
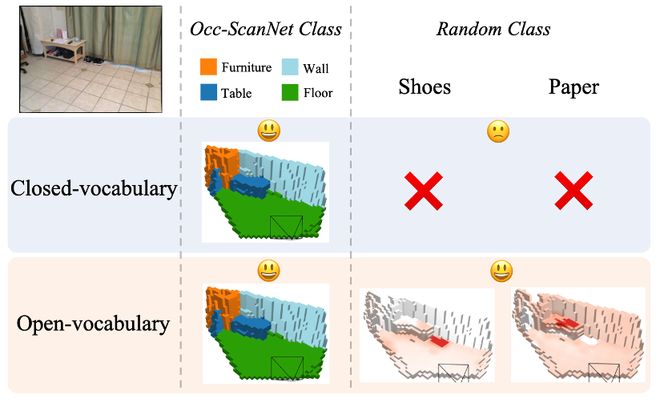
在具身智能的研究领域中,让机器人能够精确理解周围环境的几何结构与开放语义信息始终是一项关键挑战。近年来,研究人员通过三维体素网格整合稠密几何和语义数据来构建3D语义占据地图,为机器人的空间推理、导航及互动提供了重要依据。
然而,现有的方法大多基于封闭词汇设定,这限制了模型只能识别预先定义的有限类别。在真实环境中,用户可能会询问关于「鞋子」、「纸巾」或「遥控器」等未定义物体的位置信息。对于这些更细粒度、描述性更强的目标,传统的占据预测技术往往无法准确识别。
最近,香港科技大学(广州)的陈昶昊教授团队与香港中文大学(深圳)的研究者合作开发了LegoOcc系统,首次实现了单目开放词汇三维占据预测。这项工作已被CVPR 2026大会收录为口头报告。
LegoOcc采用语言嵌入高斯作为统一的三维表示方法,在仅使用几何标签进行训练的情况下,能够支持任意文本描述的目标类别的查询,并实现开放词汇的三维语义占据预测。
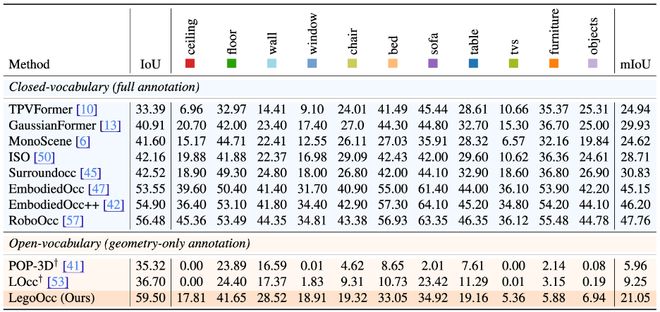
在Occ-ScanNet数据集上,LegoOcc在开放词汇预测中取得了21.05 mIoU和59.50 IoU的结果,与之前最强的开放词汇模型相比,mIoU提升了超过两倍;同时,在几何占据预测方面也超越了多种封闭词汇方法。

- 论文标题:单目开放词汇占用预测在室内场景中的应用
- 为什么具身场景中的开放语义占据预测更加复杂?
开放词汇模型能够根据任何自然语言描述进行推理,而传统的封闭词汇模型仅能识别训练阶段预先定义的有限类别。例如,开放词汇模型可以回答关于「鞋子」、「纸巾」或未定义物体的问题,并生成相应区域的热力图。
室内具身环境与户外驾驶场景有何不同?
- 室内环境中几何结构更复杂、密度更高且存在大量细小物体,需要更高的建模精度。此外,室内物体类别繁多且分布不均,很多类别仅在训练数据中出现几次。
- 因此,直接将室外的开放词汇占据预测模型应用于室内场景会导致性能下降,目前的一些方法仍然依赖于固定基类模型,无法处理开放词汇类别推理问题。
LegoOcc框架介绍
LegoOcc将任务分为两个部分:一是通过几何学习来确定空间中哪里「被占据」;二是通过语义学习来判断这些区域「是什么」。为了实现开放词表场景表达,LegoOcc采用了语言嵌入高斯作为统一的中间表示方法。
- 从单目图像生成带有文本描述信息的3D高斯
- 输入单目图像后,LegoOcc通过前馈网络预测一组三维高斯。每个高斯不仅包含几何参数(如位置、尺度和不透明度),还携带与语言空间对齐的语义嵌入。这样可以同时服务于几何建模和开放词汇语义建模。
基于泊松过程的高斯到占据转换
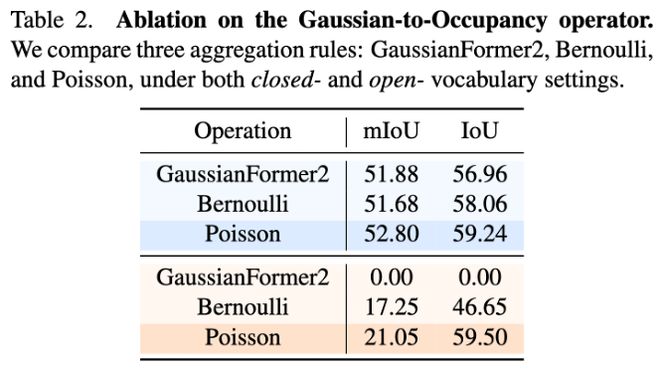
