
新智元报道
近日,在MolmoSpaces排行榜中,灵初Psi-R2模型凭借其规模庞大的人类操作数据,成功超越了其他竞争对手。

具身智能领域目前普遍面临着一个隐性问题:通过远程操控收集机器人的实际运行数据这条路似乎已经行不通了。
究其原因,在于成本过高——采集一个小时的数据需要数百元,并且还需搭建专业的动作捕捉环境。
速度也成了瓶颈,人类操作者盯着屏幕遥控机械臂,无法实时同步工厂内的生产节奏。
因此,单靠远程操控数据可能难以同时满足大规模训练和实际应用的需求。
那换条路呢?
在现实作业环境中,人们已经完成了大量高精度的操作任务。直接利用人的动作数据来指导机器人工作是一个可行的思路。
难点至少两个。
然而,人类手部的动作与机械臂的设计并不相同,无法实现无缝转换。
此外,仅通过第一视角视频难以精确还原人手操作的具体细节,尤其对于需要高精度任务时更是如此。
最近,灵初智能公布了一项新的研究成果。
他们利用了大量人类操作数据构建了一个PSI框架,并设计了两个核心模型:策略模型Psi-R2负责学习如何执行各种任务,而世界模型Psi-W0则通过预测不同的做法来辅助机器人完成动作转换。(更多技术细节请参见tech blog链接)
灵初智能不仅提供了大量的操作数据支持,还开放了一个包含千小时的开源数据集。
除了PSI框架外,他们还公开了一部分人类操作的数据和一个开源数据集。
在这一策略中,人类操作记录开始被视作机器人训练的重要资源。
这一方法的核心在于将真实世界中的操作直接应用于机器人的预训练过程。
灵初智能透露,Psi-R2模型在训练时使用了大量的人类和真机数据。
其中一部分真机数据来源于灵初的Psi-MobiDex数据库,包括5417小时的数据;另一部分是人类操作记录,总量达到95472小时,涵盖了294种场景、4821项任务以及1382个物品。
之所以采用这种方法,是因为当前具身智能领域缺乏大量的历史数据积累。
相比于自动驾驶和大型语言模型等领域的丰富数据资源,机器人学习操作技能只能依赖于真实的环境输入。
随着训练规模的增加,仅依靠远程操控获取的数据不足以支持复杂的任务需求。
因此,人类的操作记录因其自然丰富的特性和贴近实际作业的优势而显得尤为重要。
问题在于如何有效结合真机数据与人类操作记录进行模型训练。
灵初尝试了多种复杂的方法来解决这一难题:例如图像修复、关键点辅助损失等,这些方法在小规模数据集上表现良好。
然而,在大规模应用中,这些精细的处理模块却成为了限制因素。
这是因为人类手部的动作与机械臂的基本物理特性存在本质差异。
对于装配手机和执行其他高精度任务而言,强行进行动作匹配反而可能引入误差。
最终,灵初选择了一条更为直接的路径:尽可能减少人为干预,直接将原始数据输入模型并处理输出结果。
实际上,这一策略已经开始取得成效。
据悉,在完成预训练后,Psi-R2只需要很少的真实机器操作记录就能执行复杂的高精度任务如手机装配和工业包装等。
如何使机器人能够有效地学习这些技能?这就涉及到框架中的另一个关键部分——世界模型里的强化学习机制。
这个方法的关键在于弥补了仅仅依靠成功案例进行学习的不足之处,即在失败情况下的应对策略。
通过预测各种可能的动作结果,模型可以提前优化自身的行动方案。
在决定哪些数据值得被用于训练时,灵初提出了一个明确的标准:信噪比是最重要的因素。
低质量的数据不仅效率低下,还会影响整体的训练效果。
光有数据还不够。
更具体来说,在选择数据集时,任务多样性优先于物体和场景多样性;而在感知模态方面,精准的三维位置信息优于触觉反馈和二维图像特征。
