让龙虾学会操作手机,实现了从训练、测试到部署的全流程智能化。
 衡宇
衡宇没有人工干预和预设脚本。
ClawGUI团队成员分享了一项创新成果:ClawGUI。
这并非是游戏作弊手段,而是具备视觉理解与操控能力的通用GUI智能体的应用实例。无论是在手机App上玩游戏、填写表格还是浏览网页,其操作方式都是一致的。
那么问题来了:一个可以自主完成消消乐挑战的人工智能,离在实际生活中帮助我们进行复杂的手机操作还有多远?这里指的是类似人类般地看屏幕、理解界面和执行任务的智能体。
目前GUI智能体的研究普遍存在训练、评估与部署环节各自独立的问题。模型通常在仿真环境中完成训练后,缺乏有效的途径迁移到真实设备上;评测标准也不统一,难以进行横向比较;而实际部署时又需要额外构建一套基础设施。这种分散的状态导致整体推进的效率低下。
今天,ZJU-REAL团队带来了ClawGUI这一开源框架,它覆盖了从在线强化学习训练、标准化评估到真实设备部署的整体流程。
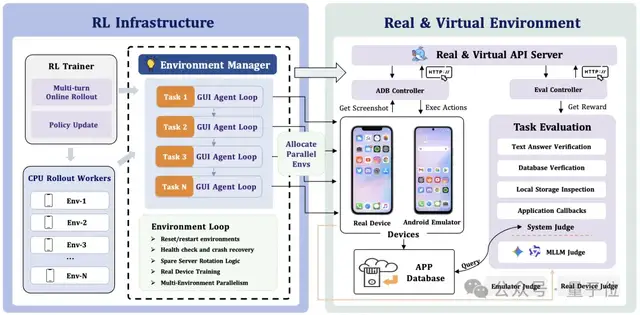
利用这套流水线,一个仅有2B参数的小模型ClawGUI-2B在MobileWorld基准测试中取得了显著成绩(SR值为17.1),远超基线的11.1,接近于8B规模模型的表现水平。
ClawGUI系统的架构总览显示了其核心功能。
ClawGUI-RL训练模块使GUI智能体在真实环境中不断进步。
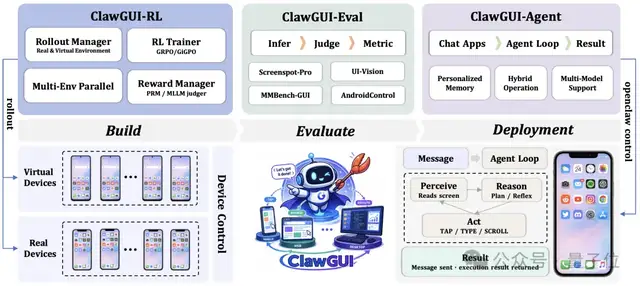
在这种环境下进行强化学习训练需要持续与设备交互。截屏、解析屏幕内容、执行操作并获得反馈,形成完整的回合。这要求训练基础设施具备大规模环境模拟和设备管理的能力。
ClawGUI-RL将整个训练系统分为三层:环境控制、奖励机制设计及策略优化。
环境层面上,所有设备的后端(Docker虚拟机与物理手机)被抽象为统一接口。每个环境遵循“重置→执行→评估→回收”的标准生命周期,并通过Spare Server轮转确保长时间训练的稳定性。
奖励机制方面,ClawGUI-RL采用了二元结果奖励加上PRM逐步奖励的组合设计,以此缓解长序列决策中的稀疏奖励问题。
策略优化层面,该框架支持GRPO、GiGPO等主流强化学习算法,并提供统一接口,方便研究者进行不同策略的灵活切换与对比。
PRM逐步奖励机制使得每次操作都能得到即时反馈,而非仅仅在任务结束时给出结果评分。
通过使用Docker技术的Android虚拟环境,ClawGUI-RL可以支持大量虚拟Android环境的同时运行。团队还提供了一套经过验证的端到端真机强化学习训练流程,包括物理手机和云手机在内的多种设备都可接入。
ClawGUI-Eval模块确保了模型评估结果的一致性和可信度。
虚拟环境与真机训练
在GUI智能体评测领域长期存在的问题是复现一致性。不同框架下同一模型的测试数字往往存在显著差异。
为了解决这个问题,ClawGUI-Eval采用了标准化的Infer→Judge→Metric三阶段流水线方法。
该评测系统覆盖了6个基准(ScreenSpot-Pro、UIVision等),支持11+种模型,并在48个有官方基准的测试点中成功复现了46个,总体复现率为95.8%。
