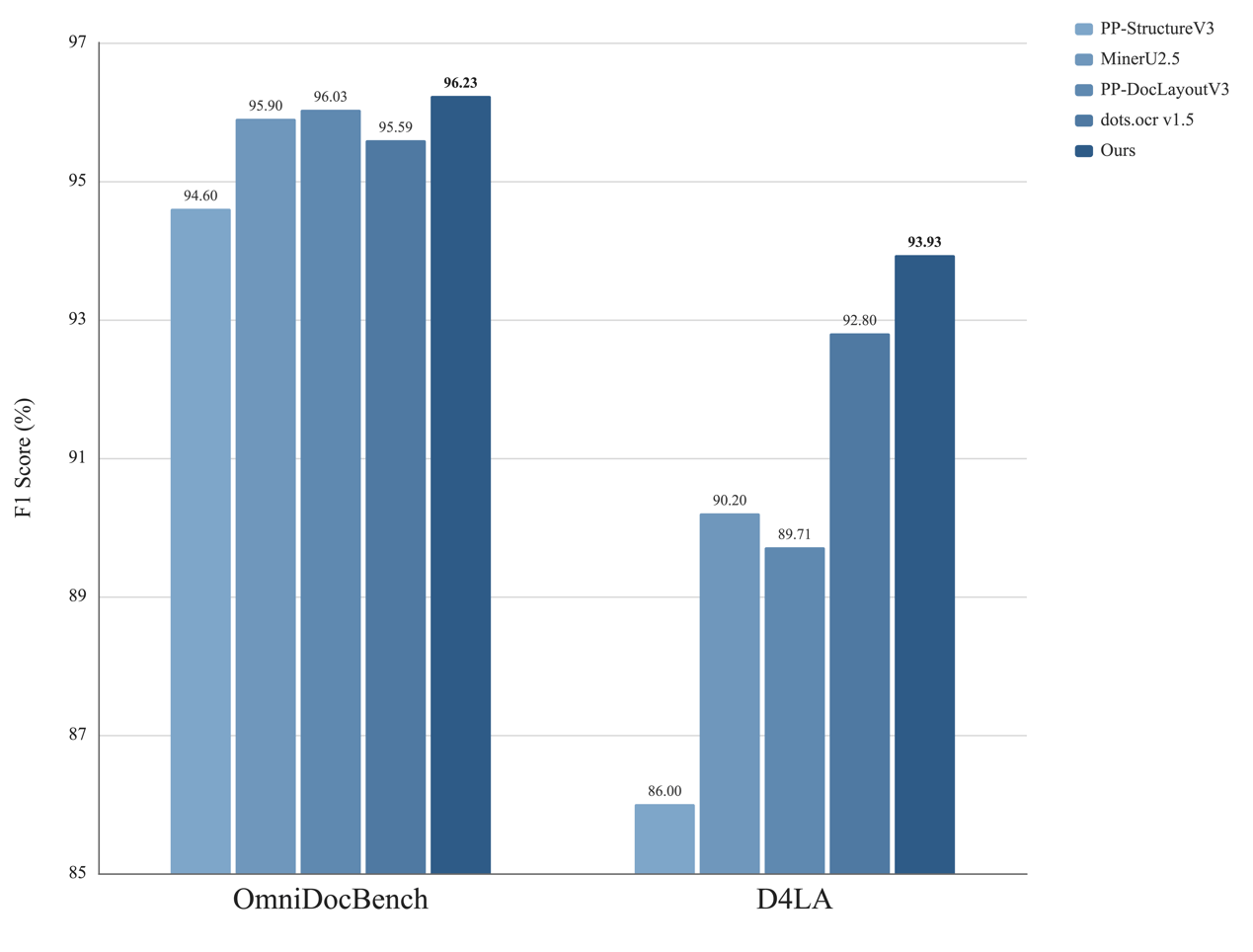
这一结果表明,在结构更复杂、布局变化更丰富的页面中,U1-OCR 能更高效地处理区域边界判定、类别区分与整体结构恢复问题,精准实现“将竞争候选假设稳定为解析器可用结构输入”的设计目标。(注:PP-DocLayoutV3为PaddleOCR-VL-1.5与GLM-OCR所使用的版面分析模块。)
5.2 OCR解析结果对比:阅读顺序恢复精度最优
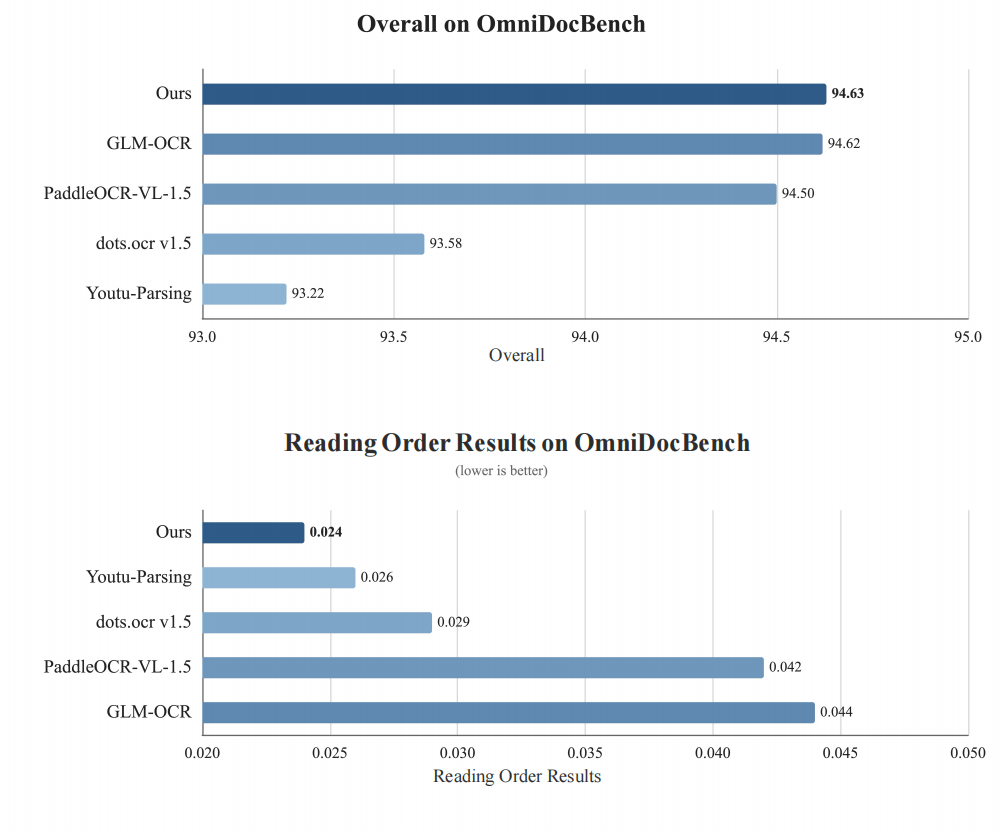
在OmniDocBench数据集上,U1-OCR 同时展现出出色的综合解析能力与阅读顺序恢复能力:
从综合指标Overall来看,我们的产品以94.63的分数略高于GLM-OCR(94.62),优于PaddleOCR-VL-1.5(94.50)、dots.ocr v1.5(93.58)及Youtu-Parsing(93.22),彰显端到端文档解析的稳定竞争力;从阅读顺序核心指标Read Order Edit来看,我们取得0.024的最优结果(该指标越低越好),远优于Youtu-Parsing(0.026)、dots.ocr v1.5(0.029)、PaddleOCR-VL-1.5(0.042)和GLM-OCR(0.044)。
