
新智元报道
2026年初,大多数企业仍在依赖数据分析师手动编写SQL查询来处理表格时,OpenAI内部发布了一种能够自主思考和自我进化的数据分析智能体,将原本耗时的查询过程缩短到了几分钟。
数据团队为何总是重复犯同样的错误?
答案通常不是因为算力不足,而是由于表的数量过多、定义混乱以及经验分散:
同一个术语“活跃用户”在不同的表格中可能有着截然不同的含义;即使选择了正确的表,编写上百行的SQL语句才能获取结果,并且任何连接条件的错误都会导致整个工作失败。
OpenAI内部采取了一项更为激进的措施:利用Codex驱动的数据智能体接管了“查找-理解-生成查询-验证结果”这一系列流程,通过构建六层上下文架构来补全数据语义、接入组织知识并沉淀经验记忆,使工程师能够用提问取代繁琐的手动操作。

数据查询不再需要手动查阅表格
“我有大量的相似结构的表要处理,花费了大量时间试图弄清楚它们的区别以及应当使用哪个。”一位OpenAI工程师的日常抱怨反映了数据工作者面临的普遍挑战。
OpenAI内部的数据平台拥有600PB的数据量,分布在大约7万个数据集中。想象一下:当OpenAI的员工需要分析ChatGPT用户的增长情况时,面对数十个声称记录“用户活跃度”的表单,每个表定义却各不相同。
选错表意味着数天的努力可能白费,更糟糕的是可能会基于错误的数据做出关键决策。
即使选择了正确的表格,生成准确的结果也是一项艰巨的任务。
下图中展示的一个包含超过180行的SQL语句,如同一座难以克服的大山——复杂的表连接、聚合操作,任何一个微小的错误都可能导致整个分析失败。

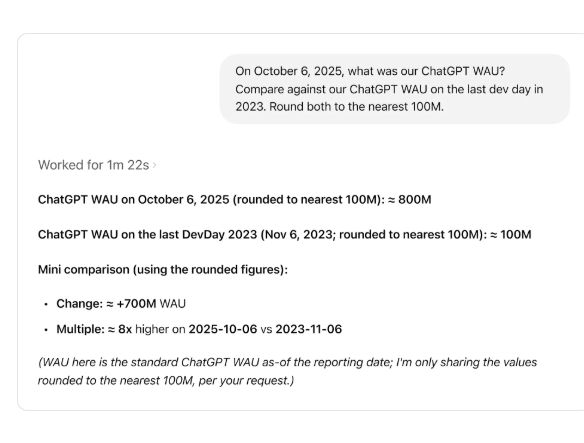
现在有了由Codex驱动且具备自主学习能力的智能体,工程师不再需要编写上百行的SQL查询,只需提问就能从数据海洋中找到所需的信息。例如下图中的查询需求是对比两个时间点的活跃用户数。
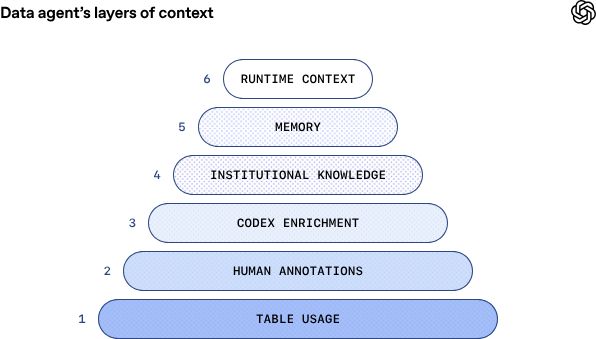
六层架构的数据大脑
虽然将自然语言转化为SQL语句的工具种类繁多,但OpenAI内部使用的数据分析智能体的核心创新在于其多层次上下文架构。
最底层是基础元数据,包括表结构、列类型等基本信息,为智能体提供了数据图谱的基础框架。
其次是一层人工标注,由领域专家精心编写的关于表和列的描述。这一层级捕捉意图、语义及业务含义,并包含从模式或历史查询中难以推断的信息。这相当于对每个表进行了基础培训。
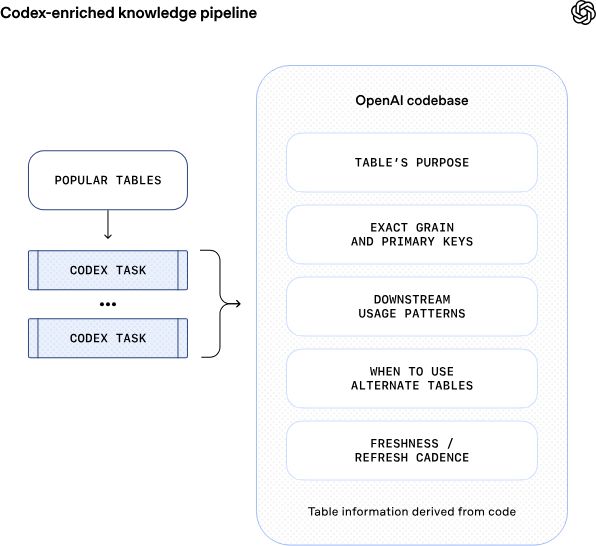
