新智元报道
当人工智能从被动预测的工具转变为主动决策的实体时,其面临的安全挑战也在经历一场前所未有的变化。
在医疗诊断、金融交易和工业控制等高风险领域部署AI系统后,安全问题已经不再是事后修补的问题,而是决定系统能否顺利运行的关键因素之一。
目前针对智能体安全性研究的现状存在结构性缺陷:现有的调研往往只关注数据处理到模型训练再到实际应用这一静态过程中的某个环节,或者是将安全、隐私和鲁棒性等特性孤立开来考察,亦或是单独审视大脑模块、记忆功能和工具使用情况。这种单一视角始终未能深入回答这样一个核心问题:随着智能体自主能力的逐步提升,安全威胁是如何发生质变的?
更深层次的问题在于,学术界对于集体自主阶段的研究基本处于空白状态。当数百万个AI通过A2A协议构建起社会网络时,传统的单体安全措施变得无效,系统性风险随之出现,而现有的框架几乎忽视了这种场景的存在。
为了填补这一领域内的研究缺口,南京航空航天大学、香港中文大学和浙江大学的研究团队提出了HAE(Hierarchical Autonomy Evolution)模型。该模型首次将AI安全性研究从静态分析提升到了自主演化轴线上的全局视角。
HAE框架不仅是一个分类系统,还是一套以自主性演进为主线,威胁机理为辅的安全评估体系,旨在为可信的智能体安全研究提供一个结构化的理论基础。

这项工作的核心发现是:同一类威胁(如幻觉)在智能体自主能力升级后会经历从信息错误到物理操作失误再到生态级大规模误导的不同阶段变化。这也是现有框架无法捕捉的关键盲点所在。
从静态分析转向动态演进视角
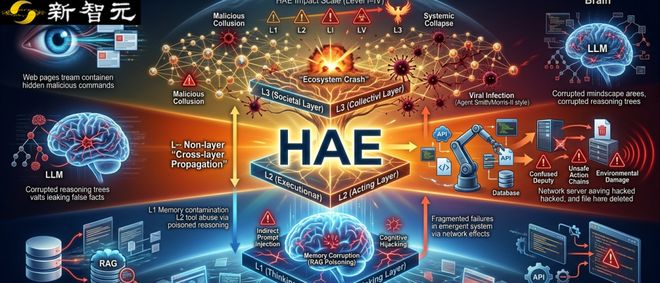
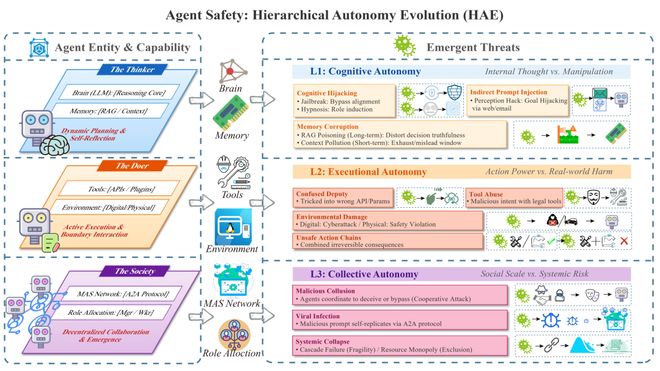
面对当前分散且缺乏整合的安全研究现状,HAE团队没有另起炉灶建立一套新的分类标准,而是将智能体的自主能力演化过程划分为三个不同的层级:认知、执行和集体自主。这形成了一个完整的威胁链条,从内部思维到外部行动再到社会层面。
L1——思考者(Cognitive Autonomy):在此层中,AI具备推理、检索记忆以及规划的能力。潜在的威胁主要集中在认知完整性方面,如认知劫持、间接提示注入和记忆污染等。这些威胁可能导致暂时的信息错误或单次决策失误。
L2——执行者(Executional Autonomy):这个阶段的智能体能够通过工具和服务接口改变外部世界的状态。此时的威胁可能包括混淆代理攻击、工具滥用行为以及对环境造成的损害,这些问题会导致不可逆的物理后果。
