
神秘项目“Elephant”真相大白:能耗仅十分之一,却拥有顶级代理性能
近日,在科技领域内备受关注的蚂蚁百灵,正式对外发布了 Ling-2.6-flash 大模型。这款拥有 104B 参数总量和 7.4B 激活参数量的新产品,以“Token 效率”为核心特色,能够提供更快、更经济且更加适合大规模实际应用的智能化服务。自匿名测试版“Elephant Alpha”在 OpenRouter 上线以来,仅一周时间便引起了业界的高度关注。上线后,“Elephant Alpha”
科技3 阅读
共找到 195 篇相关文章
近日,在科技领域内备受关注的蚂蚁百灵,正式对外发布了 Ling-2.6-flash 大模型。这款拥有 104B 参数总量和 7.4B 激活参数量的新产品,以“Token 效率”为核心特色,能够提供更快、更经济且更加适合大规模实际应用的智能化服务。自匿名测试版“Elephant Alpha”在 OpenRouter 上线以来,仅一周时间便引起了业界的高度关注。上线后,“Elephant Alpha”

最近有一项实验引发关注:一位CTO花费大约1.5万元人民币的API费用,并使用大量Token,让Claude在一周内攻破了Chrome浏览器的安全防护。近来,“Mythos”一词频繁出现在网络安全圈。Anthropic研发了一款能够挖掘漏洞的AI模型,但由于担心被恶意利用而未予发布。听起来像是科幻电影的情节?实际上,现实可能更为贴近:当“Mythos”还在实验室阶段时,它的前身Claude Opu

新智元报道Anthropic近日发表了一篇博客,详细介绍了如何管理“上下文腐烂”这一问题,并且承认了即使拥有百万token的庞大上下文空间,模型也可能因信息过多而变得不那么聪明。他们是否打破了关于百万级上下文窗口的概念神话?https://claude.com/blog/using-claude-code-session-management-and-1m-context在这篇新博文中,Anthr

Anthropic近日发布了一项指南,介绍如何在Claude模型中有效管理上下文信息,并解释了为何过量的上下文数据会使模型性能下降。近日,官方博客上的一篇文章揭示了Claude模型在处理百万级别上下文时遇到的问题。该文章重点讨论了一种被称为“上下文腐烂”的现象,即随着对话长度的增长,模型的表现会逐渐降低。Anthropic表示,所谓的上下文窗口是指模型生成回复时能够参考的所有信息集合,包括系统提示

新智元报道【新智元导读】Opus 4.7发布48小时,口碑两极撕裂。官方榜单并列全球第一,逻辑推理公开测试却从94.7%暴跌到41.0%。token消耗涨了35%,旧接口直接报错,用户集体控诉「更贵、更蠢、更爱顶嘴」。Anthropic到底升级了什么,又搞砸了什么?「4.6根本没法用,4.7的消耗速度像核反应堆一样。」Opus 4.7发布后,一位Reddit用户在Anthropic官方帖子下的留言

新智元报道最懂Harness的并不一定是跑分最高的,如今MiniMax已被Hermes、OpenClaw等热门开源Agent项目确立为默认选择,在OpenRouter上的日均Token消耗已突破3000亿。昨晚在B站上一位外国用户用四个字引发了一场热烈讨论。不熟,勿Cue。汤米·伊斯曼,作为全球最流行的开源Agent项目Hermes Agent的业务负责人,对此发表了看法。他首次来到中国就受到了观

新智元报道一项长达20天的审批流程中,AI系统预计能够提高效率超过150%,单个任务的成本也将显著降低至人工处理成本的五分之一以内,并且每个任务的token消耗严格限制在50k以内。在即将来临的2026年,“Harness”一词成为人工智能领域最热门的话题,超越了模型和记忆的概念,尽管这个术语听起来有些陌生。马具,缰绳,驾驭。最近,Anthropic在其Claude Platform上推出了Man

近日,一款名为Elephant(大象)的匿名AI模型在OpenRouter平台低调登场。上线短短两天内,这款模型便跃升至OpenRouter热门榜首位,并且调用量已超过1850亿个token。在OpenRouter的日排名中,Elephant位列全球第八。据OpenRouter的介绍,Elephant是一款拥有100B参数量的纯文本模型。它的亮点在于高效的token效率和强大的上下文支持能力,可处

