
新智元报道
xAI 最新发布的 Grok 4.3 是一次务实的更新,提供更经济、更快捷且实用的功能体验。
这次发布并未引起太大的关注,马斯克也没有为此单独发声,显得更像是一个过渡版本。
它主要通过将模型集成到 API 中,并降低价格来吸引更多开发者和用户。
新增了一些工具功能,使得从旧版 Grok 到新版本的迁移变得更加容易。
与以往宏大的 AGI 计划不同,这次更新显得更加实际且贴近市场需求。
对于普通用户而言,Grok 4.3 的最大改进在于其成本效益和响应速度提升,以及更贴合日常工作的功能优化。
尽管如此,在硬推理、稳定性和可信度方面,它依旧不及 GPT-5.5 和 Claude Opus 4.7。
这个新版本是一款高性价比的模型,但也存在明显的局限性。
用户需要注意的是,Grok 4.3 在哪些情况下可以节省时间和成本,在哪些场景中可能由于判断失误或过度输出而导致问题增加。
它确实变强了
它更像一个注重实用性的助手
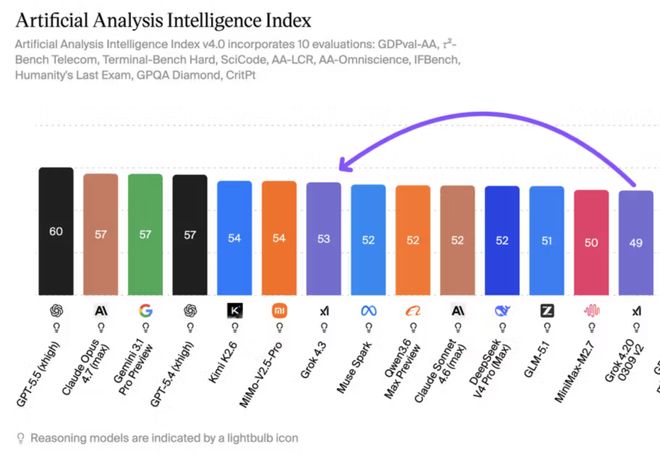
Artificial Analysis 给 Grok 4.3 的智能指数评分为 53 分,比前一版本高出 4 分,并且超过了 Claude Sonnet 4.6 和 Muse Spark。
这样的提升在 xAI 自家的模型系列中已经是非常显著的进步了。
更值得注意的是 Grok 4.3 在代理任务上的表现。
其 GDPval-AA 测试得分达到了 1500 Elo,相比前一版本提升了 321 分。
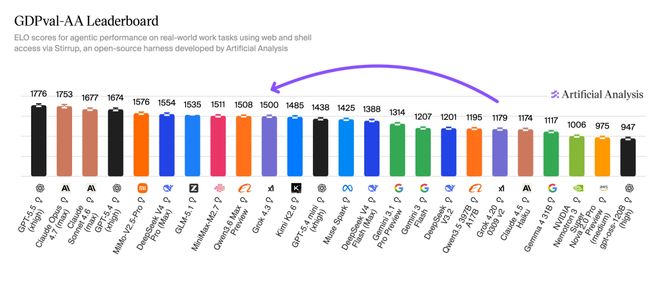
这些测试更贴近实际应用场景,比如文件整理、执行复杂步骤等,对普通用户具有重要意义。
帮助撰写周报、搭建表格或生成演示文稿等功能在新版本中体验更加完善。
Grok 能够创建文档和电子表格,并在一个计算机环境中编写和运行代码。
对于非编程背景的用户来说,这意味着许多原本需要跨多个应用程序的操作现在可以通过简单的指令完成。
这些是消费者真正关心的功能点——它们是否能有效地处理报销单、旅行计划或撰写正式邮件等任务。
新版本在这方面的改进是实实在在的进步。
更便宜
价格竞争力也是这次更新的主要卖点之一
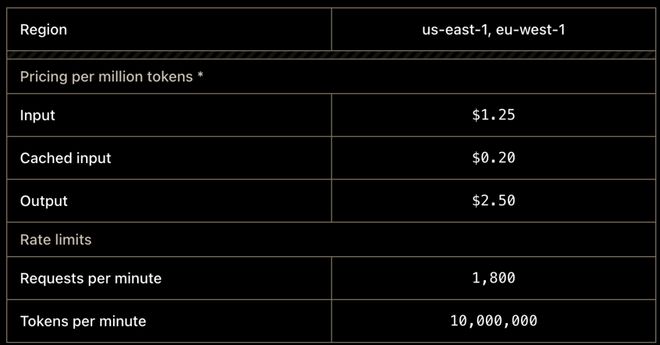
Grok 4.3 的 API 费用大幅下调,每百万输入 Tokens 和输出 Tokens 分别为 1.25 美元和 2.50 美元,分别比前一版本降低了约 40% 和 60%。
这将间接影响到消费者,尽管这种影响可能不那么直接明显。
很多人不会直接调用 API,但他们确实会使用基于这些模型构建的产品和服务。

