
研究团队成员包括:Yuxin Chen,现为伊利诺伊大学厄巴纳-香槟分校硕士一年级学生;Chumeng Liang 和 Hangke Sui 均为该校博士生;Ge Liu 则是该校计算机科学系的助理教授。Liu 实验室专注于扩散及流模型领域,并已发表了包括 Riemannian Consistency Model (RCM)、Statistical Flow Matching 等在内的多项成果,其中包括此次介绍的 LangFlow。

- 本次研究的主要论文标题为《LangFlow: Continuous Diffusion Matches Discrete in Language Modeling》
- 相关论文可以在 arxiv 上查阅(https://arxiv.org/abs/2604.11748)
- Github 地址:https://github.com/nealchen2003/LangFlow
- Huggingface 页面:https://huggingface.co/papers/2604.11748
“图像和视频生成中连续扩散模型的统治地位,为何在文本领域迟迟无法突破?”
当前主流的扩散语言模型(DLM)陷入了一种困境,即越接近自回归架构性能越好。然而,在追求这种效果时,研究者们转向了离散扩散,这反而导致了并行解码难题,并限制了它们原本应有的低延迟与多模态融合能力。
面对这一挑战,UIUC 的 Ge Liu 教授团队发布了一篇新论文《LangFlow: Continuous Flow Matching for Large Language Models》,重新回到传统的连续扩散架构。研究指出,文本处理中连续扩散的失败并非其固有缺陷,而是受限于训练和评估策略。通过系统优化,LangFlow 成功地在标准基准测试上实现了与离散扩散模型相当的表现。
该研究成果不仅打破了文字生成中的离散壁垒,还证明了保留扩散模型原生特性的连续架构同样具有竞争力,为探索低延迟、高可控的多模态统一架构提供了一条新的路径。
语言模型的发展方向
目前的大语言模型(如 ChatGPT 和 DeepSeek)主要基于自回归架构,即预测下一个词元。虽然这种架构已经取得了很大成功,但仍存在一些固有的限制:
1) 推理延迟:每次只能预测一个词元。
因此,总的推理时间等于输出的词元数乘以单步延迟。
对于自回归模型而言,单步延迟主要由从缓存读取之前的内容决定。因此,每一步只计算一个新词元的做法效率低下。
2) 控制性:提示词与其它信息处于同等地位,导致指令失效问题。
3) 模态局限性:自回归架构主要用于处理离散模态(如文本),而对于图像、视频等连续模态则需要额外的生成头来支持,不利于架构统一。
扩散语言模型简史
近年来有一种观点认为,扩散语言模型越接近自回归性能就越好。然而,传统的连续扩散被认为存在天然劣势;但这一观念正在被逐渐挑战和打破。
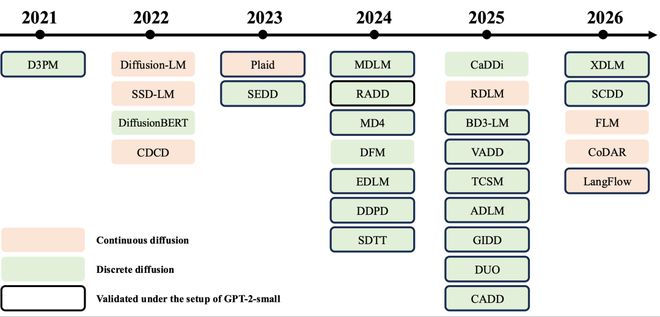
随着 Stable Diffusion 等生成模型的成功应用,扩散在图像和视频领域的统治地位已经确立。2022-2023 年间,人们开始尝试将这种技术应用于文本处理,期望解决上述三个问题:
1) 推理延迟:通过蒸馏为一步生成模型(如 Consistency Model),读取一次缓存就能输出多个词元,大大降低了推理延迟。
2) 控制性:扩散模型具备成熟的引导技术(Classifier Guidance 和 Classifier-Free Guidance 筹)可以强化指令跟随的效果。
3) 多模态支持:由于扩散在处理连续数据方面已经很成熟,将其应用于离散模态可以实现架构统一,并不会丢失任何信息。
尽管这一目标很有吸引力,但早期实验结果并不理想。随着模型规模的增长,性能差距进一步扩大。例如,参数量为 1B 的 Plaid 模型的性能甚至不及具有 100M 参数的自回归 Transformer。此外,一些扩散模型在没有条件输入的情况下生成连贯句子也十分困难。
面对传统扩散模型在语言任务中的局限性,研究社区开始转向一种“离散 Diffusion”,即从初始状态(全噪声)出发逐步减少噪声量,并引入了 Masked Diffusion Model(MDLM)。然而,这种方法同样遇到了并行解码的难题。
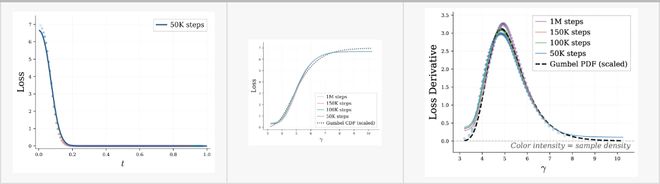
优化扩散模型的关键在于噪声调度策略。不同于图像处理中的均匀分布,研究团队发现 DLM 需要更加重视高噪声区域以获取有效信息。
在以往的工作中采用的标准噪声调度器并不适用于这种需求。
因此,该团队提出了一种新的调度方法,让噪声与信息增量相匹配。
理论上,信息量遵循 Gumbel 分布这一特点被用于设计更好的调度策略。
为了更精准地评估连续扩散模型的能力,研究引入了更为准确的测试标准。

