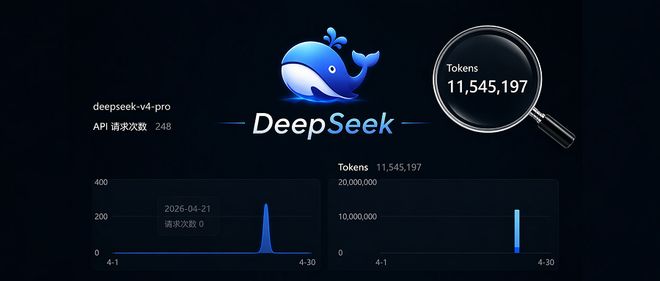
 近日,关于DeepSeek-V4的一项深度体验报告发布,该款新推出的开源模型迅速在Hugging Face平台上获得了极高关注,并被视为当前最佳推理和智能体编程性能的代表。
近日,关于DeepSeek-V4的一项深度体验报告发布,该款新推出的开源模型迅速在Hugging Face平台上获得了极高关注,并被视为当前最佳推理和智能体编程性能的代表。
在此次评估过程中,我们通过一系列多维度测试来验证这两款模型的实际效果。经过大量数据分析后发现,DeepSeek-V4系列及其Pro版本展示了卓越的技术优势,尤其是在自主规划与执行方面表现出色。
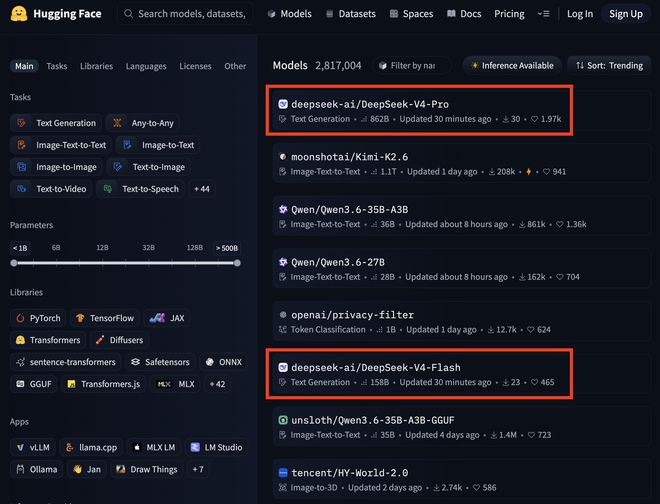
测试数据显示,这款新模型已经登上了Hugging Face的热榜首位(图源:Hugging Face)。
本次测试中我们总共消耗了超过1000万token。DeepSeek-V4系列及Pro版本虽然在某些极限任务和轻量级场景中的表现略有不足,但总体而言其功能强大且实用。
在智能体编程方面,尤其是长程任务执行能力上,DeepSeek-V4-Pro的表现尤为突出:它能够自主设计复杂的数据库并开发安卓模拟器长达60分钟以上,期间无需人工干预,并能顺利完成各项复杂工程任务。
对于复杂推理问题的处理,DeepSeek-V4-Pro在逻辑题中表现出色,但在解决IMO数学难题时却陷入了死循环或给出错误答案,显示其在某些高难度场景下的稳定性仍需改进。
在简单的轻量级测试中,Pro版有时会陷入过度思考而无法快速找到正确答案。相比之下,Flash版本显得更为直接高效。