在仅使用二值占据监督的情况下,LegoOcc提出了基于泊松过程的方法将高斯表示稳定聚合为体素占据结果。这种方法避免了二维渲染与三维占据之间的优化冲突,提升了模型在弱监督条件下的稳定性。
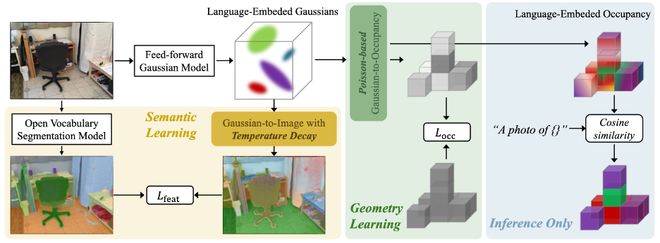
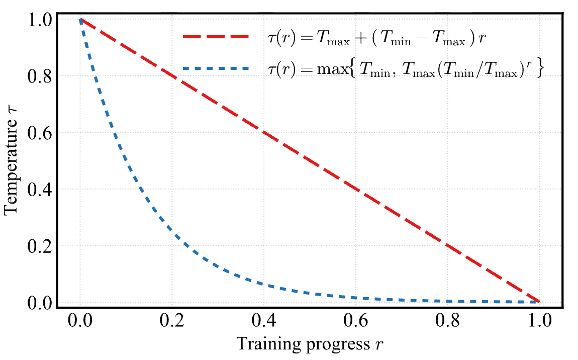
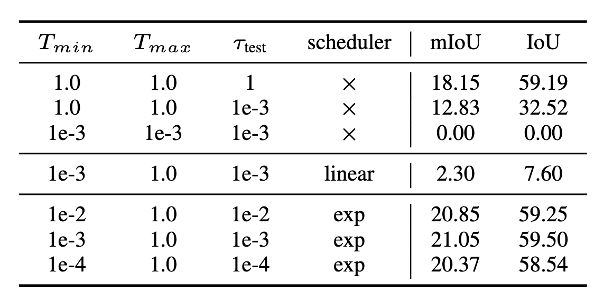
渐进温度衰减减少特征混合
在语义学习部分,LegoOcc采用渐进温度衰减策略来控制不透明度,减少了沿光线的特征混合问题。这使得语言描述更加精确地对应到单个高斯上,增强了模型在开放词汇语义理解中的判别能力。
论文通过定量实验、消融实验和可视化结果验证了LegoOcc的有效性,并展示了其在多个方面的优势。
在开放词汇设定下mIoU超越此前最佳方法两倍
研究显示,LegoOcc在闭集评测中预测的几何准确性和语义泛化能力更强。而在开放词汇测试中,它能够根据视觉语言模型自动抽取名词作为文本查询,并生成相应的三维语义占据结果。
在Occ-ScanNet数据集上,LegoOcc取得了显著的结果,mIoU超过此前最佳方法两倍以上;整体IoU也有明显提升。此外,它的性能甚至超过了所有封闭词汇模型的最佳IoU值。
泊松聚合的作用验证
通过消融实验验证了Poisson聚合在开放词汇设定下能够显著提高模型的性能。
渐进温度衰减缓解特征混合问题
消融实验证明,渐进温度衰减策略有助于减少沿光线的特征混合,从而提升语言监督对单个高斯的精度。
实验结果
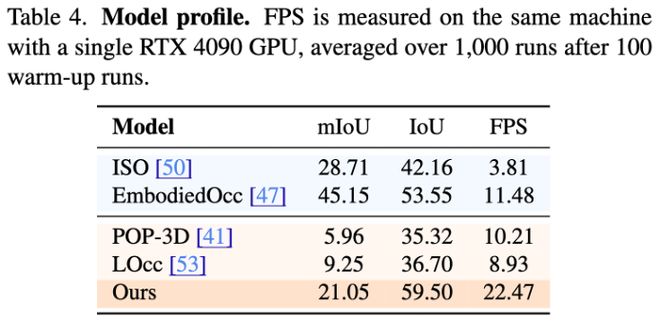
推理速度快且适合机器人平台部署
LegoOcc在单张RTX 4090上的推理速度达到了22.47 FPS,明显快于多种对比方法。这使得它更适合应用于具身机器人平台。
图片展示了LegoOcc的预测结果与真实标签的一致性,在固定类别评测中几何和语义预测能力更强。
开放词汇测试的结果展示
进一步使用视觉语言模型自动从场景中提取名词作为文本查询,例如「鞋子」、「洗手池」等,并生成相应的三维语义占据结果。LegoOcc能够根据自然语言描述进行目标识别,在无需预先学习的情况下完成任务。
面向具身室内场景,本文提出了一种单目开放词汇的三维占据预测框架,采用语言嵌入高斯来统一表达几何与语义信息。该模型在没有体素语义标注的前提下实现了文本驱动的三维语义占据预测。
未来的家用机器人能够高效地将复杂空间中的目标物体定位出来,只需一句「帮我找一下茶几上的遥控器」即可实现精准定位。
周常青:香港科技大学(广州)博士生,专注于开发高效的三维场景理解方法,并重点研究端到端轨迹生成模型和导航任务的高效世界模型构建。
