一位年轻的开发者最近成功开源了名为Mythos的架构,这位22岁的小伙借鉴了DeepSeek的技术。
 梦晨
梦晨这位开发者整合了现有的研究和关于Claude Mythos架构的主要猜测。
据了解,有人认为Mythos过于危险而被封存,但这个说法很快就被打破了。
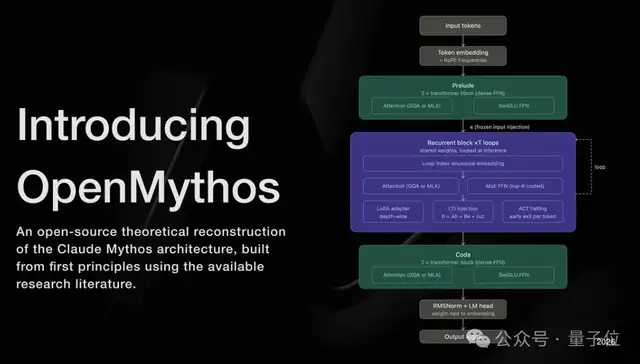
OpenMythos创建了一个循环深度Transformer模型(RDT),通过跨专家的权重共享和条件计算实现迭代深度。
有研究显示,这种设计仅使用一半参数就能达到传统模型的效果。
这一突破性的成果是由Kye Gomez完成的,他也是Swarms智能体框架的创始人。
RDT架构的主要特点包括:
不堆参数,堆循环
同一组权重可以重复运行多达16次

推理过程完全在潜在空间中进行。
- 这些设计使得RDT模型能够以更少的参数量实现更深入的推理效果。
- 每次走不同的专家路径
- 在过去的两年里,AI行业倾向于使用大量不同层级的Transformer来学习不同的信息,导致了巨大的参数规模。
RDT则采用了几层,并通过反复循环运行多达16次的方式进行深度计算。
反复运行同一过程不会浪费资源吗?
RDT的回答是每次循环会激活不同“专家”来避免冗余工作。
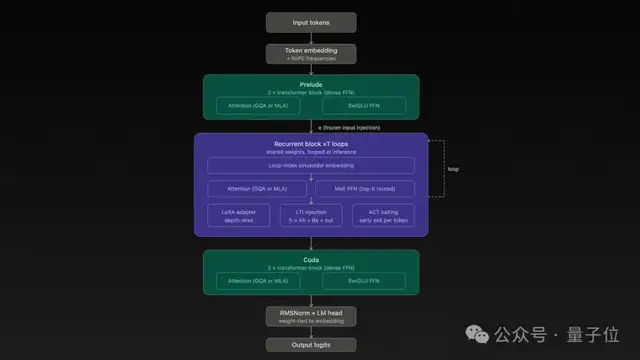
混合专家网络在每一次循环中都会激活不同的子集,以提高效率。
这种设计借鉴了DeepSeekMoE的架构理念:使用大量细粒度路由专家和少量始终在线的共享专家。
Gomez总结道,MoE提供了知识广度而RDT则提升了推理深度。
要保持这一过程稳定,还需要引入LTI稳定循环注入技术来防止每轮计算发散。
新的研究表明,在参数量只有770M的情况下,RDT能够与拥有1.3B参数的标准Transformer模型匹敌。
这意味着使用更少的资源可以获得相同的效果。
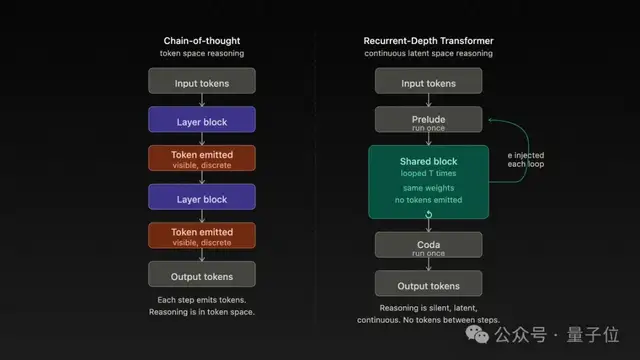
与传统的Chain-of-Thought方法相比,RDT采取了一种完全内化的处理方式。
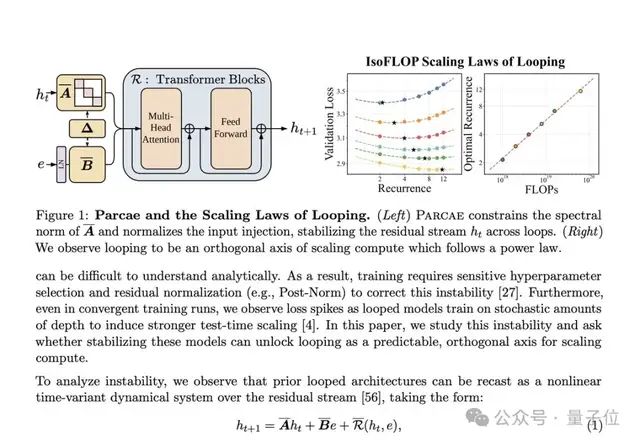
Kye引用了俄亥俄州立大学的研究论文,展示了循环Transformer架构的两个关键实验。
即使在面对未曾见过的知识组合时,循环Transformer也能给出正确的答案,而标准模型则无法做到这一点。
这说明循环机制不是简单的重复计算,而是深层次思考的过程。
在训练过程中教授了20轮推理链后,在测试中直接进行30轮推理的实验也证明了这一观点。
循环Transformer通过增加几轮循环即可应对这种情况,而标准模型则无法完成任务。
这些结果表明当前的大规模预训练模型已经积累了大量的事实信息,但缺乏组合这些知识的能力来回答新颖的问题。
循环机制似乎为这种能力的解锁提供了可能。

第一个:系统性泛化。
如果这些结论是正确的,则未来AI发展的主流趋势可能会从“构建更大规模的模型”转向“优化现有模型的推理过程”。
这些研究成果已经引起了学术界的广泛关注,并吸引了更多理论和实验研究的关注。
第二个:深度外推。
GitHub项目地址:https://github.com/kyegomez/OpenMythos#the-central-hypothesis
循环Transformer的应对方式就是在推理时多加几轮循环,标准Transformer直接崩溃。
这些结果说明当前大模型在预训练中已经记住了大量事实,瓶颈在于知识组合。
它们无法将已知事实串联起来回答新颖问题。循环似乎免费解锁了这种组合能力。
如果这些结论成立,Scaling的主流将从”训练更大的模型”转向“让现有模型在推理时多想几遍”。
有了这些研究结果,Anthropic的Mythos是否真的用了这套架构,似乎已经不重要了。
对循环Transformer的猜想已经吸引了来自学术界的大量目光。
更多理论和实验验证正在路上。
GitHub:
https://github.com/kyegomez/OpenMythos#the-central-hypothesis
参考链接:
[1]
https://x.com/KyeGomezB/status/2045660378844024994
[2]
https://arxiv.org/abs/2604.07822
[3]
https://arxiv.org/abs/2604.12946