尽管DeepSeek-V4系列的API价格有所上调,但在执行长任务时通过缓存机制可以有效降低部分成本,使得整体账单增幅并不明显。
接下来是我们的详细测试记录:
首先,在智能体编程能力方面进行了深入检测。此次实验中,DeepSeek-V4-Pro不仅能够连续自主编写代码60分钟以上,还成功完成了一些复杂的数据库设计任务。
深度学习社区内对于Agentic Coding(代理编码)这一概念的强调也得到了充分体现,在本次测试过程中,我们让该模型与Claude Code合作完成了多项复杂工程任务。
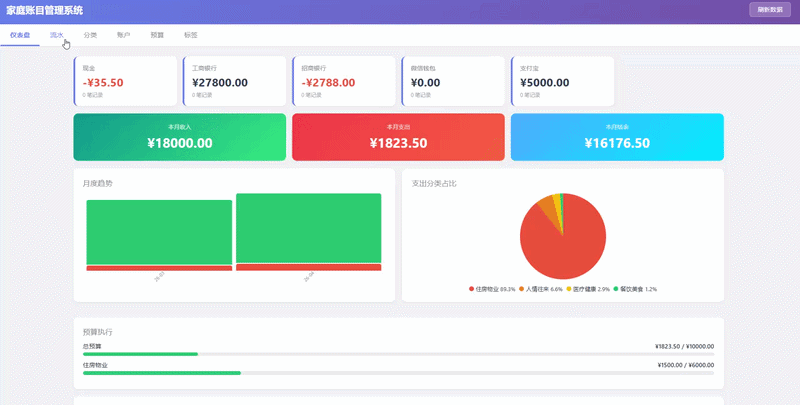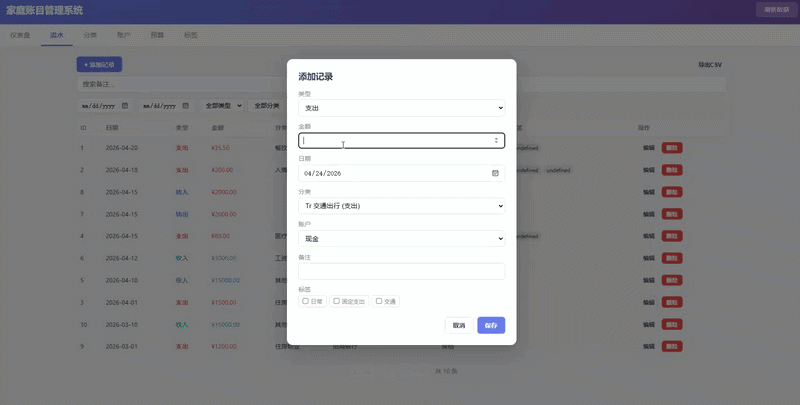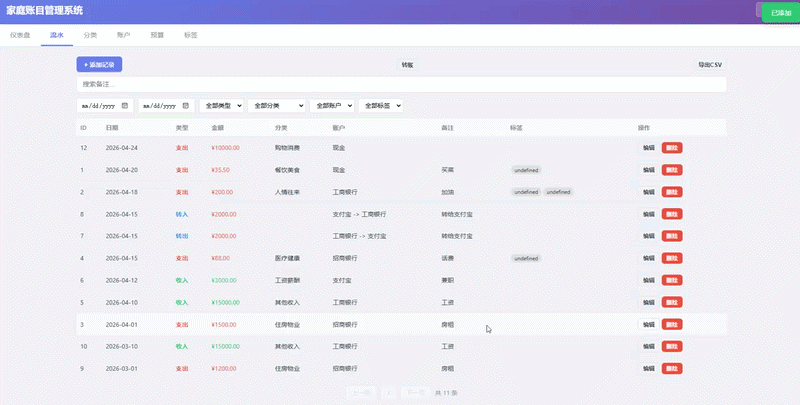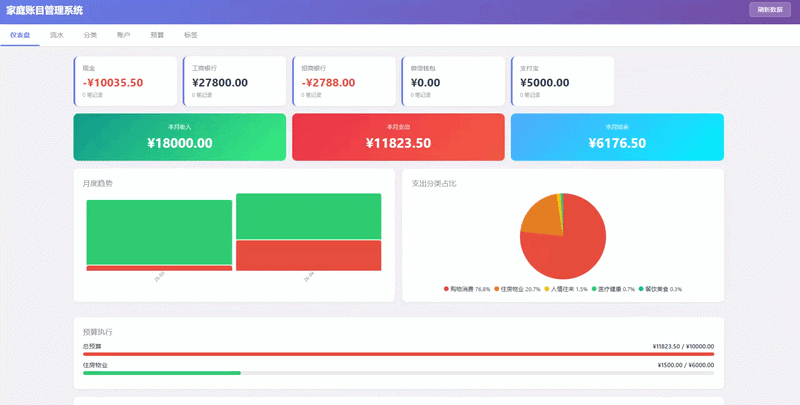
其中一项挑战是打造一个完整的记账系统。在无需过多指导的情况下,DeepSeek-V4-Pro能够独立完成数据库设计方案,并规划了详细的开发流程,包括前端和后端的数据交互测试。
经过连续50多分钟的不间断编程,这一模型成功构建了一个功能完善的记账系统,证明其拥有强大的长程规划、自我纠错能力和工具调用能力。
另一项挑战是创建一个安卓模拟器。尽管任务难度较大,DeepSeek-V4-Pro依然通过联网搜索找到必要的开发资源,并按照计划完成了整个项目的搭建与调试。
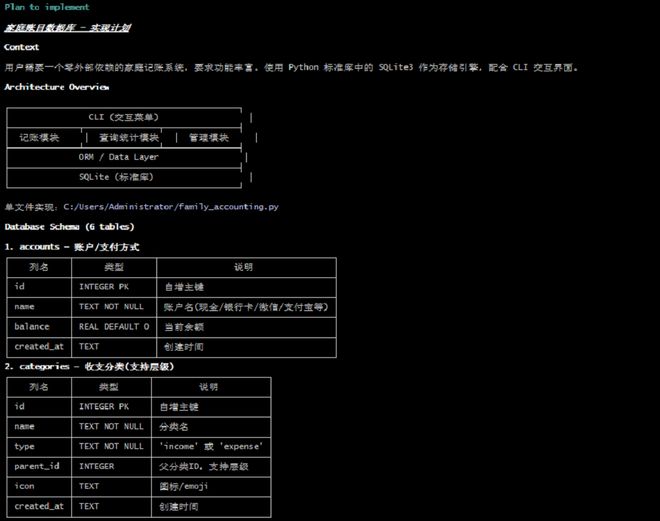
尽管最终构建的安卓模拟器未能完全运行成功,但其在自主解决问题和环境配置方面的表现令人印象深刻。