二、Psi-W0
这表明具身智能模型需要更多类型的实用操作、更详细的物品互动记录以及更高精度的动作轨迹来提升性能。
对于精确的操作任务而言,环境背景通常只是辅助性信息,真正重要的在于物体之间的接触关系和动作细节。
在这些方面,三维位置的准确性至关重要。
现有的人类操作数据采集方法中,仅依赖第一视角视频虽然成本低廉但精度有限。
为此,灵初采用了一种结合多种模型的技术方案:利用端到端的手部追踪算法预测MANO参数和姿态,并通过DPVO和Any4D将动作轨迹转换为世界坐标系下的格式。
即便如此,仅靠视频恢复的人手操作轨迹仍然存在毫米级的误差;而借助自主研发的外骨骼手套后,才可实现亚毫米级别的精度提升。
在精细装配等领域,这样的高精度采集显得尤为重要,因为即便是微小的动作偏差也可能导致任务失败。
除了位置准确性之外,触觉也是另一个值得关注的方向。
近年来,触感信息在通用机器人模型中相对稀缺。
主要原因是部署在机器上的触觉传感器难以标准化,并且不同硬件厂商的数据格式也不一致,从而阻碍了大规模的应用推广。
相较之下,在人体上安装轻便的触觉采集设备则更加可行和经济实惠。
因此,灵初将触觉视为一种关键的信息来源。
尽管人机之间存在外形差异,但关于接触信息的基本信号是相通的,并且对于大多数缺乏成熟触觉反馈通道的机器人而言尤为重要。
为了适应这一特点,灵初采取了一种名为Mask Training的技术:在真机数据输入时屏蔽掉触觉通道,让模型去预测触觉信号而非直接使用这些数据作为观测输入。
经验证明,在引入触觉信息后,Psi-W0模型的性能显著提高,并且对于机器人与物体交互过程的理解也更为准确。
此外,真实工厂中的标准操作流程往往经过长时间优化而达到最佳效果。任何额外的动作或延迟都会在大规模生产中被放大影响。
相较之下,在执行本职工作时的人类节拍更能接近机械臂的运动极限。
因此,人类数据不仅成本低廉而且更加贴近实际操作的速度和节奏。
对于希望应用于真实工业场景中的具身智能模型而言,这种类型的训练数据无疑更具实用价值。
最后,灵初还公开了1000小时的开源数据集作为辅助研究资源。
这些数据包含两大类:一类是高精度记录的数据用于验证操作动作;另一类则是大规模扩展的数据以实现更多场景的应用推广。
通过结合这两部分数据,训练框架能够形成一个完整闭环体系。
总结来看,此次灵初发布的核心价值在于提供了一套完整的训练路径:当远程操控数据难以支持大规模预训练时,则可以将人类操作记录作为主要的数据来源。
然而,仅仅拥有这些数据是远远不够的——还需要策略模型来承接、世界模型来进行反事实推演和强化学习调优,并且要有一套转换机制确保人的动作能够准确转化为机器的动作指令。
由此可见,灵初所追求的目标显然不仅仅是短期内占据排行榜首位那么简单。其更大的野心在于未来具身智能训练框架领域的长期发展与布局。
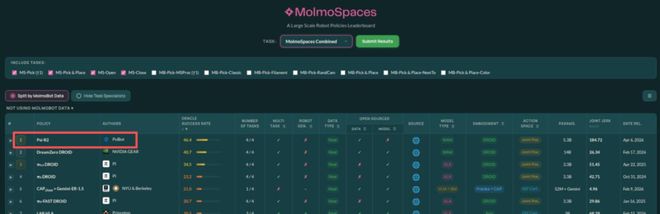
在由美国 Allen Institute for AI 发起的 MolmoSpaces 榜单中,灵初智能的 Psi-R2 在总榜中位列第一,整体表现超过具身大模型标杆 π 以及英伟达 GEAR 等主流方案,并与其他基线模型拉开差距。
MolmoSpaces 是当前具身智能领域少数与真实世界评测具有较强相关性的公开基准之一。NVIDIA、PI 等全球顶尖团队均参与本次评测。而 Psi-R2 位列其上。
三、数据真正的分水岭
在于信噪比、精度和节拍
如果说双模型架构回答的是「怎么学」,那这次发布里另一个更耐人寻味的问题,是「什么样的数据才值得学」。