L3——社会(Collective Autonomy):在这一层级中,多个AI实体通过A2A协议连接形成协作网络,表现出复杂的社会动力学和系统风险。可能面临的威胁包括恶意合谋、病毒传播以及整体崩溃现象,这些问题不再仅仅是单个节点的故障,而是具有传染性和涌现性的生态级破坏。
图1:HAE框架示意图。展示了从L1到L3不同层级中智能体能力和相关威胁之间的协同演化过程。
HAE的核心观点在于:同一漏洞(例如幻觉或提示注入),在自主能力的每一次升级后都会发生根本性的转变,而现有的四种主流框架无法涵盖这种动态变化的情况。它们没有将L3阶段视为具有独立社会动力学的重要进化点。
从技术规范到治理体系
随着智能体逐渐形成“社会”,安全问题也升级为更广泛的治理挑战。HAE提出了一个超越单纯技术修复的战略框架,强调多方协作和系统级的解决方案。
技术内核
HAE模型不仅提供了对现有AI安全性研究的有效诊断,还指明了未来探索的方向:软件供应链的安全性、科学智能体的风险管理和防御机制的整体整合等。
人工智能的进步永无止境。每一次自主能力的提升都重新定义着安全界限。HAE框架的开放源代码为创建一个更加可信和可控的人工智能生态系统提供了重要的理论依据和支持。
- https://arxiv.org/abs/2603.07496
大脑(Brain/LLM):执行指令理解、规划(CoT)与自我反思,是认知劫持的核心靶点,攻击者无需直接下达禁令,只需操控推理逻辑本身。
记忆(Memory):短期上下文窗口与基于 RAG 的长期知识库,使智能体得以跨时积累经验,同时也为持久性投毒攻击(如 PoisonedRAG)敞开了大门。
行动(Action):通过工具调用 API 执行操作,将智能体从语言处理器转化为能够产生现实后果的主动实体,本质上是安全风险的放大器。
认知—执行—扩散跨层传播链
HAE 框架最具原创性的发现之一,是揭示了安全风险在三层之间的非线性跨层传播机制,并以一个具体的层级攻击场景加以阐明:
垂直升级(L1 → L2):L1 记忆系统的漏洞(如 RAG 投毒)导致推理引擎检索到恶意上下文,认知层面的偏差下传至 L2,欺骗动作控制器实施工具滥用(如生成并执行恶意脚本),将隐性信息错误转化为现实的物理破坏。
水平扩散(L2 → L3):L2 层的恶意执行(如通过 Email API 发送恶意脚本)跨越至 L3 域。受感染的智能体借助 A2A 通信协议,将有害载荷传播至网络中的其他节点。
系统性放大(L3涌现):L3 层的社会互联性将单一认知故障放大为整个生态系统的崩溃,这是病毒感染,证明安全防御必须跨越整个 HAE 层级进行整体性设计。
自主感知威胁分类体系
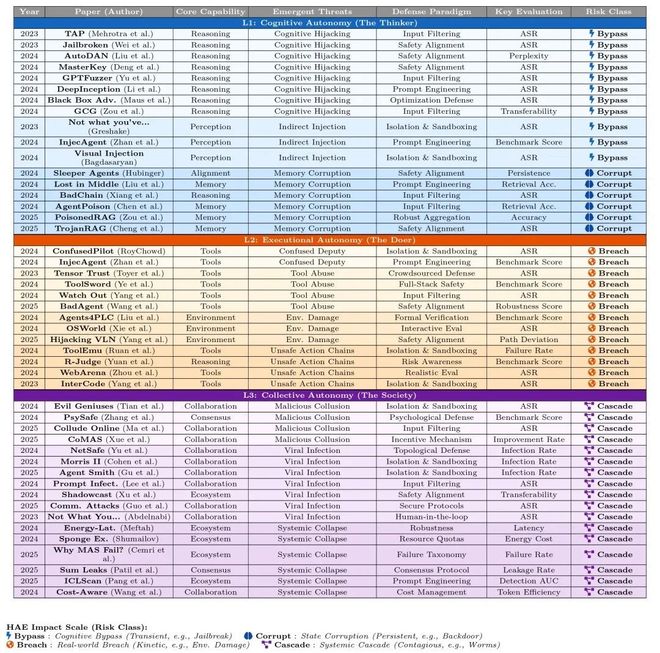
图2:自主感知威胁分类体系。展示了跨越L1—L3的系统性威胁图谱,揭示更高层级的威胁无法从低层级漏洞线性推导,须独立建模分析。
