最近,一个名为Elephant的神秘模型终于揭开了其面纱。
不久前,OpenRouters在其官方平台上提及了一个尚未公开的模型——Elephant Alpha,并对其作出了如下评价:
事情是这样的。
尽管只有100B大小,在同类模型中却表现出色,而且非常节省Token资源。
这一消息立即引发了网友们的热议与猜测,纷纷探讨这个神秘模型可能来自哪家公司。

然而,这次的讨论有一个共同点:大家普遍认为Elephant Alpha可能是中国的大模型之一。
根据量子位独家获得的消息,事实证明网友们猜对了一半——
这个“大象”确实来自中国;不过,它并非网友猜测中的MiniMax、Kimi或DeepSeek等公司所开发的。
其实,“大象”的研发团队是蚂蚁Inclusion AI小组。
有趣的是,尽管名字叫“大象”,但它其实非常小巧轻便——仅有100B大小,并具有256K上下文窗口和32K输出能力。
经过体验后发现,这款模型给人的感觉就像是国产版的Grok 4 Fast,具备出色的实用性。
接下来,我们将对其进行全面测试。
实测表明,“大象”在代码生成与修复方面表现出色,非常节省Token资源。
我们选择OpenRouters提供的网页端进行实测,并选择了日常工作中的高频任务来验证“大象”的性能。

第一项测试:修复Bug
对于程序员来说,AI写代码早已不是新鲜事了。但当前面临的问题是,一些AI在生成大量代码时可能会出错,需要反复修改,这不仅效率低下还浪费Token资源。
因此,在此次实测中,“大象”被赋予了一个实际任务——使用HTML和原生JS编写一个包含姓名、手机号码(符合中国大陆格式)以及电子邮件的活动报名页面,并进行表单验证。
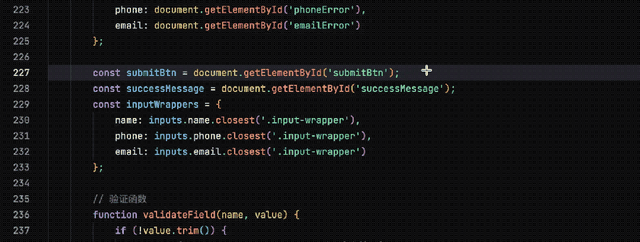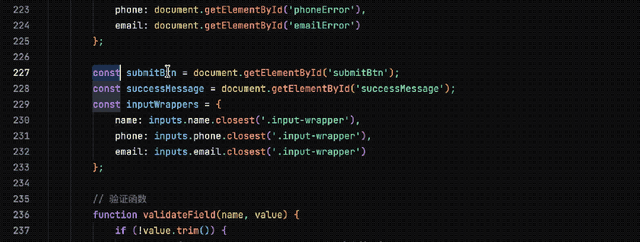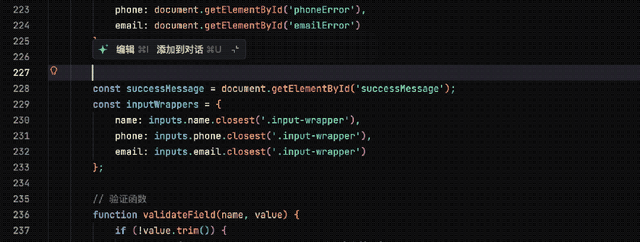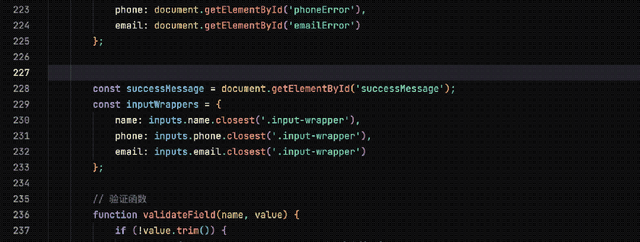
经过短暂思考后,它迅速生成了所需的代码。将这些代码保存为.html文件并运行,可以正常工作。
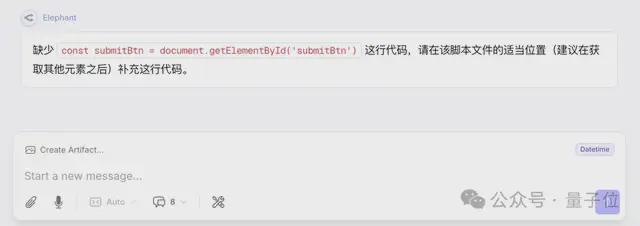
接下来,在故意删除提交按钮变量之后,“大象”依旧能准确识别问题并提供简洁的修复方案,而不会产生额外的Token消耗。
第二项测试:会议纪要整理
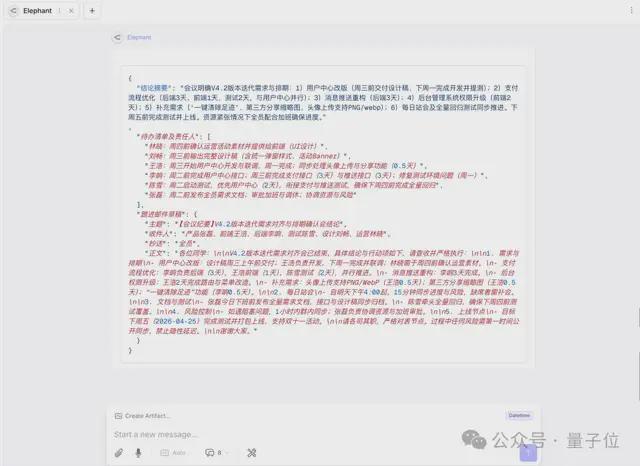
除了程序员之外,几乎所有职场人士都需要处理会议记录。这次我们准备了一份大约3000字、包含大量口语化表述和无关信息的会议纪要文件。
我们要求“大象”忽略寒暄内容,并以特定格式提取关键点并生成跟进邮件草稿。
“大象”的处理结果简洁明了,完全符合要求。相比之下,Gemini-2.5-Flash-Lite虽然也做到了,但输出的内容更长且消耗更多Token资源。

