
百度升级GenFlow至4.0版,涵盖全套办公软件,更支持多种AI模型训练
百度近期推出了GenFlow 4.0版本,其中涵盖了Office三件套的所有功能,并且还新增了「牛马虾」系统。 听雨 2026-04-29 12:12:02 量子位
AI5 阅读
共找到 19 篇相关文章
百度近期推出了GenFlow 4.0版本,其中涵盖了Office三件套的所有功能,并且还新增了「牛马虾」系统。 听雨 2026-04-29 12:12:02 量子位

新智元报道AI不再只是童年回忆中的游戏,而是成为了训练大模型的坚实平台:OpenRA-RL将即时战略游戏《红色警戒》改造为AI代理的训练场,并开源了多项关键技术。AI能自己打红警了。近期,Hugging Face推出了一个名为OpenRA-RL的新项目,它让经典RTS游戏成为大型语言模型训练的实际应用环境。这不是简单的演示或玩具级别的展示,而是具备基础设施级功能的真实工具。OpenRA-RL提供了

近期,智平方公开了其最新的“顶配全家桶”——AlphaBrain Platform,这一平台集成了众多先进的技术模块,并提供了从数据处理到模型训练和场景落地的一整套工具链。 田, 晏林 2026-04-23 08:57:43 量子位

随着人工智能的蓬勃发展,对芯片的需求大幅攀升,韩国领先的半导体制造商SK海力士在本财年第一季度实现了创纪录的净利润增长。在4月23日发布的财务报告中显示,该公司在这一季度的营业利润达到了约324亿新加坡元(即37.6万亿韩元),相较于去年同期的7.4万亿韩元有显著提升。SK海力士是美国芯片制造商英伟达的主要供应商之一。 公司指出,“随着人工智能技术从大规模模型训练阶段向代理

在处理复杂的AI任务时,人们往往倾向于编写详尽的说明书或指南来指导模型的行为,但这并不总是最有效的策略。相反,EvoMap团队的研究表明,简洁而直接的经验表示方法——称为Gene——能够显著提升模型的表现。当面对复杂任务或多步骤问题时,人们往往会编写详细的说明文档(Skill)以确保每个细节都被考虑到。然而,这种方法对于AI模型来说并不高效。EvoMap团队提出了一种新的方法:将这些信息压缩为简洁

一家名为Physical Intelligence的新创公司,仅成立两年便在人工智能领域引起了轰动。该公司最近发布的机器人基础模型π0.7具备了执行从未明确训练过任务的能力。比如,在未见过任何相关数据的情况下,该工业机器人能够成功折叠T恤,并使用空气炸锅烹饪红薯,这些成果让整个湾区的AI社区感到震惊。更为引人注目的是,这种能力并非刻意设计的结果,而是在模型训练过程中自然产生的“涌现”现象。Phys

近日,有报道称埃隆·马斯克麾下的xAI与他的太空探索技术公司SpaceX正进一步融合。xAI总裁一职已由SpaceX旗下Starlink高级副总裁迈克尔·尼科尔斯(Michael Nicolls)接任。同时,xAI的模型训练、产品以及基础设施团队也进行了重组和调整。截至发稿时,尚未收到xAI对此事的官方回应。迈克尔·尼科尔斯自2018年起就在SpaceX工作,他在内部备忘录中指出,公司目前在计算资
在2026年,人工智能的发展正以前所未有的速度改变着技术的边界。大型模型训练效率不断提高、具身智能从实验室走向实际应用的步伐加快以及多模态融合技术逐渐成熟等一系列进展描绘了当前最令人振奋的人工智能发展图景。与此同时,代理技术(Agent)的进步正在重新定义人机协作的可能性,并引发了关于如何使这些智能体具备持续学习和自主决策能力的研究热潮。在这样一个背景下,一年一度的 ICLR 成为了观察全球人工智
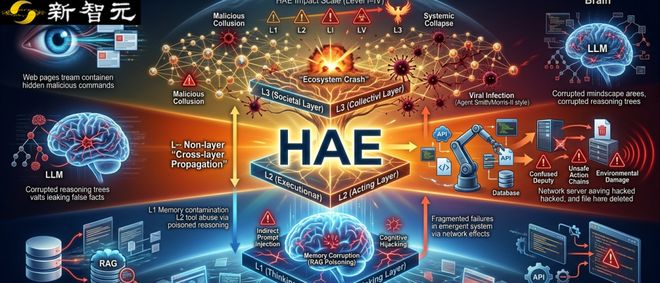
新智元报道当人工智能从被动预测的工具转变为主动决策的实体时,其面临的安全挑战也在经历一场前所未有的变化。在医疗诊断、金融交易和工业控制等高风险领域部署AI系统后,安全问题已经不再是事后修补的问题,而是决定系统能否顺利运行的关键因素之一。目前针对智能体安全性研究的现状存在结构性缺陷:现有的调研往往只关注数据处理到模型训练再到实际应用这一静态过程中的某个环节,或者是将安全、隐私和鲁棒性等特性孤立开来考