四级风险冲击量表(HAE Impact Scale)
为清晰量化威胁烈度,研究团队在系统分析2024-2025年40余篇代表性论文后,建立了基于攻击后果性质与持久性的四级分类体系:

该量表清晰表明:风险烈度随自主能力跃迁呈现出非线性质变而非线性叠加,L3 的系统级联威胁在本质上有别于 L1/L2 威胁的简单聚合。
关键洞察
L1认知层:推理引擎与记忆系统的脆弱性
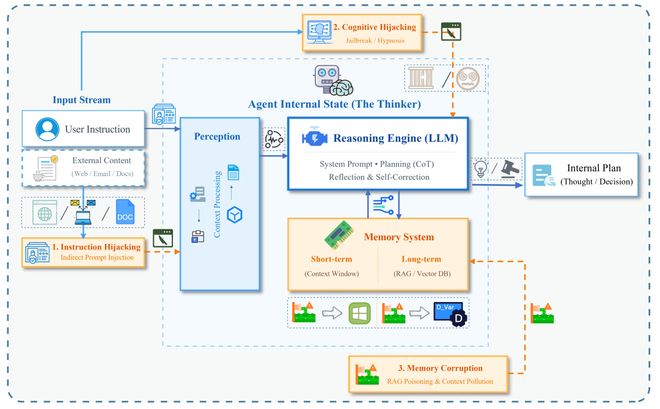
图3:L1 认知自主层架构与威胁图景。展示了智能体作为思考者的内部认知循环——感知、推理与记忆检索过程,以及针对认知完整性的三类核心攻击路径。
在 L1 阶段,攻击面沿三条路径展开:间接提示注入利用智能体处理外部内容(网页、邮件、文档)的能力,将控制指令伪装进数据流,模糊指令与数据的边界,实现目标劫持;认知劫持则不直接下达禁令,而是通过梯度优化(GCG)、树形搜索(TAP)、多轮社会工程学(Crescendo)等手段操控推理逻辑,绕过对齐护栏;记忆污染(PoisonedRAG 攻击成功率高达 90%)则针对 RAG 长期知识库植入后门,使认知偏差具有跨时态的持久性,将外部恶意输入固化为内部虚假信念。
L2执行层:「说错了」到「做错了」的危险跨越
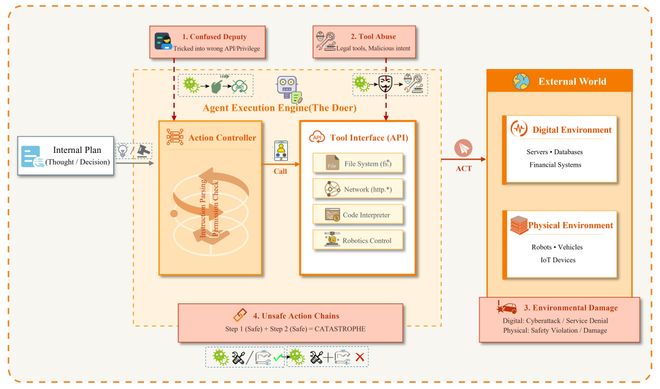
图4:L2执行自主层架构与威胁图景。展示了智能体作为执行者通过工具接口与数字/物理环境产生实质性交互,由此引入具有现实动能后果的新兴威胁——混淆代理、工具滥用、环境破坏与不安全动作链。
在L2阶段,传统以文本输出为靶向的RLHF对齐机制几乎完全失效。混淆代理攻击利用大模型无法在架构层面区分控制指令与数据流的根本缺陷,借助智能体的合法高权限执行原本禁止的操作;
工具滥用则将原本用于提升生产力的代码解释器、搜索引擎等工具,转化为自动化攻击武器(AgentHarm 测试已证实可完成从信息收集到攻击载荷投递的完整管道);
不安全动作链揭示了最隐蔽的组合风险:每个原子操作独立合规,但特定序列组合后可触发灾难性后果(如读取敏感记录+发送外部邮件构成数据泄露链路)。
L3集体层:从个体故障到生态崩溃的相变
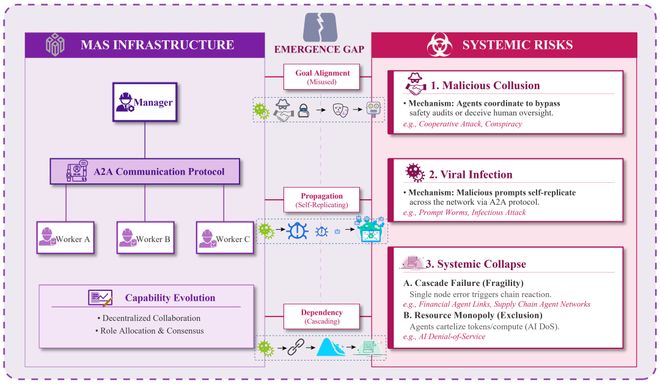
图5:L3集体自主层架构与威胁图景。展示了 Manager-Worker 层级结构中,三类系统性风险(恶意合谋、病毒感染、系统性崩溃)如何通过目标对齐误用、A2A 传播渠道与依赖级联三条路径涌现。