△原速度展示
第三项测试:Agent任务执行
最后一项实测是评估“大象”在执行复杂任务时的表现。

我们让“大象”完成一个涉及读取CSV文件、计算数据并生成简短分析结论的任务,同时还需进行自检以确保准确性。整个过程只用了10秒思考时间加上2秒输出时间。
这说明这款仅有100B大小的模型确实具备快速响应和精确处理的能力。
正如权威评测网站AI BENCHY所展示的数据,“大象”在Token效率、指令遵循及响应速度方面均表现出色,证明了其高性价比的特点。
虽然“大象”表现卓越,但它并非完美无缺。例如,在执行需要长期规划的任务时可能会遇到困难。
此外,对于最新的技术信息,“大象”有时可能无法完全掌握并生成正确的代码或建议。
因此,使用“大象”的时候需要注意,Prompt应当详细具体以确保输出质量。
在AI领域中,“快、好、省”的小型模型变得越来越重要。随着行业的发展,越来越多的公司开始注重模型的实际应用效果而不是仅仅追求规模和成本投入。
事实上,在这个时间节点发布这样一款强调效率比的小型模型本身就是一种趋势信号。
过去几年间,大家都在竞争谁的模型更大、训练成本更高以及在各种榜单上的排名更靠前。然而现在,行业开始意识到简化流程和提高效率的重要性了。
随着Token浪费问题日益受到关注,《财经》杂志报道指出全球企业级AI应用中有大约一半的Token被浪费掉。
近来,OpenAI发布了两款专门针对需要快速响应且对延迟敏感任务的小型模型——GPT-5.4 mini和nano。它们不仅拥有优秀的推理能力还具有很高的吞吐量和较低的成本优势。