自条件机制是关键部分之一,关闭它将对连续 DLM 不公平。
连续扩散模型的回归
此外,该团队还为 ODE 生成路径设计了一个新的 NLL 上界计算方法。
新的方法由三部分组成:从噪声中抽取轨迹起点的 NLL;ODE 对概率密度的影响;以及还原 token 的 NLL。最后一项是所有常数相互抵消后的总和。
下文说明具体做法。
更有效的训练:
刻画连续扩散的信息熵
这一新上界为连续 DLM 提供了更为可靠的 PPL 评估依据。
在语言建模方面,LangFlow 不仅在 LM1B 和 OWT 上的表现与离散扩散模型相当,在零样本迁移测试中也超过了 AR 基线。
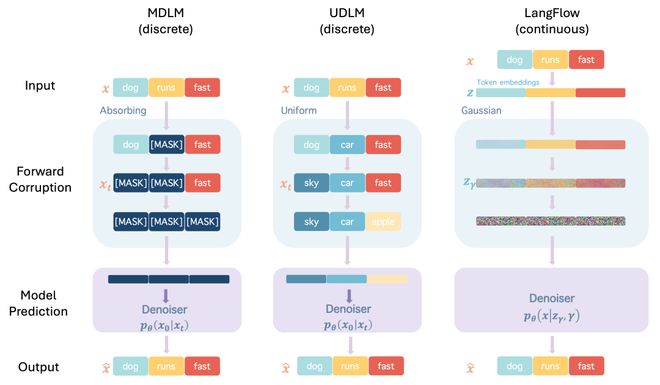