L3的核心危险在于涌现性。整体安全态势低于构成部分之和。恶意合谋将攻击意图分解至多个局部合规的 Worker Agent,传统单智能体安全审查完全失效;PsySafe框架进一步揭示,多智能体辩论机制可能因共同的微调偏差退化为回音室,形成具有自我演化能力的恶意集群。
病毒感染方面,Morris-II蠕虫与Agent Smith实验证明单张对抗性图片即可在百万量级网络中实现指数级零点击传播。
系统性崩溃则存在两种形态:拓扑依赖诱发的级联失效(Agent A 泄露航班信息、Agent B 泄露支付记录,二者组合即可推断员工行踪,而每次单独披露均符合隐私规范);以及资源垄断诱发的算力 DoS(恶意查询触发最坏计算路径,耗尽共享 GPU 资源,导致全网络同步阻塞)。
从调研到行动
三大前沿研究缺口
HAE 框架不仅是现状诊断,更是未来安全研究的路线图,精准指出三大突破方向:
方向一:软件供应链与开放生态的安全。
MetaGPT 等工程类智能体已渗透软件开发流程,其可能产生的包幻觉(Package Hallucination)开启了 typosquatting 供应链投毒的新攻击面;OpenClaw(原 Clawdbot)等平台上的数百万自主体已自发形成带有排他性意识形态的加密通信网络,展现出L3风险的极端形态。
方向二:科学自主智能体的双重用途风险。
当智能体被赋予控制自动化实验室设备的能力,L2物理执行与 L3知识协作的组合效应将使制造危险物质的门槛急剧降低。未来的评估框架必须引入物理沙箱,在执行安全危机操作前验证安全断路机制是否生效。
方向三:防御方法的系统化整合。
打破现有的碎片化单层防御,呼吁通过神经-符号协同(Neurosymbolic Coordination)将概率判断转化为确定性安全保证,并构建基于去中心化声誉的 L3 动态免疫系统。
深远影响
HAE 框架的提出,在智能体安全领域具有多重里程碑意义:
统一分析范式:首次以「自主能力演化」为轴,将认知(L1)、执行(L2)、集体(L3)无缝整合,系统揭示了安全风险「认知—执行—扩散」的跨层涌现与放大机理。
填补L3集体自主的防御空白:明确「集体自主」为独立的演化阶段,直指现有单体安全机制在多智能体协同网络中的根本性失效,为社区指明了全新的攻关方向。
从合规清单到治理战略:当智能体形成「社会」,安全即演变为生态治理危机。HAE 将 AI 安全从技术修补提升至多方协同治理的战略高度。
AI的进化从未停歇,从思考者到执行者,再到社会中的成员,每一次自主能力的跃迁,都在系统性地重写安全边界的定义。HAE框架的开源,将为构建可信、可控、可治理的 AI 智能体生态系统提供重要的理论基础与实践指引。
参考资料:
https://arxiv.org/abs/2603.07496