
姚顺雨今日完成DeepSeek V4挑战
智东西编辑团队发布了一篇关于腾讯新一代混合专家架构的大规模语言模型Hy3 preview的文章。该文章详细介绍了姚顺雨领导的混元团队首次对外展示的新一代大模型。Hy3 preview是迄今最智能的模型,采用了快慢思考融合的设计理念,并具备支持最长256K上下文的能力。它拥有总计295B的参数量和激活参数数量为21B。从测评结果来看,Hy3 preview在复杂推理、指令遵循、代码生成与智能体能力等
科技8 阅读
共找到 201 篇相关文章
智东西编辑团队发布了一篇关于腾讯新一代混合专家架构的大规模语言模型Hy3 preview的文章。该文章详细介绍了姚顺雨领导的混元团队首次对外展示的新一代大模型。Hy3 preview是迄今最智能的模型,采用了快慢思考融合的设计理念,并具备支持最长256K上下文的能力。它拥有总计295B的参数量和激活参数数量为21B。从测评结果来看,Hy3 preview在复杂推理、指令遵循、代码生成与智能体能力等

机器之心编辑部深度搜索公司(DeepSeek)最近在GitHub上进行了频繁的更新活动,推出了一个新的开源代码库Tile Kernels,并对现有的DeepEP代码库进行了升级至版本V2。距离上次他们悄然更新Mega MoE和FP4 Indexer还不到一周时间。Tile Kernels用户可以在以下链接找到该项目:https://github.com/deepseek-ai/TileKernel

今日,腾讯发布了新一代的大规模语言模型混元Hy3 preview,并将其源代码公开,这是该团队自重组以来推出的首个重要产品版本。Hy3 preview是目前混元系列中最先进的一个版本,采用了混合专家架构来实现快速和深入的思考过程。其参数总量达到2950亿个,激活参数为210亿,并能支持长达256K的内容上下文处理。从测试结果来看,Hy3 preview在复杂推理、指令执行以及代码生成等方面的性能得

智东西作者 陈骏达编辑 心缘据报道,近日多位开发者在社交媒体平台和官方交流群中反映,DeepSeek官方API所使用的模型能力已经发生变化,上下文窗口的容量增至一百万字,超过了之前的128k限制;同时,知识库更新至2025年5月,较之前有所提前。▲DeepSeek API调用出的模型为了验证这些反馈的真实性,我们立即进行了测试。结果显示,在DeepSeek API中的模型自我介绍时,与网页

近日,智东西报道了一则关于腾讯和阿里巴巴可能投资DeepSeek的新闻。根据《The Information》的报道,四位知情人士透露,这两家中国科技巨头正与DeepSeek进行初步洽谈,后者最近宣布启动首次外部融资计划。据悉,在接触了潜在投资者后,DeepSeek希望以超过200亿美元(约合人民币1364.9亿元)的价值筹集资金。就在上周四,有消息指出该公司预计估值将突破100亿美元(约合人民币

据悉,腾讯和阿里巴巴正在与人工智能初创企业DeepSeek探讨投资合作事宜。最近有消息指出,四名知情人士透露,中国互联网巨头腾讯控股有限公司及阿里集团正就向新兴的人工智能公司DeepSeek提供资金支持进行讨论。据其中一名内部人士称,DeepSeek目前正寻求以高于200亿美元的估值筹集资金。

4月22日,《科创板日报》报道指出,特斯拉车载系统即将整合字节跳动“豆包大模型”和深度求索“DeepSeekChat”的语音服务功能。这两款先进的AI解决方案将通过火山引擎提供技术支持,标志着自2013年特斯拉进入中国以来最大的一次车载语音助手升级。特斯拉车机系统根据微信公众号“网信上海”发布的消息,上海市于4月21日新增备案了一项生成式人工智能服务——“特斯拉车机语音大模型服务”。该服务由特斯拉

据悉,在这个月剩下的时间里,人们最期待的新产品是DeepSeek V4,各种迹象显示它的发布正越来越近。最近官方动作频繁,据称API端也开始对模型进行升级,性能表现良好。自从在2月初宣布推出测试版以来,这款软件实际上一直在悄然改进。尽管每次更新官方都没有详细介绍具体细节。最近,DeepSeek V4的页面进行了翻新,增加了快速、专家和视觉三种模式选择。此前的优化主要集中在网页版本上,而最新的信息显

一位年轻的开发者最近成功开源了名为Mythos的架构,这位22岁的小伙借鉴了DeepSeek的技术。 梦晨 2026-04-20 15:59:51 量子位

近期中国人工智能领域最引人注目的新闻是关于DeepSeek可能以约100亿美元的估值释放少量股权的消息,这一举动对一个长期坚持内部资金支持、由创始人梁文锋持有绝大多数股份并控制公司决策的企业来说意义重大。不过,值得注意的是,在消息传播两天后,各方面的反馈高度一致。知情人士透露该信息“极有可能为真”,但同时指出目前外部投资者很难参与其中;多位风险投资人士也表示,对于像DeepSeek这样热门的项目,

五家领先的国产大模型企业在2026年选择了哪些最佳的发展路径?自今年年初以来,这些企业动作频繁且变化多端,连行业内部人士都感到难以捉摸。据悉,一向不愿讨论上市和融资问题的DeepSeek已开始接触外部资本;智谱新Coding模型口碑迅速上升;MiniMax和智谱在上市后市值分别飙升至4000亿及3000亿港元;阿里巴巴也进行了一系列重大组织重组。这些现象背后的原因是什么?一位资深业内人士向数智前线