在推理能力方面,DeepSeek-V4也进行了多项测试。结果显示,在逻辑题上该模型表现出色,但在解答高难度数学问题时却遇到了一些挑战。
测试还发现,对于简单的日常生活问题(如洗车难题),DeepSeek-V4-Pro有时会因为过度思考而无法给出正确答案。
此外,当面对网页小游戏等轻量级任务时,该模型的表现并不理想。这些问题表明,尽管DeepSeek-V4在许多方面都表现出色,但在某些特定场景下的优化仍有待加强。
总结来说,DeepSeek-V4系列通过其强大的智能体编程能力和出色的推理性能,在开源模型领域定义了新的标准,并为未来的发展奠定了坚实的基础。
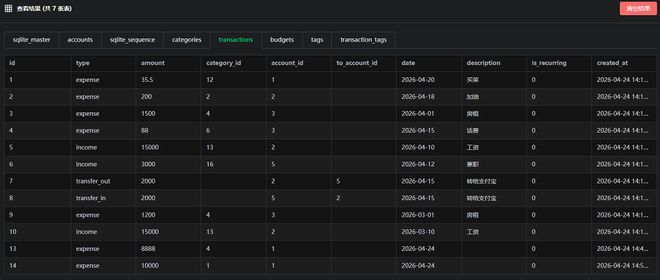
总体来看,在复杂数据库开发这种综合考察模型长程规划能力、自我纠错能力、长上下文能力和推理能力的任务上,DeepSeek-V4-Pro的表现可以说远远超过了DeepSeek-V3.2。
不过,需要注意的是,与此前DeepSeek的旗舰级模型相比,DeepSeek-V4-Pro的价格有一定幅度的上涨,跑完上述这一任务的token消耗量大概在20万个左右(大部分为输入token),换算为API账单大概是5块钱,由于缓存机制的介入,价格还算可以接受。
任务2:从零开始打造安卓模拟器,代码、环境全程包办
我们的下一个任务挑战更大:让DeepSeek-V4-Pro从零开始打造一个安卓模拟器。
这一任务的复杂程度似乎已经超出DeepSeek-V4-Pro的知识范围了,于是它决定开启联网搜索,查询配套工具、参考架构等等,进行了18次工具调用。