接下来是Codex增强层,它通过推导出表的代码级定义来使智能体更深入地理解数据内容。这一层级提供了关于值唯一性、更新频率及范围等关键信息,并帮助智能体理解不同表格在构建和更新上的差异。
再往上一层则是机构知识层,让智能体能够访问Slack、Google Docs和Notion等平台获取公司背景信息,如产品发布记录、可靠性事件以及内部代号和工具的定义。
拥有了这些外源性文本提供的背景信息后,智能体会避免犯常识性的错误。
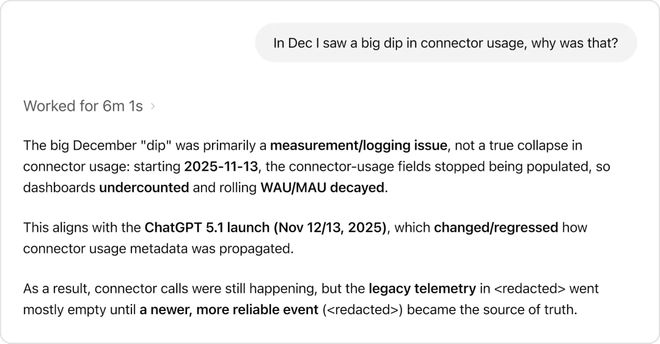
例如当用户询问“十二月连接器使用量为何下降”时,智能体不会仅报告数字变化而是通过机构知识发现这是一个测量或日志记录问题,并与ChatGPT 5.1发布导致的数据收集变动有关。
最关键的学习进化层让智能体具备持久记忆功能。当它从用户那里获得纠正信息或者发现了数据问题的细微差别时,能够保存这些经验供日后使用。记忆可以由用户手动创建和编辑,并适用于全局或特定使用者。

运行时上下文层使智能体能够在没有现有背景信息的情况下直接查询数据仓库来获取实时的数据信息。它还可以与其他数据平台系统(如元数据服务、Airflow、Spark)通信,以获得更广泛的数据背景。
离线检索与在线查询间的动态切换
这个六层系统的协作机制是什么样的?
具体来说可以分为离线和在线两步处理方式。
每日凌晨,智能体会系统性地扫描昨天成千上万张数据表的实际使用情况,汲取专家留下的批注与洞察,并调用Codex来解析隐藏在代码中的逻辑。所有这些零散的“知识碎片”被整合为一个统一、标准化的知识图谱。
接着,通过OpenAI的嵌入模型转化并压缩成一组组向量嵌入存储于高速检索库中,从而打造了一个供智能体立即使用的数据记忆宫殿。
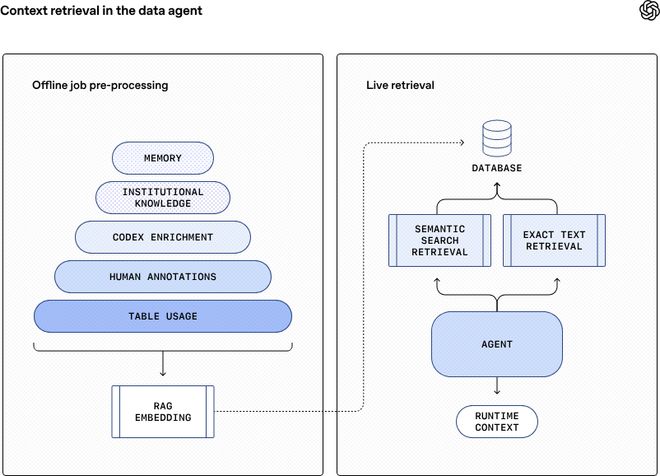
当用户的请求到来时,无需像人类分析师那样花费大量时间在元数据的大海中寻找答案。而是借助检索增强生成技术精准定位与当前问题最相关的数据表。这一过程快速、可扩展且延迟低。
对于需要最新数据的查询,则会即时启动实时查询通道直接向数据仓库发送请求,这样既保证了运行时上下文的时效性又能结合离线知识进行深度分析。因此一个复杂的业务问题便在“闪电检索”与“精确制导”的协同下被迅速转化为清晰洞察。
从静态工具到动态合作伙伴的角色转变
这个智能体令人惊叹之处不仅在于其技术复杂度,更在于它如何融入日常工作流程并成为真正的合作伙伴。不同于传统的问答式工具,OpenAI内部使用的数据分析智能体设计为能够进行推理的对话伙伴。
想象一下这样的场景:产品经理提问不明确或信息不全时,智能体会主动寻求澄清问题。如果没有得到回应,它会采用合理的默认值推进工作流程。例如,如果用户询问业务增长但未指定日期范围,它可能会假设最近七天或一个月的数据。
