允中 发自 凹非寺
最近,是否被GPT-Image-2刷屏了?
它能够精准渲染文字信息图,并且在美学UI和复杂布局上表现出色。
无论是社交媒体截图还是高考试卷,它都能做到几乎一比一的还原效果。
这种技术突破让传统文生图模型显得过时了。
很多人看完后的第一反应是:“设计师的工作要被取代了吗?”
就在这两天,兔展智能发布了UniWorld-V2.5,它甚至可以再现GPT-Image-2的某些优秀案例。
直接展示实际效果:
我们用同一套提示词生成对比图如下:
提示:请创建一张篆书碑刻拓片,并加入“袁粒教授领导兔展智能团队研发”字样

GPT-Image-2的成果:

Nano-Banana-2的效果:

UniWorld-V2.5的结果:
在信息图、文字密集和图文混排等复杂场景中,UniWorld-V2.5已经达到了与GPT-Image-2相当甚至更高的水准。
更值得一提的是,它对提示词的要求非常简短,不再需要复杂的描述。
仅需一句话即可生成丰富的视觉信息图,背后支持的是一整套先进的系统。
接下来让我们看看更多应用场景:
对于高考数学试卷这样的难题,UniWorld-V2.5同样应对自如。
在以往,AI生图遇到结构化排版加上高密度中文和复杂公式时会显得力不从心。
但这次,连复杂的几何图形和函数图像都被完美呈现出来。
这一测试表明UniWorld-V2.5在处理多元素混合的场景上表现优异。
它甚至能够生成一张2025年的高考数学理科试卷。
每个细节都符合规范,清晰明了。
现实中,“能不能直接用于考试”才是评价的标准。

相似的场景还有简历制作:
即使在复杂的排版要求下,UniWorld-V2.5同样表现出色。
而且,在GUI布局方面也实现了突破性的进展。
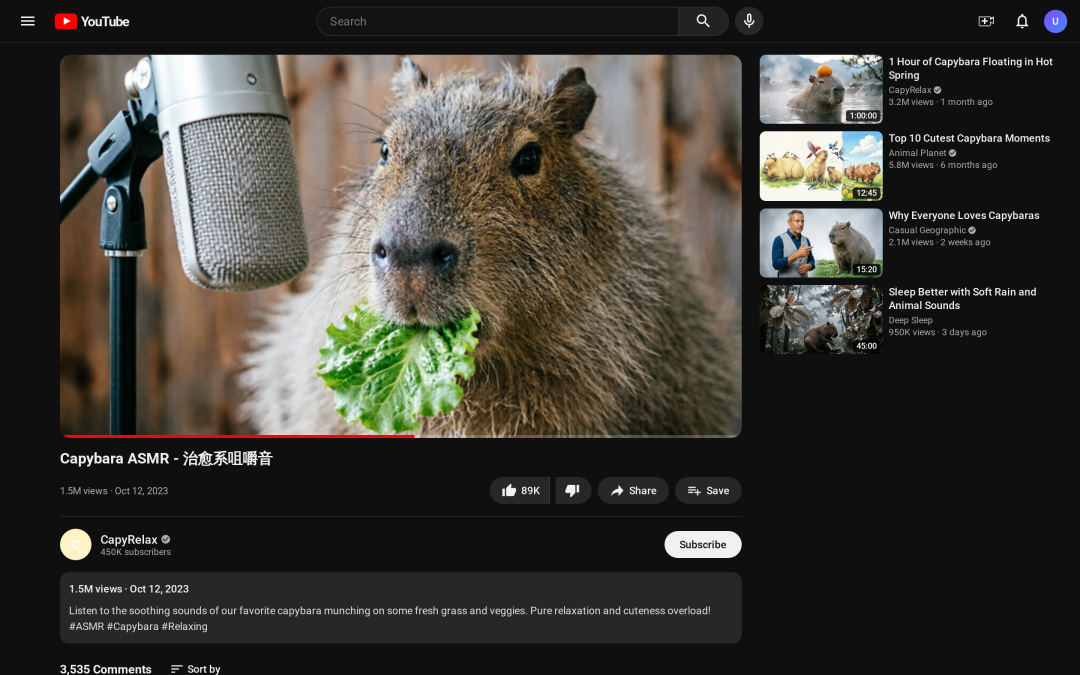
需要AI生成一个真实的社交媒体APP界面?
传统模型常常无法满足这些需求,而UniWorld-V2.5则可以做到完美呈现。