近日,OpenAI对其Agents SDK进行了功能更新。新增的原生沙箱执行环境提升了智能体的安全运行能力,并支持在指定工作空间内处理文件和使用经授权工具;同时实现了管控框架与计算资源分离的设计,增强了系统的安全性、稳定性和可扩展性。此次更新中,OpenAI通过API向所有用户开放了新的功能。定价模式沿用标准API计费方式,根据token使用量及工具调用次数来收费。全新引入的沙箱和管控框架首先会在

荣耀最新推出的YOYO Claw技术成功降低了养虾成本。 梦瑶 2026-04-16 12:53:31 量子位 这项创新技术帮助用

这篇文章由陈骏达编辑和李水青撰写。据智东西报道,在4月15日举行的酒仙桥AI产业高峰论坛上,中国计算机学会前理事长、中国工程院院士郑纬民以及新加坡工程院院士兼香港中文大学(深圳)人工智能学院院长李海洲等多位专家分享了他们对当前AI发展阶段的看法。郑纬民指出,随着智能体时代的到来,token成为了衡量智能化水平的关键单位。他认为,AI产业的竞争焦点已从比拼算力集群规模转变为每瓦能量生成的token数

最近两个月养龙虾的人可能会遇到几件烦心事:安装环境配置的困难、月底账单上的Token费用像滚雪球一样增加,以及每次授权时对数据安全性的担忧。这种情况并非偶然。自从OpenClaw兴起以来,整个行业一直未能解决这些难题。4月13日,荣耀在西安正式发布了自主研发的YOYO Claw龙虾技术(AI智能体系统),该技术将被应用于荣耀MagicBook系列轻薄笔记本电脑中,开创了养虾本的新类别,并声称能够一

智谱在发布GLM-5.1并提高Token价格后,其股价连续三天上涨,市值突破4000亿港元。然而,在当前形势下,讲好一个完美的Anthropic故事对智谱来说仍有许多工作要做。在科技新兴公司的竞争中,“不卷”已成为一种比“卷”更为昂贵的特权。4月8日,即财报发布一周后,智谱推出了新一代旗舰模型GLM-5.1,并将Token价格提高了10%。这次调价之后,其编码场景定价已经接近Anthropic的C
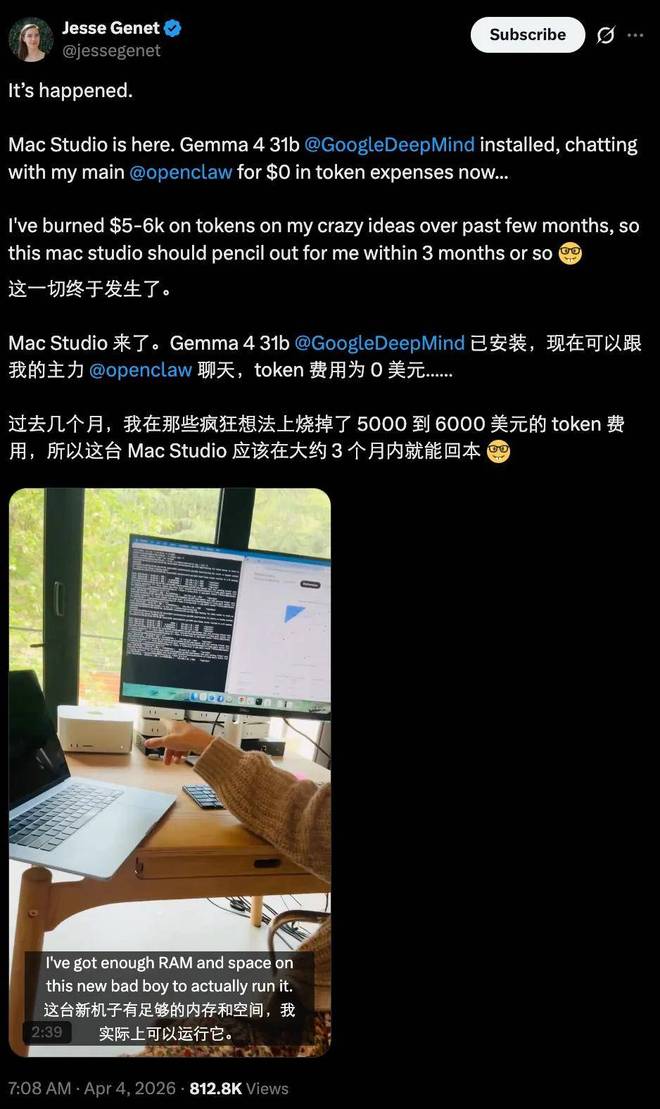
机器之心编辑部许多用户都在他们的 iPhone 上运行 Gemma 4,并对其互动体验给予了积极的反馈。尽管模型能够流畅地回答简单问题,但在处理较长对话或进行深度思考时速度较慢,且可能导致手机发热和电池快速耗尽。最近,一些技术爱好者开始在电脑上尝试另一种方法:将 Gemma 4 连接到龙虾(OpenClaw)系统中运行。初始阶段,这种做法仅限于少数人的实验。例如,一位博主声称,在 Mac Stud