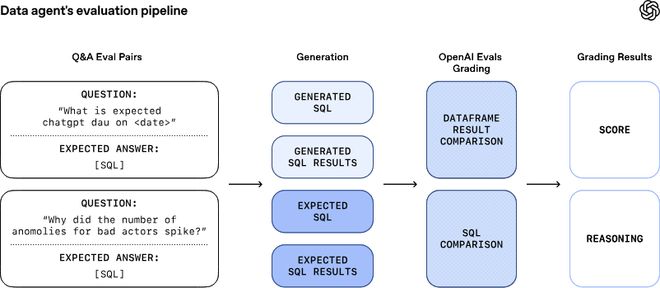
为了避免不断进化的智能体在学习过程中出现偏差,OpenAI团队为每个重要问题配置了手动编写的“黄金标准”查询语句作为基准,并通过Evals API持续监控和评估智能体的表现。
这些评估不仅检查SQL语法的准确性还比较结果数据的一致性。当智能体出现问题时系统会立即报警,确保在影响用户之前被发现并修复。
在数据安全方面,规定只有有权访问的数据表才能由用户查询;如果缺少权限则会被标记或转向授权使用的替代数据集。
为保证数据分析过程的透明性,智能体会在每个答案旁边总结假设和执行步骤来揭示其推理路径。当查询被执行时它会直接链接到原始结果,让用户检查底层信息并验证分析的每一个环节。
如何搭建一个数据分析智能体
OpenAI并未公开这种数据分析智能体的具体实现方式,但若想自行构建类似工具,OpenAI工程师也分享了一些经验教训。
最初阶段智能体能够访问完整的数据集,但这很快导致了功能重叠的表格让其迷失方向。为了减少歧义并提高可靠性,开发者不得不限制智能体可以访问的数据表范围。

另一个挑战来自于开发人员提供的高度规范化的系统提示词。虽然许多问题有类似的分析形态,但细节差异使得僵化指令反而适得其反。当关注点转向真实使用效果时,让智能体而非系统级提示来决定如何实现可以让它变得更加稳健并产生更好的结果。
最关键的是意识到相比专家标注的数据表含义,数据的真实意义更多地存在于代码中。查询历史能够更精确地描述表格的形态和用法,并捕捉从未在SQL或元数据中显现出来的假设与业务意图。通过使用Codex爬取代码库,智能体能理解数据集的实际构建方式并能够更好地推理每个表格实际包含的内容。
企业数据环境日益复杂的情况下,类似OpenAI的数据智能体工具可能成为未来企业数据分析的标准配置,推动整个行业向更高效、智能化的数据驱动决策模式转变。
这些智能体的目的是增强而非替代数据分析师的能力,把他们从繁琐的手动查询编写和调试工作中解放出来,专注于定义指标、验证假设及制定基于数据的决策。
这些智能体的目标不是替代数据分析师,而是增强其能力,将数据分析师从繁琐的查询编写和调试中解放出来,专注于更高级别的定义指标、验证假设和制定数据驱动决策。
参考资料:
https://openai.com/index/inside-our-in-house-data-agent/
https://x.com/OpenAIDevs/status/2016943147239329872