机器之心编辑部
许多用户都在他们的 iPhone 上运行 Gemma 4,并对其互动体验给予了积极的反馈。尽管模型能够流畅地回答简单问题,但在处理较长对话或进行深度思考时速度较慢,且可能导致手机发热和电池快速耗尽。
最近,一些技术爱好者开始在电脑上尝试另一种方法:将 Gemma 4 连接到龙虾(OpenClaw)系统中运行。
初始阶段,这种做法仅限于少数人的实验。例如,一位博主声称,在 Mac Studio 上安装了 Gemma 4 的 31B 版本,并认为这样可以节省 token 费用,从而在三个月内实现成本回收。然而,这一论点的有效性仍有待进一步验证。
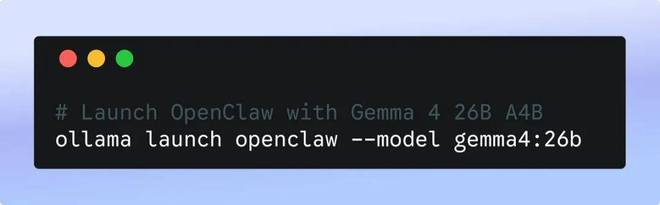
最近,谷歌 Gemma 团队发布了一份官方指南,详细说明了如何将 Gamma 4 和龙虾连接起来的步骤。
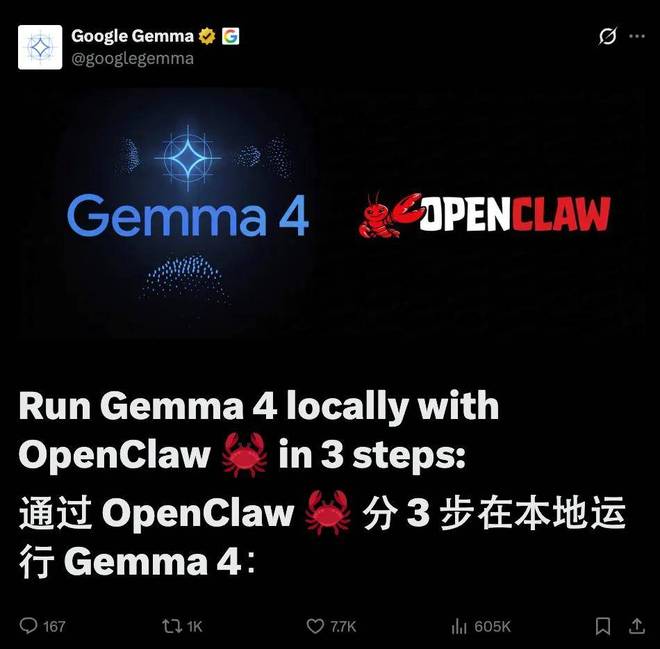
第一步是下载并安装 ollama,网址为 https://ollama.com/download
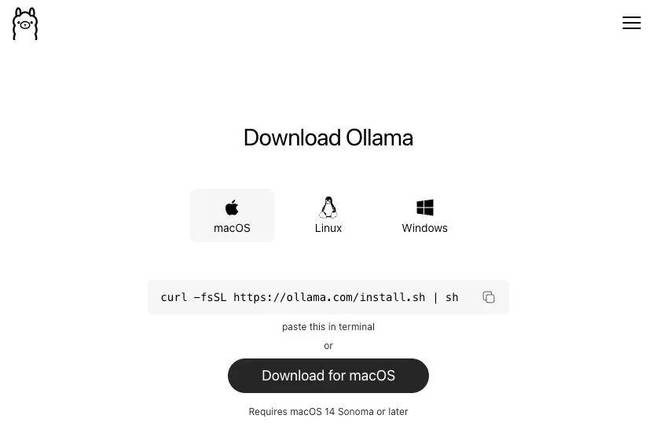
接下来,在你的设备上准备一个合适的 Gemma 4 版本(推荐使用 26B A4B)。虽然这一步可以省略,因为最终会通过 Ollama 完成所有配置。