实验结果
复现的关键在于细节:坐标系统匹配、图文输入顺序正确、prompt格式严格一致等。
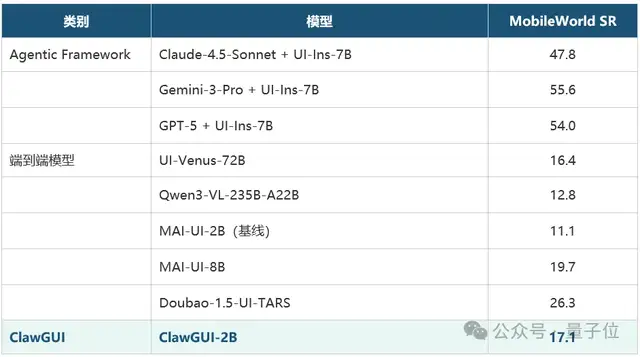
ClawGUI-Eval为用户提供了一套标准化的评测工具,使得不同模型之间的比较更加公平和准确。
用自然语言控制手机是GUI智能体真正的应用场景之一。
OpenClaw-GUI基于nanobot框架构建,实现了通过聊天平台发指令来操控真实手机的功能。它支持接入12+个聊天平台,并能自动完成环境检测、推理和评分等任务。
该系统具备跨平台的硬件兼容性、多模型的支持能力及个性化记忆功能,能够记录每次执行的过程并保存结构化数据以供后续分析使用。
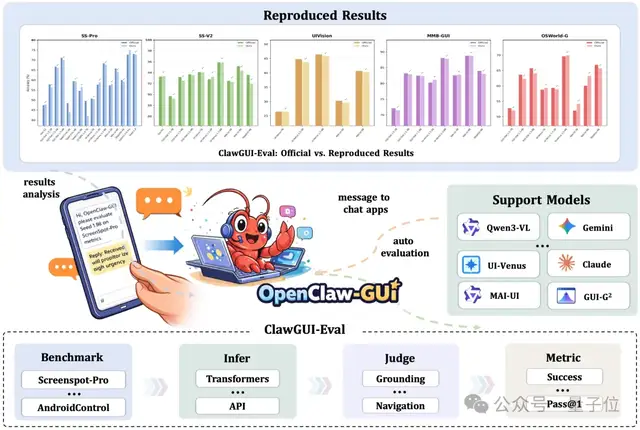
ClawGUI项目的长远目标是探索强化学习训练与评估一体化的可能性,并逐步推进真机部署技术的发展。未来计划包括支持桌面和网页环境的在线RL扩展以及实时强化学习算法的应用。
ClawGUI团队不认为GUI比CLI更好,而是想通过打通训练、评测到部署全流程来研究GUI智能体的发展潜力及其与CLI协作的可能性。
ClawGUI-RL使GUI Agent在真实环境中进行在线训练成为可能;ClawGUI-Eval为社区提供了一套可信赖的评估工具;而OpenClaw-GUI则将这些技术从实验室推向了实际应用中。
项目现已公开发布,欢迎更多人关注和支持这项研究。
1. 坐标系统不匹配=准确率归零。Qwen2.5-VL输出绝对像素坐标,Qwen3-VL输出[0,1000]归一化,StepGUI用[0,999],搞混一个就是灾难。
2. 图文输入顺序(tv vs. vt)可导致数个百分点差异。大部分模型需要图片在前(vt),MAI-UI需要文本在前(tv),用错直接崩盘。
3. 哪怕一句”You are a helpful assistant.”也能带来约1%的提升。System prompt必须严格对齐官方。
4. Prompt格式必须逐字对齐。措辞微小差异就可能影响结果。
5. 温度建议设为0.0。非零温度影响坐标精度。
所有推理结果已全部开源,欢迎下载验证。
OpenClaw-GUI:一句话控制手机
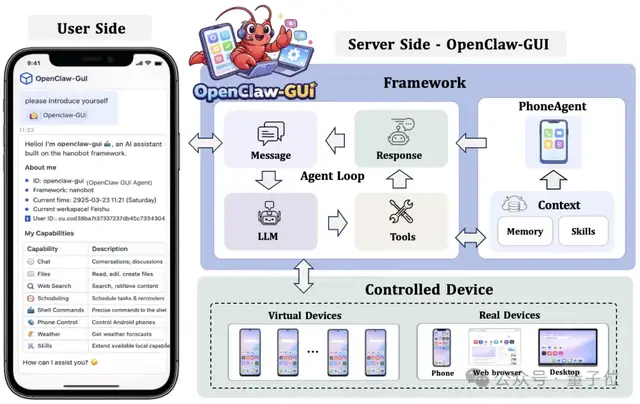
GUI智能体真正的价值,在于能够在用户手边的真实设备上运行、帮人完成实际任务。OpenClaw-GUI正是为此而生,把GUI智能体带到真机上落地。
基于nanobot框架构建,OpenClaw-GUI实现了通过自然语言控制真实手机。接入飞书、QQ、Telegram、Discord、Slack、钉钉等12+聊天平台,用户在聊天窗口发一句指令,Agent就能截屏理解界面、规划操作路径、执行点击和输入。
更关键的是,OpenClaw-GUI把评测也集成进来了。说一句「帮我测一下qwen3vl在screenspot-pro上的指标」,Agent会自动完成环境检测→多GPU推理→判分→指标计算→结果对比。这本身就是CLI+GUI协作的绝佳例证,计算密集型工作由CLI高效完成,人机交互和结果呈现依赖GUI。