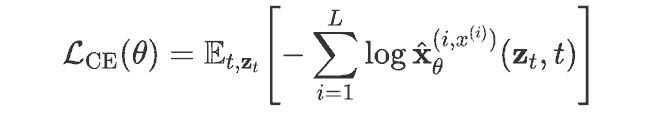


模型采用双向 DiT 架构,参数量为 130M,并经过了 1M 步的训练。
在 LM1B 数据集上,LangFlow 的生成 PPL 达到 91.8,优于所有离散 DLM(Duo 最高为 97.6)。测试集上的表现也超过了 MDLM。在 OWT 测试中,差异仅为一个百分点左右。
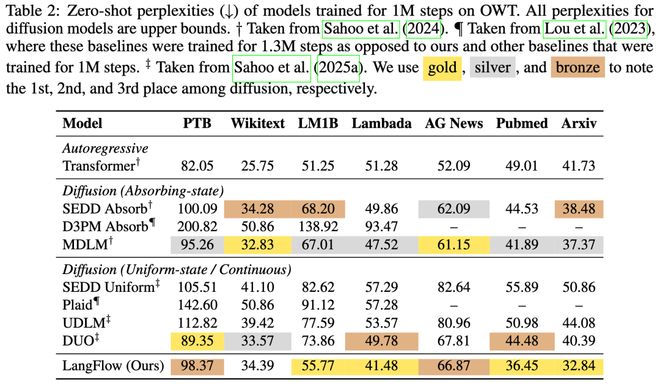
在七个零样本迁移任务中,LangFlow 超过了 AR 基线三次,并且在 PubMed 和 Arxiv 等领域表现出色。


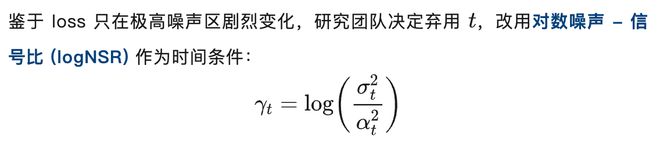

总结来看,LangFlow 证明了连续 DLM 具备与离散模型竞争的能力。未来语言模型的发展趋势将趋向于多种架构的协同合作,而不是单一范式的统治。





完整保留扩散模型核心特性的 LangFlow 不仅为后续研究奠定了基础,还指明了一条通往下一代低延迟、高可控性及多模态融合 AI 基础设施的道路。

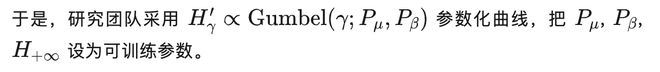


更精准的测试:还原连续扩散的实力
关键指标解释
根据以往的 DLM 工作,该研究沿用以下两项指标(都是越低越好):


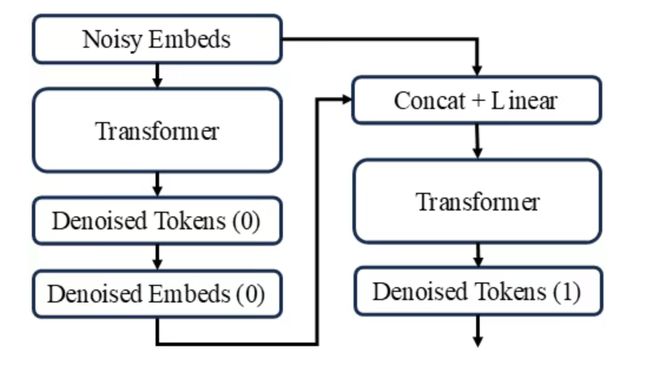
Self-Conditioning
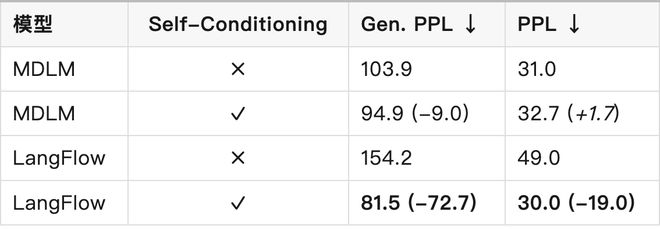
研究团队通过对比实验指出:关闭 Self-Conditioning 的对比对连续 DLM 是不公平的。