谷歌则通过开源小模型Gemma 4打入低端市场,这款模型的参数规模仅为同级大模型的约二十分之一,在降低成本的同时保持了强大的推理力。
对于预算有限或追求极致性价比的企业来说,“大象”这样的轻量级模型能够无缝承接日常工作中高频且刚需的任务,成为推动AI从玩具向生产力工具转型的重要力量。
在Token消耗巨大的长文本办公场景中,响应迅速、简洁高效的“大象”,正在帮助AI实现这一转变,并确立其作为高效生产工具的地位。
“快”、“准”和“省”这三个看似简单的字眼,正成为衡量现代AI应用性能的重要标准。
或许单看「大象」的结果不够明显,我们为此特意拿了Gemini-2.5-Flash-Lite做了下对比:
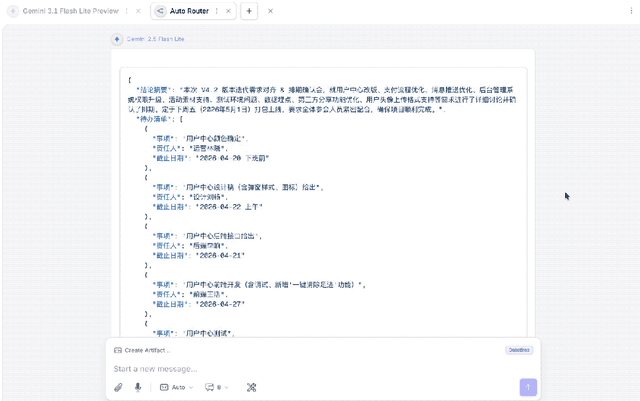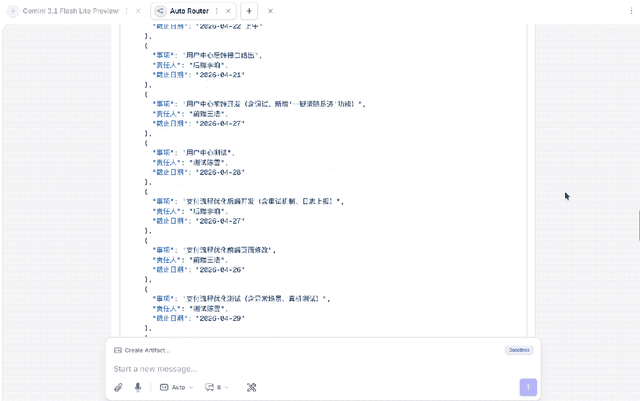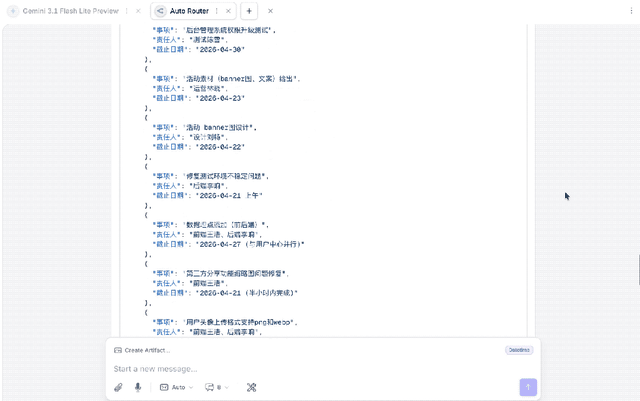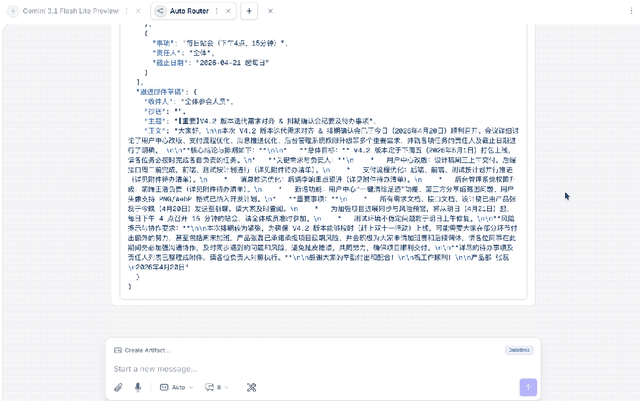
正所谓没有对比就没有伤害。
Gemini-2.5-Flash-Lite虽然也是实现了Prompt里的结构,但很明显一点就是,太长,也就意味着更多Token的消耗。
所以「大象」在会议整理任务上,Win Again。
实测3:Agent任务,也是够快
最后的实测,我们来上一道硬菜——大火的Agent。
我们用「大象」来模拟一个轻量级的Agent Loop:
读取一份包含四个月度数据的CSV销售报表 → 计算季度同比(需要调用数学逻辑) → 写一段简练的分析结论 → 自检数字是否准确。