最近,《科创板日报》报道指出,在“养虾”热潮的影响下,大模型企业和云服务提供商的访问量和Token使用量持续上升。AI产品最新榜单显示,OpenClaw在3月份吸引了高达2948万次的浏览量,并且成为AI龙虾排行榜的第一名。与此同时,各个主要云服务商如百度智能云、火山引擎、腾讯云及阿里云等,由于“养虾”活动的影响,其访问量均显著增加。特别是百度智能云增长了105%,而火山引擎和腾讯云分别增加了81

一款能够大幅节省Token的神器,在短短三天内就吸引了超过4,100颗星的关注,开发这款工具的是一个年仅19岁的小伙子。 一水 2026-04-08 11:28:15 量子位
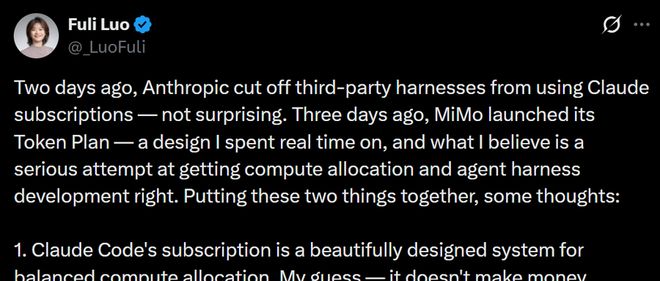
以下是对一篇关于小米大模型负责人罗福莉分析文章的重新表述。在4月6日,Xiaomi MiMo的大模型项目负责人罗福莉于社交平台X上发表了一篇文章,对Anthropic近期采取的新措施进行了评论,并对其Token Plan策略进行了解释。她在文中详细探讨了算力分配和定价逻辑的问题。罗福莉在她的社交媒体帖子中分享了一些观点(图源:X)。4月4日,Anthropic宣布禁止使用包括OpenClaw在内的
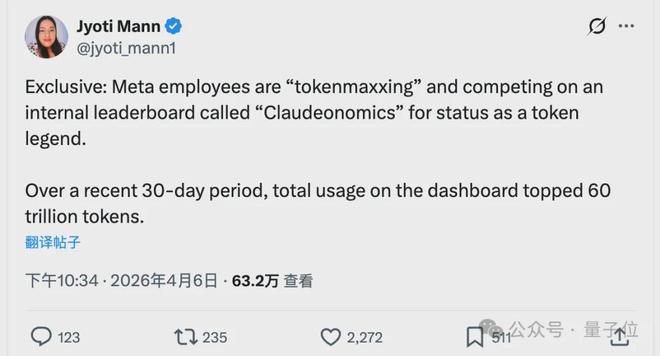
克雷西 发自 凹非寺量子位 | 公众号 QbitAIMeta内部掀起了一场“烧Token”竞赛,亚历山大王将其推向了新的高度。在这位首席AI官的引领下,Meta每天消耗的Token数量惊人地达到了两万亿,相当于重新处理整个维基百科四十余次的内容。排名首位的一位超级用户更是一个月内使用掉2810亿个Token,平均每日消耗93.6亿。扎克伯格此前曾下达指令,要求用AI全面重写公司的代码库,以确保人工
最近,“词元”这个AI领域的关键术语,随着国家数据局的正式命名而迅速走红网络。截至今年三月的数据表明,我国每日的词元调用量已超过一百四十万亿次,与年初相比增长了上千倍。实际上,“词元”一词早已深入我们的日常生活,并在新技术和新应用的发展中扮演着重要角色。我们既要积极接受并利用这些技术,同时也要重视潜在的风险,确保信息安全。“词元(Token)”具体是指什么呢?从本质上讲,词元是AI大模型处理信息的

开源社区在短短两天内就完成了卡帕西未竟的工作,构建了一个完整的知识库,并节省了高达七十余倍的token消耗。 闻乐 2026-04-07 13:50:13 量子位