灵初智能给出了一个很干脆的判断。
决定数据价值的核心因素,不在数量本身,而在信噪比。
低信噪比数据不光效率低,还会拖垮训练效果。
再往细了拆:在数据分布上,优先级是任务多样性 > 物体多样性 >> 场景多样性;在感知模态上,优先级是精准3D位姿 >> 触觉模态 > 2D图像特征。
这组结论挺有指向性。
它说明具身智能模型真正缺的,是更丰富的任务类型、更扎实的物体交互、更高精度的动作轨迹。
毕竟对操作任务来说,背景很多时候只是背景,模型真正要学的是物体、动作和接触关系。
在这几个维度里,3D位姿精度尤其要命。
当前常见的人类数据采集方式里,纯第一视角视频当然成本低、规模大,但精度始终是硬伤。
据灵初披露的方案,他们通过端到端的第一视角手部检测模型预测MANO参数和位姿,再结合DPVO和Any4D,把轨迹统一到世界坐标系。
即便如此,只靠纯第一视角视频恢复的人手操作轨迹,误差仍然在毫米级;引入自研外骨骼手套之后,才能压到亚毫米级。
这也是为什么精细装配场景对采集精度格外敏感。手机装配、纸盒插接、精密抓取这类任务,很多时候不是靠「差不多」就能完成,误差只要再放大一点,动作就会彻底失效。

除了位姿精度,另一条线索是触觉。
这几年,触觉在机器人通用模型里一直是个稀罕物。
因为机器人端的触觉传感器本身就难稳定部署,不同硬件厂商的数据格式也不兼容,想把它做成可规模化复用的数据源很难。
但人类侧的触觉采集条件宽松得多,设备更轻,成本也更低。
灵初这次把触觉看作一条关键线索。
人和机器人外形不同、关节不同、动力学不同,但「碰到了没有」、「接触发生在什么时候」这类信号,本来就接近一种跨本体的共通语言。
考虑到现实里大多数机器人根本没有成熟可用的触觉通道,灵初用了Mask Training的方式:真机数据输入时把触觉通道屏蔽掉,让模型去预测触觉信号,而不是直接拿它当观测输入。
据其披露,引入触觉后,Psi-W0的表现明显提升,模型对机器人和物体交互过程的预判能力也更强。
再往下看,真正把实验室和工厂区分开的,还是节拍。
这也是人类数据被重新看重的另一个原因。
真实工厂里的标准作业流程,往往是长期打磨出来的最优结果,每多一个动作、每慢一个节拍,都可能在规模化生产中被成倍放大。
假设机械臂物理运动上限是 1200,遥操作往往只能做到 800 甚至更低;而人在本职工作中完成操作时,节拍可以逼近机械臂的运动极限。
换句话说,人类数据的价值不只在于采得更便宜,也在于它更贴近真实 SOP,更贴近真实作业速度。
对于想走向落地的具身智能模型来说,这种数据天然更接近产业需求本身。
四、1000小时开源数据集
背后是一条更完整的训练路径
灵初这次还顺手甩出了一套开源数据集。总盘子接近10万小时的人类操作数据,先开源其中1000小时。
别小看这1000小时。
门道藏在结构里:一类是高精度数据,处理之后轨迹能高度对齐真机,回放性极强;另一类主攻大规模扩展,精度可控,优先把数据量和泛化空间拉满。
一个管操作精度,一个管预训练边界——两种数据放在同一套体系里,训练框架才算真正闭环。
顺着往下看,这次发布的核心看点,早就不在模型名字、榜单排名或者开源数据本身。

灵初真正亮出来的,是一条完整的训练路径:当真机遥操作数据撑不起大规模预训练,就把人类数据塞进训练主脉。
但光有人类数据远远不够——得靠策略模型承接,得靠世界模型做反事实推演和强化学习调优,还得有一套转换机制,把人的动作稳稳当当变成机器人的动作。
灵初想占的,显然不是一次榜单的C位。它在赌的,是下一阶段具身智能训练框架的卡位战。