不仅主播、商品弹窗等元素齐全,连打赏特效也一应俱全。
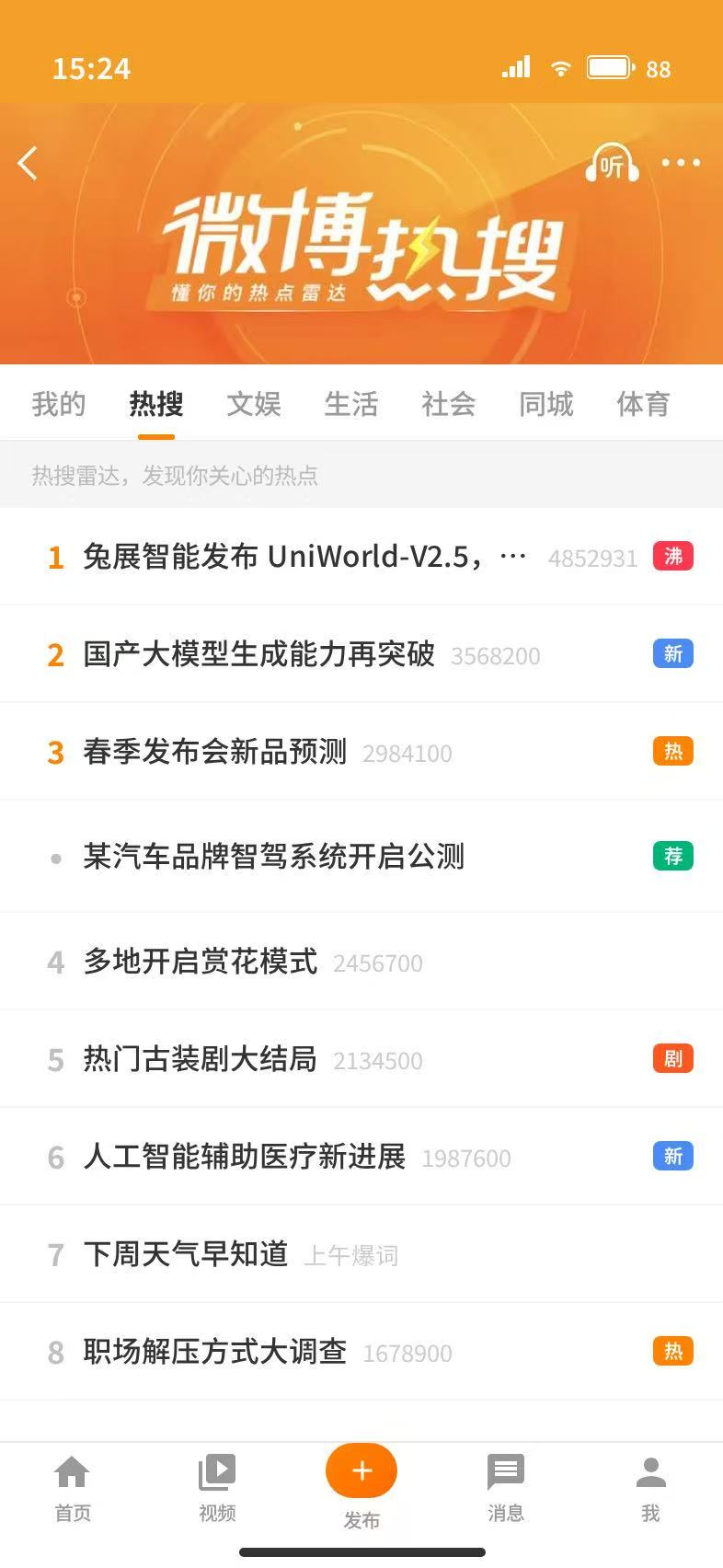
针对具体的应用场景,比如咖啡馆探店界面和微博热搜页面,它也能精准生成相关内容。
这种能力甚至让AI生图变成了“赛博截图”。
UniWorld-V2.5不仅理解像素,更懂得如何构建一个完整的产品逻辑体系。
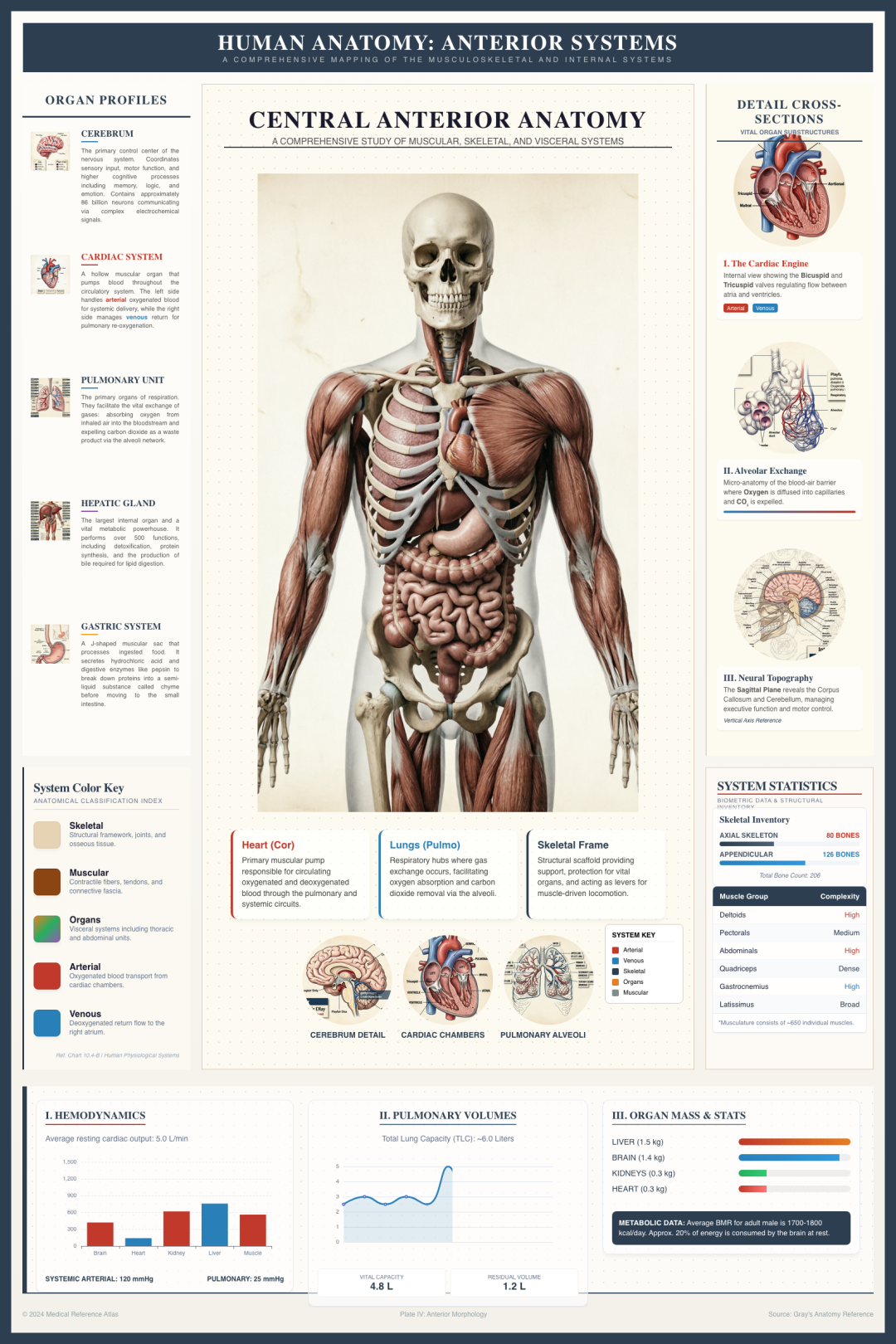
在信息密集的InfoGraph领域也表现出了卓越的能力:
对于复杂的信息图表设计,它同样能给出完美的解决方案。
它不是在绘制一张图,而是在理解和创造整个系统。
1、抖音直播带货
这种能力标志着从“生图工具”到“理解设计的智能视觉生成”的跨越。