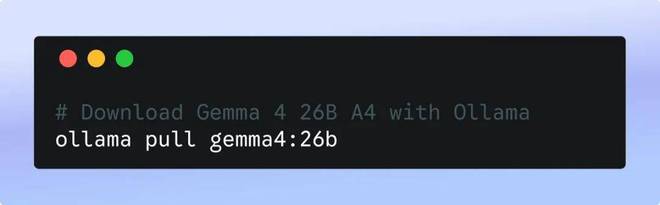
最后一步是利用 Ollama 启动 OpenClaw,并指定它使用 Gemma 4 的 26B A4B 版本。此过程将自动安装所需的软件并启动系统。
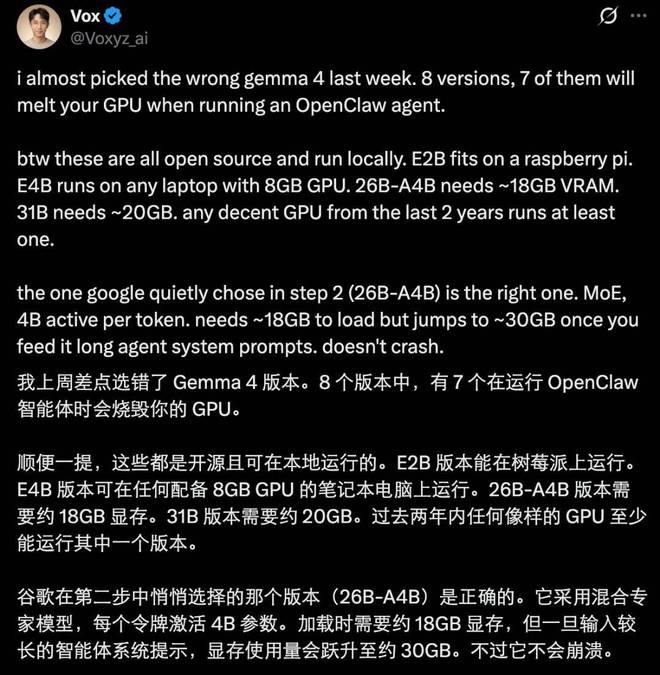
根据不同的计算机配置,选择合适的 Gemma 4 版本至关重要。有人建议,如果想要运行官方推荐的 26B A4B 版本,需要一台如 Mac Studio M4 Pro 48GB 或性能相近的机器。

在显存方面,需求也会因设备而异。对于配备 M4 Pro 48GB 的 Mac Studio,16GB 显存可能已足够;而对于带有 GPU 的笔记本电脑,则至少需要 18GB 的显存。
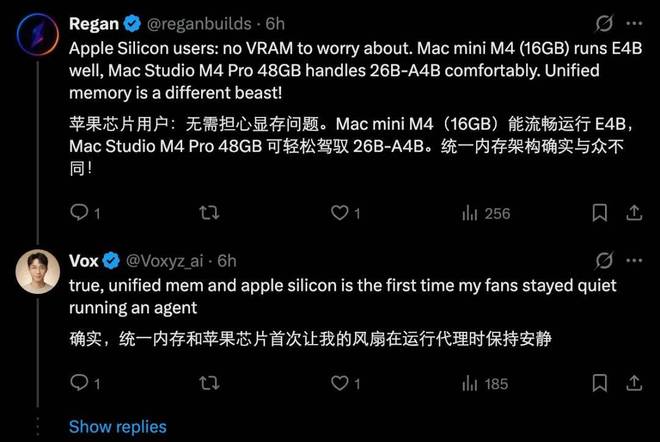
许多人对谷歌发布的教程表示赞赏,认为它极大地简化了在本地运行 Agent 的过程。之前的技术人员经常面临复杂的调试问题和各种技术难题。现在,通过简单的三步操作即可轻松部署,这标志着一个重要的进步。