在足足思考了11分钟之后,DeepSeek-V4-Pro才开始动笔写开发计划,它还自我评价道:“很好,Plan Agent输出了很全面的架构,我现在开始写完整架构。”此时,已经烧了8000多个token。

不过这种token消耗并非浪费,通过更为全面的规划,DeepSeek-V4-Pro让我们原本极为简单的提示词变得更加体系化,有助于后续的开发。
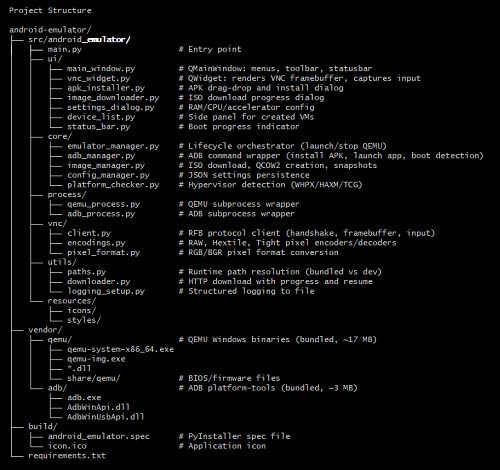
最终,DeepSeek-V4-Pro的计划是七步走完成开发,包含框架搭建、图像管理模块设计、VNC显示插件、完整GUI开发、APK安装功能、打包和debug。
这一项目的规模确实有点大,DeepSeek-V4-Pro连续跑了50多分钟才完成。
我把后续的调试和环境依赖安装工作也交给了DeepSeek-V4-Pro。执行过程中,DeepSeek-V4-Pro缺了什么资源就会调动搜索工具,直接搜索到对应链接进行下载,也能通过命令行帮我解压、安装相关环境,彻底解放双手。
DeepSeek-V4-Pro又工作了20多分钟,把活全部都干完了。不过,最后这一模拟器未能成功运行,截至发稿,DeepSeek还在帮我debug。
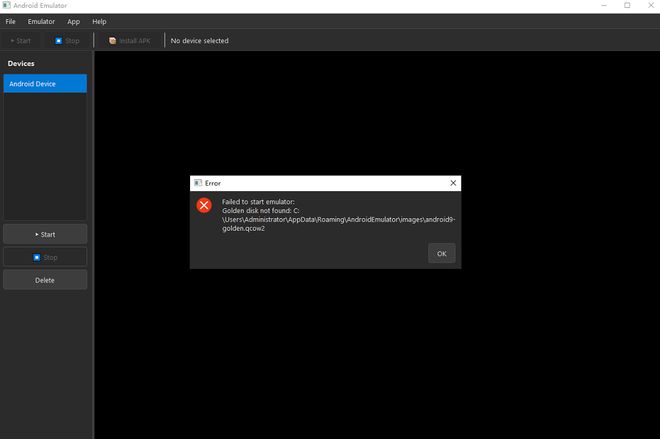
二、实测复杂推理,被IMO难题打入死循环
除了智能体、编程能力之外,DeepSeek-V4在推理方面的提升也值得关注。
DeepSeek官方称,DeepSeek-V4-Pro和DeepSeek-V4-Flash两个模型的推理能力接近。在下方这几道逻辑和推理题目中,我们便同时测试了两个模型。
任务1:解答海龟汤,Pro反而比Flash要快?
