
AI赋能Token流通:清程极智师天麾解析智能化Agent时代的新路径
2026年4月21日至22日,“奔赴AGI 重塑未来”为主题的中国生成式AI大会(北京站)圆满落幕。大会汇聚了73位来自学界、业界及投资界的嘉宾,通过一场开幕式和多场专题论坛与技术研讨会的形式,全面解析了AI产业的脉络、创新模式以及Token经济等议题,并探讨了在中国市场的机会。会议内容广泛涵盖了大语言模型、多模态模型、世界模型、智能体到AI眼镜等一系列前沿技术和应用,同时也涉及数据处理、芯片设计
科技3 阅读
共找到 195 篇相关文章
2026年4月21日至22日,“奔赴AGI 重塑未来”为主题的中国生成式AI大会(北京站)圆满落幕。大会汇聚了73位来自学界、业界及投资界的嘉宾,通过一场开幕式和多场专题论坛与技术研讨会的形式,全面解析了AI产业的脉络、创新模式以及Token经济等议题,并探讨了在中国市场的机会。会议内容广泛涵盖了大语言模型、多模态模型、世界模型、智能体到AI眼镜等一系列前沿技术和应用,同时也涉及数据处理、芯片设计

▲头图由AI辅助生成近日,美国一家专注于大模型开发的初创公司Anthropic悄然提高了其AI编程工具Claude Code的Token预估费用。据悉,企业用户每天平均需支付从6美元(约合人民币41元)增加到13美元(约合人民币89元),涨幅超过一倍;月度收费区间则由原先的100至200美元(约等于686至1372元人民币)调整为150至250美元(相当于1029至1715元人民币)。此外,该公司

近期有报道显示,Anthropic 在没有事先通知的情况下,将其 Claude Code 的 token 使用费用翻了一番。根据 Claude Code 官方网站最新的说明,“在企业环境中的应用中,每位开发者的每日平均成本大约为 13 美元,而 90% 的用户每天的花费低于 30 美元。每个开发者每月的大致支出范围是 150 至 250 美元(当前汇率约合人民币 1027 到 1712 元)。”在

据业内消息,在第九届数字中国建设峰会上,《全国数据资源调查报告(2025年)》于今日发布。报告指出,我国正加大投入力度,推动人工智能技术的快速发展和广泛应用。数据表明,从年初到年末,全国的日均词元调用量由超过万亿级跃升至100万亿级,增幅显著;全年累计调用量约为21100万亿。据悉,“词元”是“Token”的标准翻译,指的是为了高效处理数据而被拆分出的最小单位,在人工智能大模型中扮演着重要角色,相
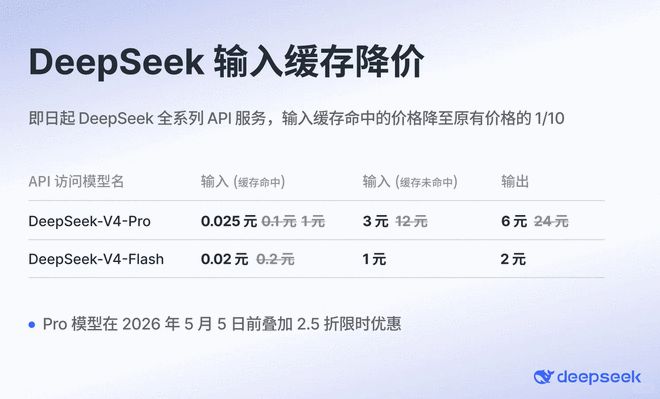
根据DeepSeek官方网站的信息,从即日起,该公司旗下所有API服务的价格将大幅下调,其中输入缓存命中的费用降至原价的十分之一。此外,在2026年5月5日之前,Pro模型还将享受额外的两成五折扣优惠。经过此次降价和限时促销活动后,DeepSeek-V4-Pro型号在缓存命中标的情况下的价格调整为每百万Tokens 0.025元,而DeepSeek-V4-Flash则降至每百万Tokens 0.0


DeepSeek-V4-Pro API 限时优惠至 5 折,直至 5 月 6 日结束据悉,DeepSeek 在其官方网站上更新了相关文档,并宣布旗下最新旗舰级大模型 DeepSeek-V4-Pro 开始提供为期一个月的 2.5 倍折扣促销活动。此次价格调整后,使用 DeepSeek-V4-Pro 的缓存命中输入费用低至每百万 tokens 0.25 元人民币;若为未命中的情况下,则需要支付 3 元

新智元报道Meta公司内部掀起了一场名为「Claudeonomics」的AI使用量竞赛,吸引了约8.5万名员工参与角逐。一名员工在一个星期内消耗了3285亿个token,按照Anthropic公开的价格计算,这相当于花费近200万美元。这场竞赛于4月初被The Information网站首次曝光,当时Meta公司一个月内的总消耗量已经超过了60万亿token。「Claudeonomics」排行榜中

智东西作者 程茜编辑 心缘最近,DeepSeek在其官方网站更新了API文档,并宣布将DeepSeek-V4-Pro的定价下调至原价的四分之一,这一优惠活动将持续到5月5日午夜。根据最新的信息,调整后每百万Tokens的成本(包括缓存命中和未命中的情况)分别为0.25元和3元,输出成本为6元。这次降价举措表明了DeepSeek对市场的重视以及其策略的变化。与国内其他大型模型公司的API价格相比,即

