新智元报道
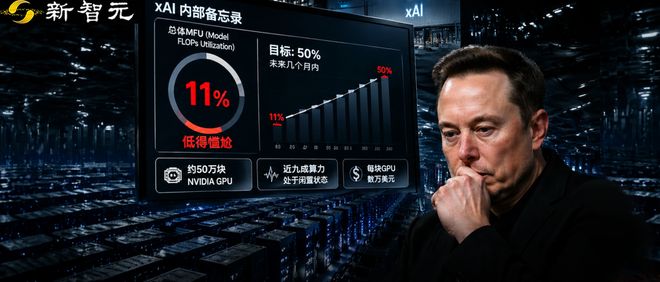
据最近的报道,马斯克手上的数十万张GPU仅发挥了约11%的有效利用率。xAI总裁Michael Nicolls在内部备忘录中对此表示尴尬。
尽管存在质疑的声音,但这一说法已经得到了证实和广泛讨论。
《The Information》首次披露了这个消息,并且Business Insider随后确认了Nicolls的备忘录内容。
Michael Nicolls在备忘录中直接指出,目前xAI所持有的50万张英伟达GPU的实际利用率仅为约11%。
这一数字引发了行业内对于AI竞赛关键指标的变化——从单纯计算能力的竞争转向了如何高效利用这些资源的探讨。
无论官方是否确认,xAI已经在其官网上公布了Colossus集群的信息:目前扩展至20万张GPU,并计划在未来达到100万张,成为已知规模最大的AI超算之一。
面对这一挑战,Nicolls为团队设定了一个目标——未来几个月内将利用率提升到50%。这不仅是一个硬件问题,更涉及到训练栈和并行策略的优化。
实际上,在xAI内部,虽然拥有大量的GPU资源,但这些设备的有效使用率却远低于理想状态。这一现象引起了行业的广泛关注,并促使人们重新审视AI竞赛中的关键指标。
从工程角度来看,11%与50%之间的差距不仅仅是硬件投入的问题,而是整个系统架构和训练策略的挑战。
Colossus集群已达到20万张GPU规模,计划继续扩展至100万张。这一宏伟目标背后,是巨大的技术和管理压力。

尽管xAI在孟菲斯建设了庞大的Colossus集群,并且已经取得了显著进展,但如何进一步提高其实际利用率成为了一个亟待解决的问题。
关于11%的误解普遍存在,人们常常误以为这是89%资源被浪费的表现。实际上,这个数字衡量的是模型浮点运算利用效率(MFU)。
MFU是评估AI系统性能的一个重要指标,其定义为实际使用的FLOPS与理论峰值计算能力的比例。
它反映了GPU在进行训练时能够有效转化的算力比例。这一比率不仅涉及硬件本身,还涉及到软件优化、数据处理等多个方面。
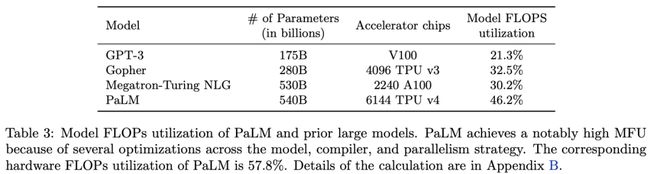
Lambda公司的一篇白皮书指出,在生产环境中,大规模语言模型(LLM)的MFU通常处于35%到45%之间,被视为正常水平。
相比之下,xAI的数据显得异常低。这一情况甚至低于历史上许多其他知名项目的效率水平。
MFU不仅是一个技术指标,它还揭示了AI竞赛中对资源利用效率的新要求。随着行业的发展,提高MFU成为了一个新的关键目标。
从工程实践的角度来看,低MFU意味着大量的电力和硬件时间被消耗在不必要的环节上,而非直接用于训练模型本身。
这些问题不仅影响到xAI自身,也反映了整个行业的挑战。许多同行面临着类似的困境:如何更有效地利用现有的计算资源?
尽管存在困难,但xAI已经开始通过租借其GPU来应对这一情况。这表明他们正在寻找新的途径来最大化现有硬件的价值。
例如,编程创业公司Cursor就计划使用xAI的数万张GPU来进行新模型Composer 2.5的训练工作。
这样的合作不仅有助于Cursor快速推进其业务发展,也帮助xAI分散了部分成本压力。同时,这也意味着Colossus正在逐步向外部提供服务的角色转变。

