
机器之心编辑部
深度搜索公司(DeepSeek)最近在GitHub上进行了频繁的更新活动,推出了一个新的开源代码库Tile Kernels,并对现有的DeepEP代码库进行了升级至版本V2。距离上次他们悄然更新Mega MoE和FP4 Indexer还不到一周时间。
Tile Kernels
用户可以在以下链接找到该项目:https://github.com/deepseek-ai/TileKernels
据悉,这个代码库提供了专门为大型语言模型操作优化的GPU内核,这些内核是使用专为Python编写的高性能GPU内核表达而设计的领域特定语言TileLang构建而成。该语言具有迁移便捷、快速开发和自动优化等优势。
Tile Kernels在计算强度和内存带宽方面表现出色,达到硬件性能极限。项目团队表示:“这些内核已经在内部训练和推理场景中得到了应用,但它们并不代表最佳实践,我们正在不断改进代码的质量与文档。”
尽管介绍信息不多,但从文字间可以窥见DeepSeek下一代模型底层架构创新的方向。
接下来是Tile Kernels的一些具体特性:
- 门控机制:包括用于MoE路由的Top-k专家选择和评分功能;
- MoE 路由:Token到专家的映射,融合扩展与归约以及权重标准化
- 量化(Quantization):支持基于token、块或通道级别的FP8/FP4/E5M6转换,并集成SwiGLU和量化的操作;
- 转置:批量转置操作
- Engram:RMSNorm、正向/反向传播及权重梯度归约的融合内核;
- Manifold HyperConnection(超连接):包含Sinkhorn标准化以及拆分与应用混合的操作
- Modeling:通过高层torch.autograd.Function封装,将底层内核组合为可训练层(engram gate、mHC pipeline)
EPv2:更快的EP,并支持Engram/PP/CP;
最新版本EPv2的地址是https://github.com/deepseek-ai/DeepEP/pull/605
今天早些时候,DeepSeek发布了最新的EPv2版本,实现了更快速的专家并行,并且支持Engram、流水线并行和上下文并行。
随着硬件技术的进步以及网络架构的发展,先前的DeepEP V1版积累了一些历史负担和技术难题。
此次更新彻底重构了专家并行系统,在资源需求方面相比V1版本减少了数倍,并且支持更大规模的扩展能力(包括单机和跨机器);
同时,此次更新还引入了一系列实验性的无SM方案,涵盖了Engram、流水线并行以及上下文并行的所有集合操作。此外,后端已从NVSHMEM切换为更为轻巧的NCCL Gin后端。
这是DeepEP V2版本的新特性:
- 全时即时编译(Fully JIT)
- NCCL Gin 后端:仅包含头文件,极其精简;
- 支持使用现有的NCCL通信器;
- 将高吞吐和低延迟API合并为单一接口,并采用新的GEMM布局。
- EPv2:
- 允许更大规模的扩展(最高支持EP2048)。
- 引入分析化SM和QP计数计算,无需进行自动调优;
- 持续兼容混合模式与直接模式操作;
- 为类V3旧版训练任务,减少了SM占用数量(从24降至4-6),同时保持或提升性能。
- 实现了0 SM Engram配合RDMA
- 实现了0 SM PP配合RDMA
- 实现了0 SM CP配合Copy Engine
- 根据DeepSeek-V3的配置,新版本在每批次8K token、7168隐藏层维度、Top-8专家、FP8分布和BF16结合的情况下进行了测试,并取得了显著成果。
性能表现
结果表明:这里的带宽数据指的是逻辑带宽。例如,在EP 8 x 2 的情况下,90 GB/s的带宽实际上包括了本地显卡间的流量;
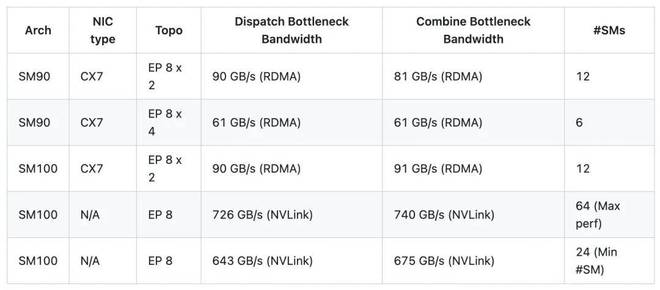
相较于V1版本,V2实现了约1.3倍的峰值性能,并且节省多达4倍的SM资源占用。
最后,希望DeepSeek能够尽快发布下一个大版本,大家都非常期待。
最后,劝一下 DeepSeek,赶快发 V4 吧,都等急了。