实验进一步证明,启发式NMS仅能缓解重复框问题,无法兼顾定位、保留与排序的一致性;而我们产品采用的统一精修方案,能在多个数据集上实现三者的结构平衡,在阅读顺序恢复上显著优于“检测后再接独立排序模型”的传统做法,也印证了产品技术的有效性。
从“OCR识别”到“文档理解”,赋能行业数字化升级
U1-OCR 的目标远不只是“把文字识别出来”,更要切实解决复杂文档页面中的结构理解与阅读顺序恢复难题。我们将文档解析拆解为“识别结构”和“梳理顺序”两大核心任务,围绕这两个任务设计专属关键技术,不仅在多个公开权威数据集上取得了领先成绩,更为真实业务场景中最容易被忽略的检测器与解析器交接环节(detector-to-parser handoff),提供了更稳定、更可靠的处理方式。相关论文结论也印证了这一点:优化解析器接口,是提升显式DLA流水线文档解析能力的切实有效路径。
这也意味着,文档解析正从单纯的OCR文字识别,升级为更贴合真实业务需求的文档理解能力。此次U1-OCR 全量上线云知声Token Hub大模型服务平台,同步开放标准化API和一键调用功能,将进一步降低文档智能技术的使用门槛,为医疗、交通、金融、教育等多个行业,提供高效、精准的文档解析服务,助力各行业顺利实现数字化转型升级。