在过去的一段时间里,xAI内部进行了重大人事调整,包括一些关键岗位的变动和新成员的加入。
这些变化表明,xAI正努力从多个角度优化其系统架构和服务模式。同时,这也揭示了一个重要趋势:AI竞赛的关键指标正在向如何更高效地利用资源转变。
随着技术进步,AI行业面临着新的挑战和机遇。提高MFU不再仅仅是硬件性能的问题,而是涉及整个训练栈、并行策略以及模型工程的综合优化问题。
在未来的发展中,xAI和其他公司都需要更加注重这些方面的工作,以期在竞争激烈的市场环境中取得优势地位。
几乎是低于所有公开前沿训练系统的下沿。
至于低MFU的原因,Lambda也总结过。
显存压力、单卡batch太小、过度的激活重计算(activation checkpointing)、把权重切得过碎的张量并行带来的跨GPU通信开销,任何一个都会拖累MFU。
一位同行研究员的描述更形象:HBM显存比加速器慢得多,芯片大量时间在等数据进来;网络拓扑里任何一处瓶颈,都会拖垮几千张卡的同步。
业内管这个叫「记忆墙(memory wall)」。
11%不是单点故障,是系统级问题。
这不止是xAI一家的问题
不过,把xAI单拎出来说事,也未必公平。
The Information报道里还提到了一位同行匿名研究员的一句评价:「跑过40%对xAI的大多数竞争对手来说也很难」。
这是一个刺破全行业体面的问题。
报道里提到,一些研究员为了让自己的MFU数字「好看一点」,会反复重跑训练实验,人为抬高利用率。
原因有两个:一是怕被老板骂;二是怕GPU被调走分给别的团队。
这些研究员的逻辑是,我的卡现在确实在闲着,但我只是「在分析上一轮训练结果,马上就要再跑」,不能让它被收走。
在AI大厂里,跑分这件事不只发生在公开榜单上,也发生在内部GPU调度系统里。
xAI并不是一个硬件部署上的反面教材。The Information提到,xAI在业内以「按英伟达推荐方式部署GPU」著称,是模范生。
模范生只跑了11%,说明问题不在硬件、网络拓扑标准,而在更上层的训练栈、并行策略和模型工程。
11%这个数字,也捅破了行业心照不宣的那层窗户纸:买卡和用卡是两回事。
Colossus开始把卡租出去了
也几乎在同一时间,xAI开始把卡租出去了。

xAI CEO马斯克(左)与Cursor CEO Michael Truell(右)。Cursor计划用数万张xAI的GPU训练Composer 2.5。
据Business Insider报道,编程创业公司Cursor将使用「数万张xAI的GPU」来训练它的最新编程模型Composer 2.5。
Cursor此前估值约290亿美元,近期又被曝正洽谈约500亿美元估值。
如果把两件事放在同一时间线上看,至少可以说明:在自训效率尚未完全释放时,把部分算力外部化,可能成为xAI摊薄基础设施成本的一种选择。
更微妙的是xAI基础设施团队近期的人事地震。
原基础设施负责人Heinrich Küttler离职,Jake Palmer接管了物理基础设施,SpaceX的Daniel Dueri被调来负责算力基础设施。
与此同时,Cursor原产品工程负责人Andrew Milich和Jason Ginsburg跳槽到xAI,直接向马斯克和Nicolls汇报。
把这些信号串起来,能看到一个正在变形的Colossus:
它在官方叙事里是「世界最大超算」、是xAI打败OpenAI的算力底牌;但在业务层,它正在一点点变成一座「半成品云厂商」。
AWS、Azure、GCP靠着出租算力赚到的利润是天文数字;CoreWeave、Lambda这种新玩家干脆围绕租GPU建生意。
xAI如今走的是同一条路,只不过一边租一边自己也得训模型。
自己跑不满,就让别人来跑,这是当代GPU资本的标准动作。
xAI官方至今没有正面回应过11%这个数字,官网首页仍然挂着122天建成、92天翻倍到20万张GPU、路线图通往100万张GPU的官方叙事。

xAI Colossus 122天建成,从10万张GPU扩到20万张只用了92天,路线图通往100万张。但越快扩张,训练栈和并行策略的复杂度也越大。
但速度有速度的代价。
Megatron-LM公开的数据已经给出了警告:当你把H100集群强扩展到4608张时,仅仅是通信开销,就足以把MFU从47%拖到42%。
这是英伟达自己的旗舰训练框架,跑在标准化最强的硬件上。
xAI要把卡数从20万推到100万,意味着通信、调度、容错、并行策略的复杂度还可能要再涨一个数量级。
122天建成是工程奇迹,但每一天的奇迹背后,都有一笔运维债在悄悄记账。
AI竞赛的KPI正在切换
过去比的是仓库:谁先囤到H100、谁先建成超算、谁能从英伟达手里抢到下一批GB200。
这个游戏花钱就能玩,所以马斯克、奥特曼、扎克伯格、黄仁勋都下场了。
现在比的是工程师:谁的训练栈调得最好、谁能把每一美元GPU CapEx转化成最多的有效token。
这个游戏花钱解决不了,只能靠时间、人才和工程文化。
GPU是入场券,但MFU才是真正的考验。
xAI虽然拿到了最大的那张入场券,但它能不能把这张券兑现,还要看那个「低得尴尬」的数字,能不能真的拉到Nicolls所说的50%。
参考资料:
https://www.theinformation.com/newsletters/ai-agenda/xai-shows-hard-use-lot-gpus?rc=epv9gi
https://arxiv.org/pdf/2204.02311