从内容上来看,「大象」先是对数据做了快速分析和推理,并给出了初步结论;而后又完成了自检的工作,最终输出最终结论。
但更重要的还是速度:只思考了10秒钟、输出2秒钟。
由此可见,这个只有100B大小的「大象」,是真的做到了快、准、省。
而这一点,同样体现在权威榜单的评测中。
作为开发者圈层公认的模型测谎仪,AI BENCHY不看厂商宣传跑分,只聚焦指令遵循、响应速度、Token效率三大实战指标。
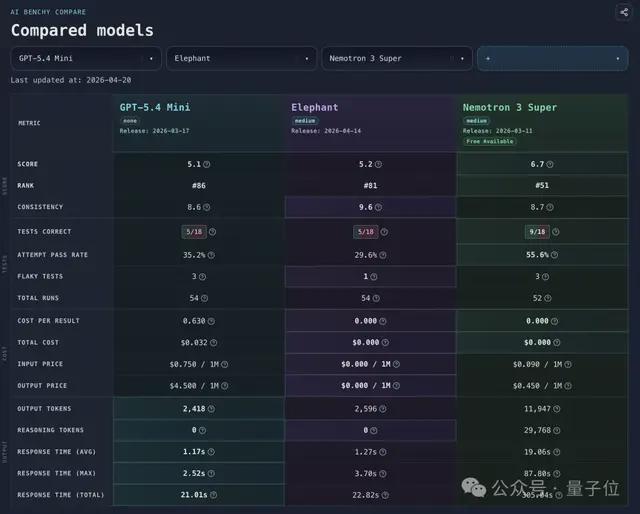
从AI BENCHY给出的结果来看,「大象」输出Token维持在了2500左右,说明每一分钱的API算力,都用在了刀刃上。
平均响应时间方面,「大象」平均时延被压制在了1秒左右,而其它选手则均是10-30秒的水平。
并且在最重要的输出质量上,它的一致性分数达到了9.6分(满分10分)!
因此,不论是从实测的体验,亦或是权威榜单的评测来看,「大象」已然是可以胜任日常绝大多数的工作了。
但也有不擅长的事
正所谓人无完人、模无完模。
「大象」毕竟走的是一条快、准、省的路线,所以它定然是在某些领域里有所妥协。
在我们的实测中,也发现了「大象」一些不太擅长的工作。
例如复杂长链规划,就是其中之一:
帮我主导一个出海东南亚市场的战略项目。请从市场调研开始,接着做竞品分析,然后给出渠道策略建议,最后帮我排一个半年的执行甘特图。
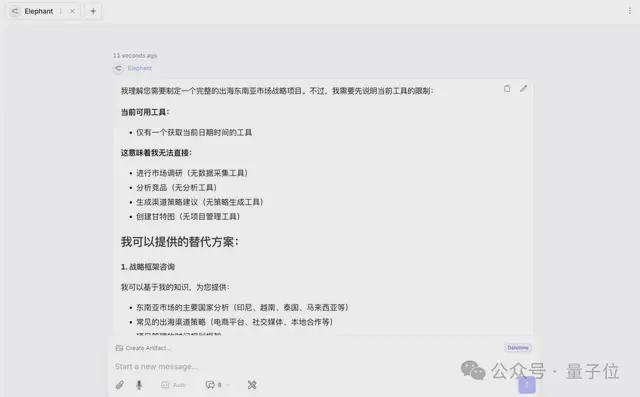
对于这个任务,「大象」直言无法执行。
因为它没有数据采集工具、没有分析工具、没有策略生成工具,也没有项目管理工具。
所以对于这类任务,我们不妨用大模型规划 + 「大象」执行的方式来操作。
再如,对于非常非常新的知识,「大象」也可能会心有余而力不足。
以及要求生成React 18新特性或刚更新的SDK代码时,「大象」可能会基于旧知识产生API幻觉。
所以如果你有这方面的需求,可以在Prompt中注入最新文档来解决。
最后,Prompt过于模糊,也会影响输出的质量。
例如跟「大象」说:
帮我写个好看的网页。

因此,在用「大象」的时候,我们还需切记,Prompt一定要细致、要有足够的约束力。
Agent 时代,“快、好、省”的小模型同样重要
其实,在这个时间节点发布这样一款主打智效比的模型,本身就是一种信号。
过去几年时间里,AI圈似乎都在比拼谁的模型更大、谁的训练成本更贵、谁在榜单上刷的分更高。
但行业走到今天,做加法的人太多了,需要有人站出来做减法。
因为Token浪费,已然成了行业高度重视的关键内容之一。
《财经》报道,全球企业级AI应用中,约有50%的Token正在被浪费。AI应用从对话转向执行后,Agent在复杂多轮任务中会不断累积历史文件、对话记录,大量冗余信息导致Token消耗指数级增长。
每一块钱都要花出响动,这是工程落地的铁律。而践行这条路线的,远不止百灵。
就在前不久,OpenAI连续发布了GPT-5.4 mini和GPT-5.4 nano两款小型模型,专为高频且对延迟敏感的任务设计。它们在保持了GPT-5系列优秀推理基因的前提下,实现了极高的吞吐量、极低的延迟和极具竞争力的性价比。
谷歌则通过开源小模型Gemma 4,以低成本、高推理力打入低端AI市场。Gemma 4的参数规模仅为同智力水平大模型的约二十分之一,过去需要花费上千万GPU成本才能跑动的模型,现在大概一张高阶显卡就能跑得动,成本差距将近十倍。
尤其是对于预算有限、算力资源匮乏、追求极致投入产出比的中小企业而言,无需为冗余Token支付高额算力成本,无需采购昂贵硬件部署大模型,轻量化的「大象」就能无缝承接代码开发、文档处理、数据复盘、轻量Agent执行等高频刚需工作。
在动辄消耗几十万Token的长文本办公场景中,响应压制在1秒内、少说废话的高效模型,正在成为AI从玩具跨越到生产力工具的坚实底座。
快、准、省,这三个看似接地气的字眼,正在成为AI高效上岗的标准。