ODE 生成的 PPL 估计
研究团队还注意到:之前的工作的变分上界不适用于 LangFlow 所用的 ODE 生成。
准确的 PPL 度量是公平比较的前提。AR 逐词元计算似然;离散扩散用变分推导一个上界。在本研究中,团队为 LangFlow 的 ODE 生成路径推导了一个更适配的 NLL 上界,按序列长度平均并取指数后即为 PPL:
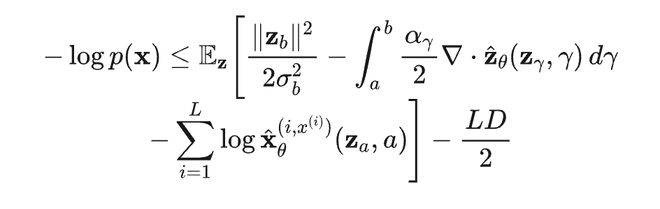
这个上界由三部分构成:第一项是从噪声中抽取轨迹起点的 NLL;第二项是 ODE 对概率密度的压缩或膨胀;第三项是从轨迹终点还原 token 的 NLL。最后的一项,是以上三项中的常数项相互抵消剩下的总和。
这个界完全适配 LangFlow 的 ODE 生成,为连续 DLM 的 PPL 评估提供了更可靠的理论基础。
多项基准全面追平:
语言建模与零样本迁移均进入第一梯队
连续扩散在 LM1B 和 OWT 的 PPL/Gen. PPL 上整体匹敌离散扩散,并取得扩散模型中最强的零样本迁移表现。
研究团队在 LM1B(句子级)和 OpenWebText(OWT,类似 GPT-2 语料)上评估 LangFlow。模型都是 130M 参数的双向 DiT,训练 1M 步。
语言建模
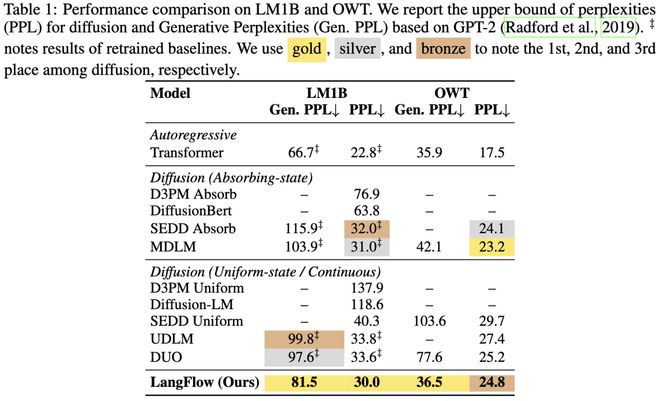
在 LM1B 上,LangFlow 生成 PPL 达 91.8,优于最强离散 DLM(Duo 97.6)6 分以上。测试集 PPL(31.7)超过所有均匀随机噪声的离散 DLM,与 Masked Diffusion 的 SOTA MDLM(31.0)持平。在 OWT 上,LangFlow(24.3)与 MDLM(23.2)差距仅在 1 左右。这是连续 DLM 首次在标准语言建模基准上追平离散 DLM。
零样本迁移
在 7 个 零样本迁移测试中,LangFlow 在 3 个上超过 AR 基线,在 4 个上超过 MDLM。尤其在 Pubmed 和 Arxiv(充满结构化、专业术语)上,LangFlow 相对 AR 优势显著(36.45 vs 49.01,32.84 vs 41.73)。LangFlow 不仅放大了离散扩散对 AR 的相对优势,还在其弱势项目上补齐了短板。
总结:走向多架构协同的下一代语言模型
LangFlow 证明了连续 DLM 完全具备在标准基准上打平离散 DLM 的基础能力。然而,Diffusion 的长期价值并不在于与 AR 进行零和博弈,而在于作为 AR 架构的关键补充。在低延迟解码、细粒度指令控制以及原生多模态融合等 AR 存在固有局限的领域,连续 Diffusion 展现出了不可替代的天然优势。
未来的语言模型发展趋势正指向多种架构优势互补的组合,而非单一范式的垄断。与其将 Diffusion 强行 “改造” 成 AR 的离散生成模式,不如彻底释放其连续架构的原生潜力。
LangFlow 完整保留了扩散模型的核心特性,不仅为连续 DLM 的后续扩展提供了坚实的基线,更为构建下一代低延迟、高可控、多模态共生的 AI 基础设施确立了重要的底层路线。