核心能力:跨平台支持Android(ADB)、鸿蒙(HDC)、iOS(XCTest);多模型接入AutoGLM、MAI-UI、GUI-Owl、Qwen-VL、UI-TARS;个性化记忆,自动学习用户偏好,跨任务持续复用;Episode记录,每次执行以结构化Episode保存,支持回放与数据集构建;Web UI基于Gradio,支持设备管理、任务执行与记忆查看。
展望:GUI的故事远未结束
2026年,CLI Agent无疑是最火的赛道。Claude Code、Gemini CLI、CodeBuddy……一个自然的问题浮现:GUI智能体还有必要吗?
研究团队倾向于认为:GUI的故事远没有结束,CLI+GUI的融合或许是通往通用Agent的一条重要路径。
人类短期内离不开GUI。从文字到图片到视频,越容易被感知的媒介越具备传播优势。外卖、打车、社交、购物,移动互联网绝大多数的交互发生在图形界面上。至少在可见的未来,GUI仍将是数字世界的主要入口。
不是所有App都有API。微信、银行、大量企业内部系统只有图形界面。CLI面向Agent执行,高效干活;GUI面向人类理解,感知和交互。两者更像是互补关系而非替代关系。
GUI的「可见性」提供了一种独特的信任机制。假如Agent在执行任务时涉及支付操作,CLI以用户看不见的方式直接完成了付款,造成的损失谁来承担?GUI操作到关键步骤时,用户可以看到屏幕上正在发生什么、随时介入。这种可控性可能是纯CLI方案较难提供的。
Online RL的工程挑战远未被解决。GUI Agent的RL训练需要与真实App交互,登录验证、反爬机制、动态UI变化,大规模RL Scaling的稳定性仍是行业难题。ClawGUI-RL的Spare Server轮转和周期性重启机制是一个初步的探索,距离大规模生产级训练还有很长的路要走。
路线图
ClawGUI的规划不止于此:OpenClaw-GUI支持自然语言手机操控与评测;ClawGUI-RL可扩展的Mobile Online RL训练基础设施,支持PRM逐步奖励;ClawGUI-Eval标准化评测套件,6个Benchmark,95%+复现率;ClawGUI-2B达到17.1 SR(基线11.1);后续将推进真机部署OpenClaw-GUI,直接部署在手机上避免云端隐私泄露;Desktop / Web Online RL,将在线RL扩展至桌面和网页环境;以及基于OPD算法的实时强化学习。
总结
ClawGUI不是要证明GUI比CLI更好,而是想探索一种可能性:训练、评测、部署打通之后,GUI智能体能走多远?CLI和GUI的协作又能释放出怎样的潜力?
ClawGUI-RL让GUI Agent的在线训练从虚拟环境走向真机,ClawGUI-Eval为社区提供了一套可信赖的评测标准,OpenClaw-GUI把GUI智能体从研究带到了真实设备。
项目已开源,欢迎Star支持,让更多人看到GUI Agent的可能性。
项目地址:
https://github.com/ZJU-REAL/ClawGUI
项目主页:
https://zju-real.github.io/ClawGUI-Page/