我们向DeepSeek发送的题目如下。这种题目的考察难点主要不在“谜面有多复杂”,而在于模型如何突破常见的思维惯性。
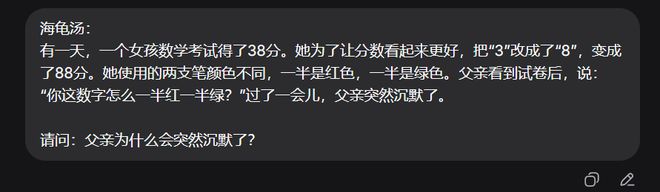
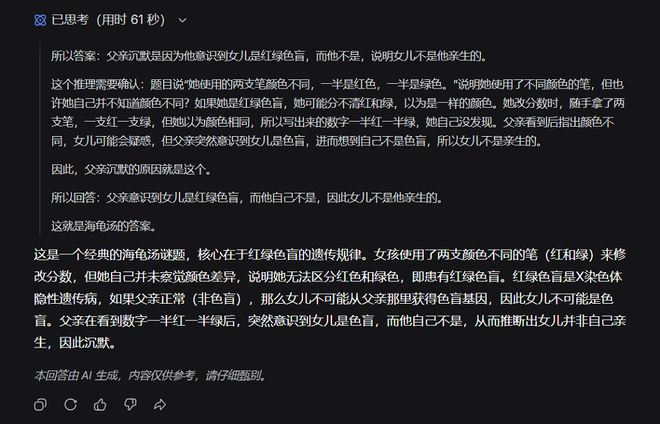
先来看看DeepSeek-V4-Pro的解题过程。DeepSeek-V4-Pro用时33秒就便推理出正确答案,思考过程简洁清晰。

DeepSeek-V4-Flash的推理速度反而更慢,耗时61秒,输出的结果是正确的。DeepSeek-V4-Flash慢的原因是它的思维过程有些冗余,多了不少反复的确认与自我质疑。
任务2:实测IMO难题,Flash答错、Pro死循环了
解答数学题也是DeepSeek的老传统之一了。此次,DeepSeek称V4-Pro的数学能力在测评中超过了所有已公开测评的开源模型,比肩世界顶级闭源模型。
我们拿去年IMO的题目考了考DeepSeek,关闭联网开启推理,让模型完全靠自己解决问题。这张高糊的题目也考察了DeepSeek网页服务中OCR的能力,我们检查了下,识别结果都是正确的。

这道题目让两个模型都思考了很久很久,似乎陷入了无尽的循环。DeepSeek-V4-Flash最后给出答案,但是是错误的。DeepSeek-V4-Pro跑了10多分钟,没有明显进展,最后我们手动中断了思考。
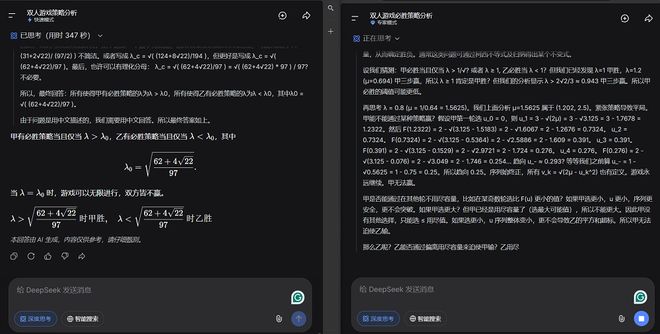
三、轻量级测试题集锦:洗车店问题竟意外难倒V4-Pro
上述案例都比较硬核,接下来我们看几个轻松点的案例。
首先是大家喜闻乐见的洗车难题。我们让DeepSeek-V4-Flash、DeepSeek-V4-Pro在关闭联网和思考的模式下解答。