备选标题:消息公布:DeepSeek-V4现已支持“养龙虾”功能!OpenClaw近日正式集成DeepSeek-V4技术。DeepSeek官方宣布,“龙虾”用户也能享受到DeepSeek-V4的大餐了。龙虾养殖的顶级方案来了?OpenClaw与DeepSeek-V4无缝对接。深度探索福利多多!Token价格大幅下降75%,同时引入两款全新模型至OpenClaw平台。最近,OpenClaw发布了20

在今年的这场盛会上,人工智能技术持续飞速发展,年初掀起的一波“养龙虾”热潮引发了token消耗量的激增。各类大模型的密集迭代和基准测试分数的祛魅化表明业界更加关注实际任务完成度,新一轮AI基础设施建设如火如荼地展开。DeepSeek-V4的发布展示了其在大幅降低成本与性能领先方面的持续努力,并且书写了一个打破海外芯片依赖的新篇章。这次盛会中,人工智能产业迎来了前所未有的爆发期,但同时也面临一些挑战
DeepSeek的V4版本发布了,它在长文本处理效率方面取得了重大突破。为了实现极致的长文性能,V4采取了激进的方法,在未来的研究中将会更加全面地探索简化路径的可能性。V4论文详细介绍了其架构和优化措施,包括百万token处理能力的关键改进。这些成果表明DeepSeek在追求高效的同时保持了稳定的进步节奏。论文强调,尽管V4实现了显著的性能提升,但在未来还有进一步精简的空间,并指出几个研究方向如新

星期五中午,本该是盘算周末去哪嗨的黄金时段。但没想到 DeepSeek 突然正式发布并开源了 V4 系列模型预览版。一上来就是王炸级别,而且双双标配百万 token 上下文:参数量达 1.6T 的 DeepSeek-V4-Pro(49B 激活参数)284B 参数的 DeepSeek-V4-Flash(13B 激活参数)即日起可在官网 chat.deepseek.com 或官方 App 体验,API

今日,DeepSeek-V4 的预览版本正式上线,并同步开放了源代码。该模型将上下文处理长度从原先的128K大幅扩展至1M,支持百万字级别的超长文本处理。同时,输出的最大长度可达384Ktokens,还首次引入了KV Cache滑窗和压缩算法以减少Attention计算的成本。国内多家芯片制造商,包括华为昇腾、天数智芯以及寒武纪等公司已经成功支持DeepSeek-V4的新模型,并且它们的产品全面兼

复旦大学、上海创智学院和新加坡国立大学共同提出了HERMES,这是一种无需训练的流式视频理解框架。该框架将KV Cache重构为层次化记忆系统,能够在用户提问时直接利用缓存进行回答而不需要额外检索或计算。实验结果表明,在多个流式及离线视频基准测试中,与均匀采样相比,HERMES在减少68%的视频token情况下仍能达到相似甚至更好的理解性能;特别是在流式数据集上,它带来了11.4%的最大增益,并实
近日,关于DeepSeek-V4的一项深度体验报告发布,该款新推出的开源模型迅速在Hugging Face平台上获得了极高关注,并被视为当前最佳推理和智能体编程性能的代表。在此次评估过程中,我们通过一系列多维度测试来验证这两款模型的实际效果。经过大量数据分析后发现,DeepSeek-V4系列及其Pro版本展示了卓越的技术优势,尤其是在自主规划与执行方面表现出色。测试数据显示,这款新模型已经登上了H

新智元报道DeepSeek V4 引人注目,其参数量达到惊人的1.6万亿,并且在Codeforces竞赛中排名人类选手第二十三位,KV缓存仅前代的十分之一。在同一周内,Kimi K2.6也宣布开源,支持数百万token的上下文和300个子Agent协同工作,模型参数量更是达到了2.6万亿。两家公司在中国AI领域中的地位显赫,它们的技术进步与发布时间高度契合,似乎有意为之。回顾过去一年半的时间线,D

据报道,OpenAI最近推出了新一代的大语言模型GPT-5.5。该公司声称这是迄今为止最为智能且易于使用的版本。OpenAI的联合创始人兼总裁格雷格·布罗克曼表示:“与之前的GPT-5.4相比,新推出的GPT-5.5在运算速度上有了显著提升,并且更加精准地处理逻辑问题。此外,它还减少了词元(Token)的使用量。”他强调了让企业和个人都能享受最新人工智能技术的重要性。GPT-5.5的应用范围十分广

最近,一个名为Elephant的神秘模型终于揭开了其面纱。不久前,OpenRouters在其官方平台上提及了一个尚未公开的模型——Elephant Alpha,并对其作出了如下评价:事情是这样的。尽管只有100B大小,在同类模型中却表现出色,而且非常节省Token资源。这一消息立即引发了网友们的热议与猜测,纷纷探讨这个神秘模型可能来自哪家公司。然而,这次的讨论有一个共同点:大家普遍认为Elepha