AI 写作工具、客服机器人和语音助手等背后的成本都是由模型调用支付的。
当底层模型价格下降时,应用厂商可以降低订阅费或者在相同价格下提供更多的功能和更长的任务上下文支持。
除了价格竞争力外,Grok 4.3 还具备较快的速度。
根据 Artificial Analysis 的 xAI 模型页面显示,它是目前最快的模型之一。
对于语音聊天、实时客服等场景来说,缩短等待时间直接影响用户体验。
不过要注意的是,Grok 4.3 在首次输出时会有一个短暂的延迟。
它会在「想一会儿」后迅速完成任务。
这种速度优势在长对话中更为明显,在短对话中用户可能会先感受到停顿。
此外,Grok 4.3 在某些情境下表现出更自然的语气和表达能力。
有人认为它在非正式沟通、语音输入识别等方面比其他模型更加贴近真实交流。
这种特性使得 Grok 对于写消息、口语转写等场景来说非常受欢迎。
它更会说人话
它可能得益于 X 平台上的海量口语化表达数据训练
但这种优势也可能导致继承社交网络中的噪音和偏见。
在高风险行业如医疗、法律等领域,Grok 4.3 的使用需要谨慎对待。
它适合处理一些低风险的辅助性任务,但在涉及最终判断时仍应优先考虑 GPT-5.5 和 Claude Opus 4.7。

Grok 4.3 在 Intelligence Index 上得分为 53 分,而 GPT-5.5 得分是 60 分,Claude Opus 4.7 则为 57 分。
这些分数的差距体现在复杂推理、代码调试等方面的具体性能差异上。
尽管 Grok 4.3 的知识覆盖率有所提升,但它的非幻觉率却有所下降。
即使在给出流畅答案时也可能存在错误的风险。
对于需要高度准确性的场景来说,GPT-5.5 和 Claude Opus 4.7 是更好的选择。
Grok 4.3 提供了一个百万 Token 的上下文窗口,这对长文档和复杂代码库非常有用。
这种功能对于研究、办公和创作等方面而言是一种实用能力。
新版本还增强了工具调用、网页搜索和其他能力的支持。
未来 Grok 可能会成为一个集多种功能于一身的多模态助手,不仅限于文本处理。
不过,更多的功能并不一定意味着更好的用户体验。
消费级 AI 的竞争最终将回归到三个基本点:快速响应、减少错误和简化操作流程。
Grok 4.3 在前两点上取得了明显进步,在准确性方面则还需努力。
正确理解 Grok 4.3 定位的关键在于它是一款高性价比的工作型模型。
对于那些对成本和响应速度敏感,但不追求最高推理能力的产品来说是理想选择。

并非所有用户都需要每次都调用最强的 AI 模型,就像不是每次买菜都得开跑车一样。
在需要深度推理或专业判断的情况下,GPT-5.5 和 Claude Opus 4.7 更为适合。
这次更新表明 xAI 的策略是先提升模型性能再降价促销,并通过提高速度和工具能力扩大应用范围。
虽然没有赢得最强 AI 模型的称号,但有可能在实际使用量上有所突破。
市场并非总是奖励最强大的产品,而是更偏向于那些价格合适、速度快且功能实用的选择。
此次 Grok 4.3 的更新标志着 xAI 向务实的 API 和消费级工具供应商方向迈进了一步。
它确实提供了不错的体验,但还未到足以令 GPT-5.5 和 Claude Opus 4.7 担忧的地步。
但消费者买账的是结果
用户可以期待 Grok 价格更低、速度更快,并促使更多 AI 应用变得更实惠。

同时也要记得,在需要真正聪明和可靠的场景下,Grok 4.3 还只是一个备选项。
对研究、办公和创作来说,这是一种实用能力。
它还支持文本和图像输入,输出文本,并围绕工具调用、网页搜索、X 搜索、代码执行、文件搜索、RAG 等能力加强。
xAI 还推出了 Custom Voices、语音代理、TTS 和 STT 等产品,把 Grok 的边界从文字扩展到语音。
对普通用户来说,未来的 Grok 可能不只是一个聊天框,而是一个能读文件、查网页、写表格、说话、听话的多模态助手。
问题在于,功能多不等于体验好。
消费级 AI 的竞争,最后会回到三个朴素标准:少等、少错、少折腾。
Grok 4.3 在「少等」和「少花钱」上明显前进,在「少错」上还没给出足够强的答案。
Grok 4.3 的准确定位:
性价比模型,不是最强模型
Grok 4.3 最适合的定位,是一款高性价比的工作型模型。
它适合高频内容生成、语气改写、长文本初筛、语音产品、客服场景、批量办公任务、轻量级代理工作流。
它也适合那些对成本敏感、对响应速度敏感、对最强推理没有执念的产品。
很多消费者并不需要每次都调用最强模型,就像不应该只是为了买菜开超跑,除非另有所图。
但如果任务要求深度推理、严谨事实核查、复杂代码、数学证明、长期项目记忆和专业判断,Grok 4.3 还不该成为第一选择。
GPT-5.5 和 Claude Opus 4.7 仍然更适合承担这些高价值、高风险任务。
这次 xAI 的策略很清楚:先把模型做得足够强,再把价格打下来,用速度和工具能力扩大可用场景。
它没有赢下「最聪明模型」的头衔,但可能会赢走一部分真实使用量。
因为市场并不总奖励最强者,也奖励够强、够快、够便宜的选择。
Grok 4.3 的意义正在这里。它把 xAI 从一个经常靠马斯克声量吸引注意的模型供应商,往更务实的 API 和消费级工具竞争者方向推进了一步。
它看起来很好,确实很好;只是还没好到能让 GPT-5.5 和 Claude Opus 4.7 紧张。
消费者可以期待它降价、提速、让更多 AI 应用变得便宜。
也该记住,在需要真正聪明和可靠的地方,Grok 4.3 仍然只是备选项。
参考资料:
https://artificialanalysis.ai/models/grok-4-3