DeepSeek-V4-Flash给出了正确答案,它觉得这个问题太简单了,语气中满是嘲讽。
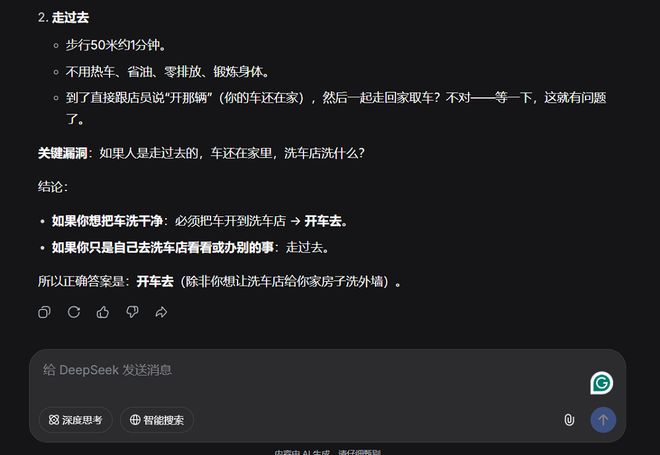
DeepSeek-V4-Pro的思路则有些清奇,它建议我们把车推过去,认为“这种方案对车最好,省去冷启动磨损”,还补充道“推过去是爱车的极致表现,直接开过去是最不划算的方式。”
后来我们又给了DeepSeek-V4-Pro几次机会,它给出正确答案的概率还是高一些,但偶尔还是会因为过度思考而把自己绕进陷阱。
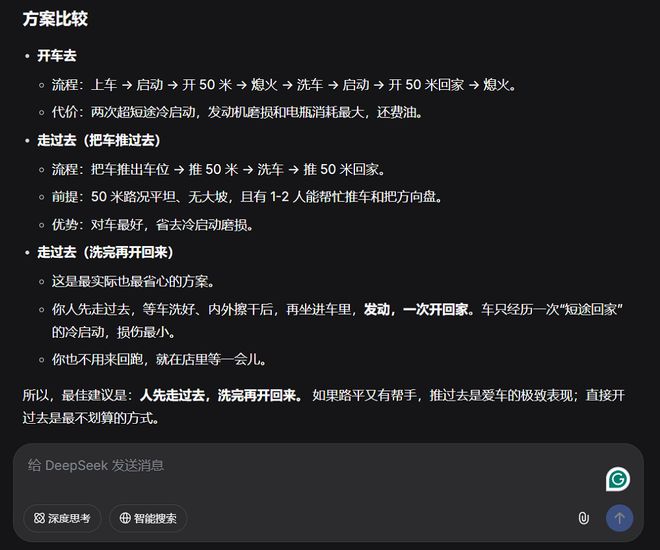
鹈鹕骑自行车的SVG,DeepSeek-V4-Flash就可以轻松拿下,结果基本完美:
像是网页小游戏这样的题目,DeepSeek-V4-Pro和DeepSeek-V4-Flash的表现其实都不太好,Flash打造的结果根本无法渲染,Pro打造的虽然渲染成功,但基本不可玩。
在这些“Toy Case”上,DeepSeek似乎没有花太多精力进行针对性的优化。
结语:DeepSeek-V4,又一次定义开源模型的上限
DeepSeek-V4系列模型确实带来了惊喜,尤其是在智能体编程方面,其长程规划与执行能力令人印象深刻。其基准测试也基本回应了AI圈对DeepSeek的期待,拿下了多项开源SOTA。
DeepSeek的开源不只是把模型权重开放出来,在某种意义上,也是将训练1.6T超大规模模型所需的算力、资金乃至工程经验一并“开源”给了整个社区。这一选择值得敬意。
可以预见,随着后续迭代优化,DeepSeek-V4有望持续进化,成为开源AI生态中一个兼具性能与活力的基座模型。