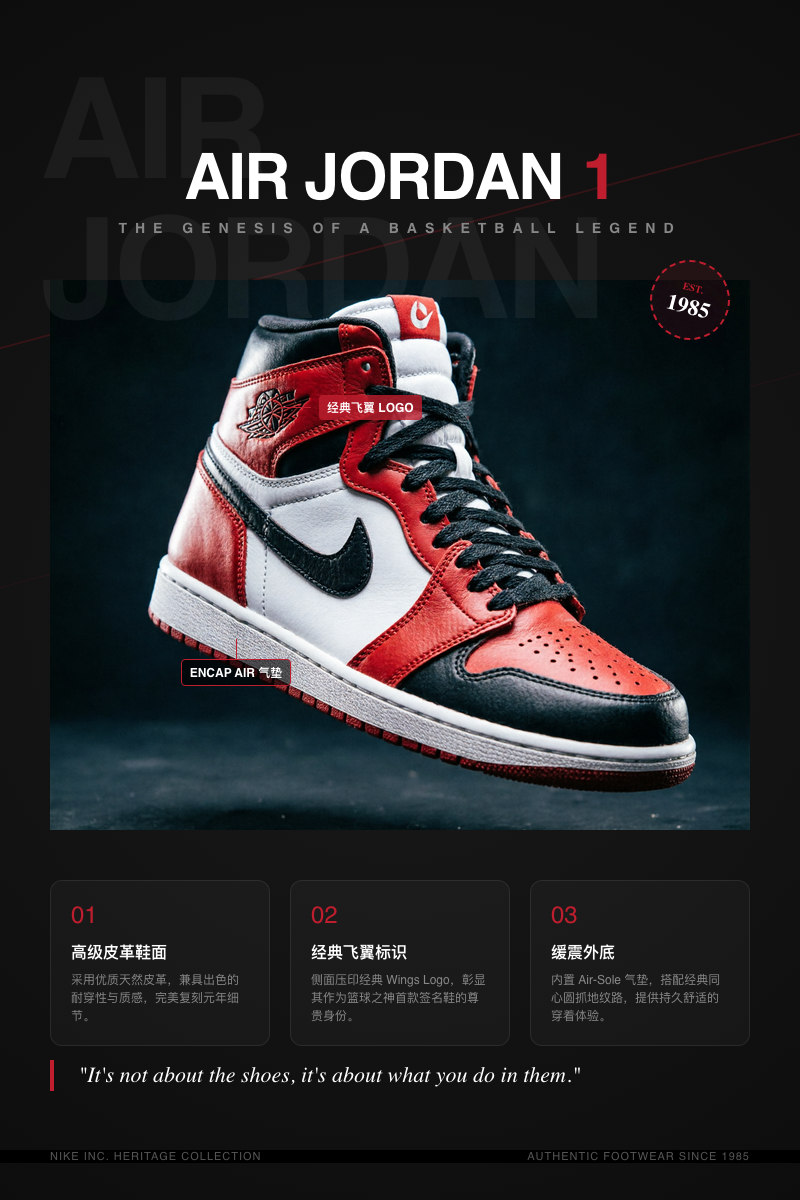
商业级海报的设计同样是它的强项:

不管是Air Jordan 1的产品宣传还是苹果手机广告,UniWorld-V2.5都能够满足需求。
2、小红书探店
它在商业级别的任务上也能展现出色的表现。

国产视觉AI正在迎头赶上国际巨头的步伐:
3、微博热搜
兔展智能公司成立于2014年,并于2022年由袁粒博士等人重新创立。
目前,兔展已服务超过4100万家企业客户,并获得了众多投资机构的支持。
除了商业上的成功,它还是一家国家高新技术企业及专精特新“小巨人”企业。
UniWorld系列为什么能够实现“理解即生成”?
这要归功于其强大的技术基础:
公司自主开发的“兔灵”大模型在视觉理解和压缩重建方面取得了多项突破性成果;
他们还推出了全球最早的开源视频生成模型之一,广受业界欢迎。
UniWorld系列是国内最早实现统一架构设计的视觉空间智能模型之一,并且早于Nano Banana发布。
其中Video LLaVA被Google Gemini Pro报告引用为基准模型,证明了技术实力。
与华为昇腾的合作让UniWorld成为基于国产硬件的大规模用户案例。
UniWorld系列的发展历程如下:
UniWorld V1比Nano Banana早发布三个月,并且同步开源;
太阳系全貌信息图:

绿叶解剖信息图:

UniWorld V2在Nano Banana Pro之前就已经领先行业。
最新的V2.5版本解决了高密度文字、信息图表等多项难题。
当面对复杂的生成任务时,传统的“一句话出图”方式已经无法满足需求。
团队采用了一种新型的范式,将大部分预算用于理解意图和布局规划。
这种方法确保了高质量的结果,并展示了多模态统一设计的优势。
贡献者包括北京大学袁粒教授及其团队成员晏志远等人。
兔展智能一直致力于让人类叙事更加生动高效,创新从未止步。
未来还将推出基于视觉空间智能的世界模型版本。
国产AI生图技术现已达到世界水平:

UniWorld-V2.5的发布展示了在复杂语境下的强大能力。
过去由GPT-Image-2引发的设计行业焦虑如今已被国内的技术突破所取代。
对于需要大量视觉内容生成的场景,现在仅需简单的自然语言提示即可完成工作。
兔展智能。
更重要的是,这展示了中国在多模态图像生成领域的领导地位:
一个源自北京大学、专注于视觉大模型研究四年的团队交出了令人满意的答卷。
公司总部位于深圳,已服务超4100万家企业⽤户。
截至目前,兔展智能已获深创投、腾讯、龙岗⾦控、嘉道资本、中国风投、青岛人工智能基金、招商局创投等头部机构投资,完成F轮融资。
它还是国家⾼新技术企业、国家级专精特新“⼩巨⼈”企业、⼤湾区最具潜⼒独角兽、⼴东省⾸个“AI国家级⾼技能⼈才培训基地”。
兔展智能的UniWorld系列模型,为什么能做到“理解即生成”?
因为它的技术底座早已遥遥领先:
自研“兔灵”大模型:广东省首个完成备案的视觉空间智能大模型,在视觉理解、压缩重建等核心领域实现多项SOTA(业界最佳) 技术突破;
开源第一:其开源的Open-Sora Plan是全球最早的开源视频生成模型之一,曾连续多日登顶GitHub全球趋势榜榜首,单模型超过2600万次下载,2024年视觉大模型代码引用量全球第一,被字节、腾讯、华为等大厂广泛采用;
架构创新:UniWorld系列是国内最早实现“理解、生成、编辑”统一架构的视觉空间智能模型。其中,UniWorld-V1早于Nano Banana三个月推出,UniWorld-V2在权威评测(GEdit-Bench)中综合性能超越OpenAI的GPT-Image-1,多项关键指标亦一度优于谷歌的Nano Banana系列模型,并入选2025年西丽湖论坛深圳市七大科技关键成果、广东省人工智能与机器人科技进步一等奖第一名;
国际领跑:其推出的Video LLaVA模型成为Google Gemini Pro技术报告中作为对比基准的视觉理解模型,标志着技术获得国际顶级认可。LLaVA-CoT模型则在行业内首次提出视觉慢思考架构,让模型能够进行自主、系统化地多阶段推理,突破了传统视觉模型单步响应的局限,该研究成果被ICCV 2025会议收录(计算机视觉领域的三大顶会之一),获得同行评审的权威认可;
国产生态:与华为昇腾深度合作,是昇腾910C芯片全球首个大规模用户,打造了行业最早100%基于昇腾架构的视觉生成模型Open-Sora Plan V1.5,突破了算子适配、大规模训练等一系列“卡脖子”问题。这不仅是一次技术胜利,更是为中国AI基础设施的自主可控,提供了一个完整的可行范本。
值得⼀提的,是UniWorld系列发布的历史时间线:
UniWorld V1⽐Nano Banana早发布整整3个⽉,且同步开源;
UniWorld V2在Nano Banana Pro发布之前,已是⾏业第⼀;
UniWorld V2.5,是这条路上的最新⼀站,突破了高密集文字、信息图、图文交错、结构化生成等一系列领域难题。
面向高度结构化且依赖复杂世界知识推理的生成任务,传统的一句话出图范式已难以支撑。
区别于传统prompt-to-image的范式,团队将超过80%的token预算用于意图理解、推理与布局规划,相当于引入资深的“总设计师”来全程指挥和全局控制。
这从源头上保证了生成的质量,也体现了理解与生成统一的多模态范式优势。
其中,兔展智能首席科学家、北京大学袁粒老师,及其博士生晏志远等人,深度参与了核心能力的设计与实现,是V2.5关键突破的重要贡献者。
兔展智能一直围绕着让人类叙事更生动高效的使命,投入到最前沿的视觉智能创新。
据悉,兔展智能也将在不久之后,推出视觉空间智能路线为基础的世界模型。
站在世界舞台的国产模型,等你免费体验
AI生图的上限,远比我们想象的要高。
UniWorld-V2.5的发布,用实力证明了在中文语境和超复杂逻辑场景下,国产模型已经具备了站在世界舞台中央的底气。
设计行业的“一句话出图”,过去是由GPT-Image-2引发的焦虑。
现在,这个能力在国内坚实落地了,而且是以自主可控、可微调、国产算力的形式落地的。
品牌方、内容平台、电商商家、医疗科普机构、教育出版机构,任何需要大规模生产视觉内容的场景,过去需要设计团队花数小时完成的工作,现在仅需要一句自然语言。
更重要的是这件事的示范意义:
在多模态图像生成这条赛道上,中国不再只能是跟跑。
一个从北京大学走出来、深耕视觉大模型4年的团队,今天交出了这份答卷。