实际上,即使是最新的 Gemma 4 版本,在智能水平上与 Opus 等顶级模型相比仍有一定差距,并且在工具调用和长对话处理方面存在明显的局限性。这些因素引发了人们对本地部署这一模型实用性的质疑。
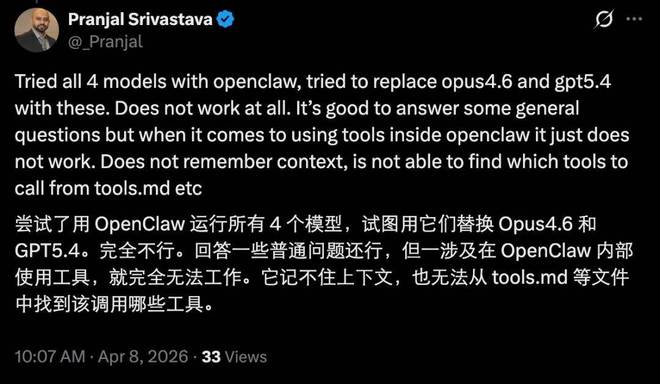
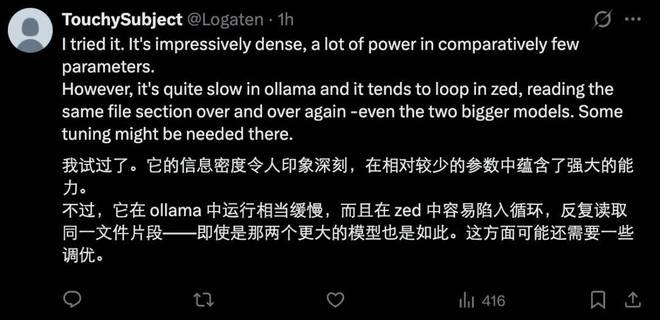
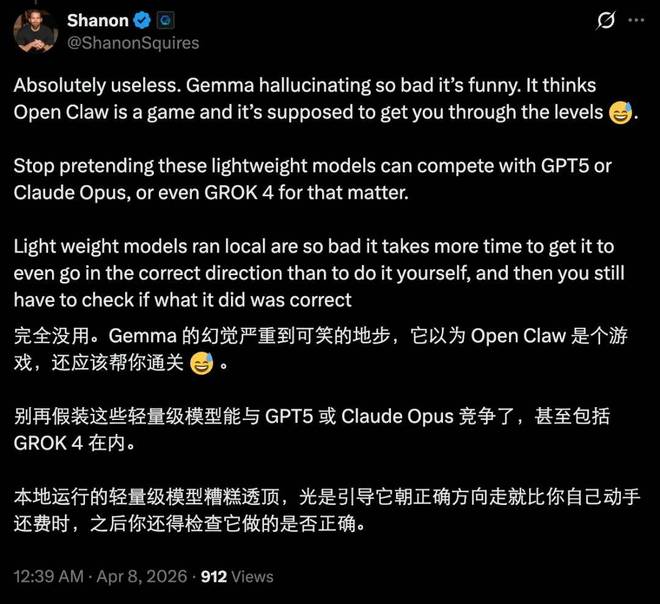
不过也有人认为,对于较为简单的任务(如简报制作、会议记录和定时任务),使用本地模型还是非常实际和经济的解决方案。

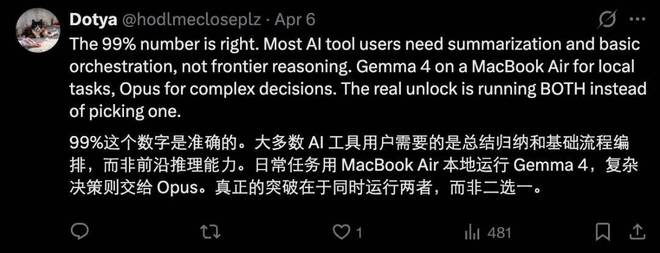
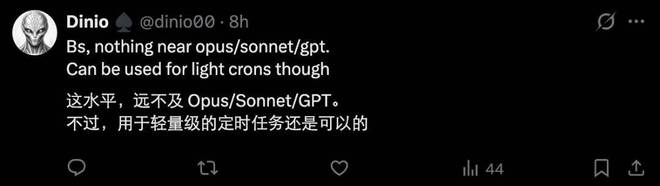
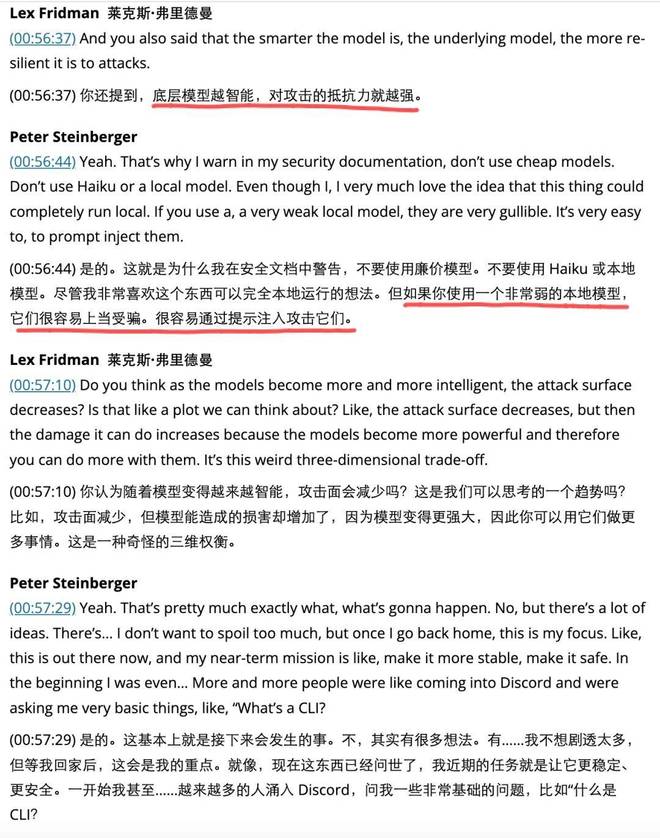
另一个值得关注的问题是,在 OpenClaw 中运行小型模型的安全性问题。
龙虾项目创始人 Peter Steinberger 曾在一次采访中警告,不要轻易使用低成本的小型模型或本地模型,因为它们更容易受到提示注入攻击,而更智能的系统则能更好地识别此类威胁。
因此,在决定是否采用这种部署方式时,用户需要权衡利弊,谨慎考虑。