深度学习模型DeepSeek R1 的问世,引发了人们对大规模预训练是否是提升模型推理能力唯一途径的新思考。事实上,通过后处理技术如强化学习、过程奖励和闭环反馈机制,人们得以以极低的成本解锁原本需大量算力才能触及的高级功能。这一现象正逐渐在自动驾驶领域重现。自动驾驶系统已经完成了一系列大规模的数据预训练,但仍存在一个重大障碍:它们尚无法完全理解为何特定的行为模式是最佳选择。真正的进步需要依赖闭环反

近日,AI 行业传出一则重大新闻。多家媒体披露,国内一家领先的人工智能初创企业 DeepSeek 正在与潜在投资者进行谈判,计划以超过 100 亿美元的估值筹集至少三亿美元的资金。据悉,DeepSeek 确实正在接触一些机构,但有关本次融资的具体金额和公司估值的消息尚需进一步确认。去年,凭借高性能且成本低廉的推理模型 DeepSeek R1,该公司在 AI 领域引起了广泛关注,并导致股市波动。此外

据报道,DeepSeek计划首次引入外部资金。《The Information》披露的消息指出,公司正在与潜在投资者接触,并探讨融资的可能性,目标估值超过100亿美元(约合人民币681亿元),计划筹资至少3亿美元(约20亿人民币)。然而,他们真的需要这笔资金吗?DeepSeek的母公司幻方量化在2025年的收益率约为56.6%。若按“1%管理费+20%业绩报酬”计算,仅2025年一年,业内普遍估计

据知情人士透露,中国初创企业深度求索(DeepSeek)正在与潜在投资者商讨,计划筹集至少3亿美元的资金(约合3.81亿新加坡元),公司估值目标为100亿美元。美国科技新闻网站The Information报道,此前该公司曾拒绝了来自中国顶尖风险投资机构和大型科技企业的多份融资提议。作为一家中国的创业公司,DeepSeek在美国的风险投资圈中可能面临一定的不确定性。目前该公司尚未对路透社的评论请

近日,据国外媒体报道,DeepSeek正在首次尝试吸引外部投资,并计划估值超过100亿美元(约681.8亿元人民币)。据知情人士透露,该公司已经开始与潜在投资者接触,目标是筹集至少3亿美元(约合20.5亿元人民币),以应对日益增长的研发成本和激烈的市场竞争。成功完成这一轮融资后,DeepSeek将首次引入外部资本支持,这标志着公司长期以来依靠母公司幻方量化提供资金的模式发生了转变。过去几年中,该公

我们讨论了英伟达在AI领域的领先地位,尤其是在架构优化方面的努力。黄仁勋强调了持续创新的重要性,并指出摩尔定律的终结意味着更多地依赖于计算机科学的进步而非仅仅依靠半导体物理学。黄仁勋解释说,CUDA的成功在于其灵活性和广泛的生态系统支持。他提到未来的模型可能需要针对不同架构进行深度优化,而英伟达的目标是保持领先地位并推动技术栈每层的发展。我们探讨了英伟达是否会利用较老的节点来满足市场需求的增长。黄
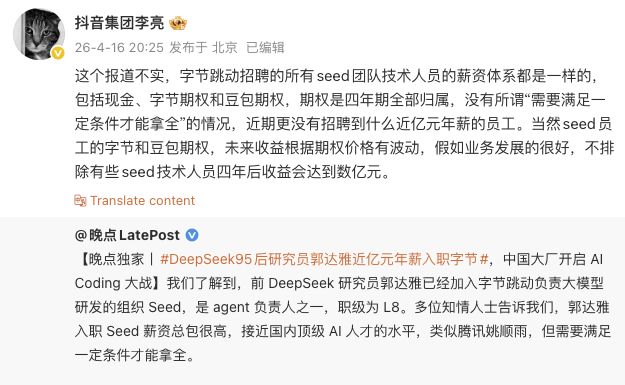
4月16日,有关DeepSeek年轻研究员郭达雅以高额年薪加入字节跳动的报道引发关注。抖音集团的一位高级管理人员李亮在社交媒体上发文澄清,称该消息并不准确。他指出,在字节跳动招募的所有seed团队成员中,薪酬结构是一致的,包括现金、股票期权以及豆包期权,并且所有员工的四年期期权都会完全归属,没有所谓的“需要达到特定条件才能全部领取”的情况存在。近期也没有招聘到年薪近亿元的员工。同时,他提到seed

据报道,本月下旬将发布DeepSeek V4,这款产品的推出时间比预期的要晚一些,主要原因在于它将全面兼容国内的人工智能平台,尤其是华为昇腾平台。在人工智能领域,无论是国外还是国内,首次发布的平台通常都是基于美国的技术,特别是NVIDIA的AI平台。然而,这次DeepSeek V4有可能改变这一现状。近日,在与科技播客Dwarkesh Patel的一次访谈中,NVIDIA首席执行官黄仁勋就此事发出

新智元报道斯坦福大学发布了最新的《AI指数报告》,该报告指出,人工智能领域正在经历前所未有的发展速度。报告揭示了人工智能领域的最新趋势,强调了技术进步的速度和影响范围。AI 指数报告显示,全球范围内的人工智能研究与应用正以惊人的速度增长。该报告总结了过去一年中人工智能领域的重要进展,并展望未来的发展方向。报告指出,目前人工智能的使用已经渗透到各个行业和国家。研究发现,在生成式AI技术的应用上,中国