中国媒体称,人工智能(AI)公司深度求索(DeepSeek)的多名核心员工在过去一年里离职,下一代模型V4可能会在4月发布。据中国科技媒体“晚点LatePost”报道,去年下半年以来,DeepSeek已有多名核心员工离职。其中,DeepSeek第一代大语言模型的核心作者、参与历代模型训练的王炳宣,去年底被科技巨头腾讯挖走。DeepSeek-OCR系列的核心作者魏浩然约在春节前后离开,DeepSe

MicroCoder团队 投稿量子位 | 公众号 QbitAI新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。微软亚洲研究院与剑桥大学、普林斯顿联合推出MicroCoder,从算法、数据、框架、训练经验四个维度全面升级,在最新代码测试集上取得明显提升,并从七个方面开源了34条训练洞察。背景:旧经验遇上新模型,为何几乎全部“失效”?强化学习正在成为代码大模型能

打破代码大模型训练瓶颈:MicroCoder将算法数据框架训练经验升级 量子位的朋友们 2026-03-30 00:11:35 量子位

近期,Justin Lin发布了一篇关于AI发展趋势的深度文章,详细阐述了从模型训练到智能体训练的转变过程。他指出,当前的AI研究正经历从推理式思考向智能体式思考的转变。 梦晨 2026-03-27 14:19:01 量子位

编译 | 陈骏达你提到你最近一直在探索将大型语言模型简化到最核心的版本,这个项目被命名为micro GPT。你认为这个项目能帮助人们更好地理解和使用语言模型。你提到micro GPT是目前你所能构建的最精简的语言模型代码,整个训练代码只有200行Python(包括注释)。这个模型非常易于理解,因为它不涉及任何为了加速训练而复杂化的代码。通过这个项目,你希望能够向更多人展示语言模型训练的本质。你提到

机器之心编辑部近年来,扩散语言模型(Diffusion LLM)一直是讨论的热点。相较于传统的自回归模型,扩散模型在生成文本时更为灵活,更能支持并行处理。然而,尽管这条路充满潜力,但要真正提升效果却并非易事。最近,华为诺亚方舟实验室发布了一项关于扩散模型训练中“默认设置”的研究。这项研究的标题为《Mask Is What DLLM Needs: A Masked Data Training Par

李水青撰写,云鹏编辑当前AI行业的发展重心已从模型训练转向实际应用,这促使数据基础设施迎来新一轮变革。3月20日,智东西报道,华为数据存储产品线宣布了针对AI时代的三项关键产品与解决方案更新,涵盖传统应用向数据中心的全面转型、AI训练所需的资料准备以及AI推理场景下的基础设施建设。数据存储产品线副总裁肖德刚表示,AI时代为华为数据存储带来了巨大的机遇。在规划时,他们主要考虑了两个方面:一是AI原生

最近,在中国家电及消费电子博览会上,一个最新的成果——采用光路交换技术重塑智能计算网络架构的项目宣告正式落地。上海仪电携手曦智科技、壁仞科技和中兴通讯发布了“光跃超节点128卡商用版”,该产品实现了长期稳定的训练状态,显著提升了模型训练性能,且传输延迟比传统电交换技术减少了90%以上。这款超节点的核心是曦智科技的全球首创硅光OCS光交换芯片。早在去年7月的WAIC大会上,这一项目就已经首次亮相,仅

据Torrentfreak报道,Meta等科技公司曾通过BitTorrent协议从安娜档案库这类盗版资源网站下载受版权保护的书籍,以支持人工智能模型训练。为了构建更强大的语言模型,在没有获得版权所有者许可的情况下,多家技术企业使用了大量受版权保护的内容作为训练数据。Facebook和Instagram的母公司Meta成为了这场集体诉讼中的被告之一。知名作家如理查德·卡德雷、萨拉·西尔弗曼及克里斯托

去中心化的GPU网络定位于为运行AI工作负载提供低成本解决方案,而最新的模型训练依然主要在大型数据中心内进行。在前沿的AI训练中,构建最大的、最先进的系统需要大量高性能GPU协同作业。这种级别的协作对去中心化网络来说是一个挑战,因为互联网上的延迟和可靠性无法与集中式数据中心中的硬件相媲美。大多数生产环境下的AI工作负载不同于大规模模型的训练需求,因此为去中心化的网络提供了更多执行推理任务和其他日常