张涵:香港科技大学(广州)红鸟硕士生,致力于探索可靠且高效的三维场景理解技术,目前着重于三维视觉语义定位及适配导航任务的世界模型构建。
江泽宇:香港科技大学(广州)博士生,主要研究高效的空间物理智能体,并专注于将通用空间智能注入现实开放环境的具身应用场景。
陈昶昊(通讯作者):香港科技大学(广州)助理教授,从事具身智能感知、导航与交互的研究工作,并在港科大(广州)组建了PEAK-Lab课题组。他同时也是跨学科学院联署助理教授和博士生导师。
(5)可视化结果
1. 闭集评测结果
在 Occ-ScanNet 的固定类别评测中,LegoOcc 的预测结果与真实标签更为一致,几何和语义预测能力强。(a) 输入图像,(b) 真实标签,(c)LOcc(对比方法),(d)提出的 LegoOcc。
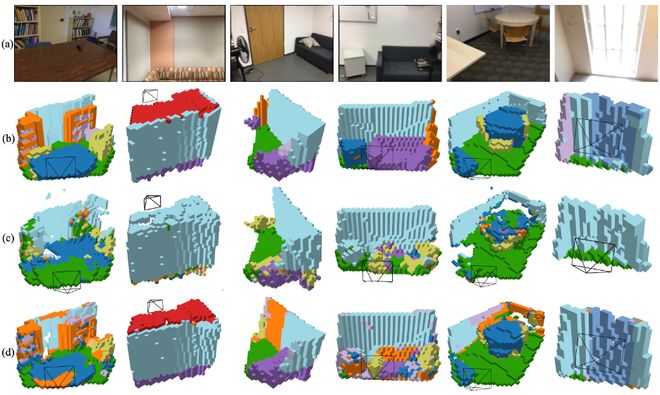
图 3 Occ-ScanNet 闭集测试结果(Closed-vocabulary Results on Occ-ScanNet)
2. 开放词汇测试结果
进一步使用视觉语言模型(Vision-language Model)自动从场景中提取名词作为文本查询,例如「鞋子」「洗手池」「显示器」等,并让模型生成对应类别的三维语义占据预测结果。LegoOcc 不局限于训练时给定的固定类别,能够根据自然语言描述进行三维空间中的目标识别,实现了文本驱动的开放词汇三维查询。
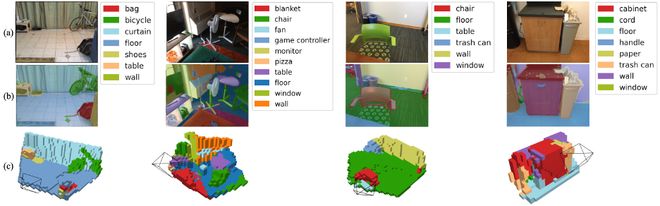
图 4 开放词汇测试结果(Open-vocabulary Results)
展望与意义
面向具身室内场景,本文提出 LegoOcc ,一种单目开放语义占据预测框架,采用语言嵌入的高斯统一表达几何与语义场景信息。几何侧以泊松聚合稳定弱监督训练,语义侧用渐进温度退火削弱特征混合,模型在无需体素语义标注的前提下,实现了文本驱动的三维语义占据预测。
未来的家用机器人能够高效地将三维场景表达为体素网格,只需一句「帮我找一下茶几上的遥控器」,即可在复杂空间中精准定位目标物体,而无需预先「学习」过遥控器这一类别。
作者介绍
周常青:香港科技大学(广州)博士生,致力于高效且稳定的三维场景理解方法研究,当前重点关注端到端轨迹生成模型,以及面向导航任务的高效世界模型构建。
张涵:香港科技大学(广州)红鸟硕士生,专注探索高效可靠的三维场景理解方法,现阶段重点探索三维视觉语义定位方法,以及适配导航任务的高效世界模型构建。
江泽宇:香港科技大学(广州)博士生,主要研究方向为高效的空间物理智能体,专注于将通用空间智能注入现实开放环境的具身应用场景。
陈昶昊(通讯作者):香港科技大学(广州)智能交通学域和人工智能学域助理教授,博士生导师,香港科技大学跨学科学院联署助理教授,从事具身智能感知、导航与交互研究,组建港科大(广州)PEAK-Lab 课题组并担任独立 PI。