最近,GPT-5.5正式亮相!内测工程师透露:失去它就像失去了手臂。
 梦晨
梦晨相较于前一版的GPT5.4,新版本在代码开发、知识工作和科学研究领域均有显著提升。
GPT-5.5现已发布,带来全新的智能体验。
在这次更新中,并没有奥特曼亲自站出来分享初体验的感受,而是邀请了一些早期测试用户来讲述他们的使用经历。
其中一名英伟达的工程师表示,在短暂失去访问权限后说:“失去了它就像截肢了一样。”
这次OpenAI与英伟达的合作是前所未有的。
GPT-5.5和英伟达GB200、GB300 NVL72系统从一开始就是联合设计的,无论是训练还是部署阶段都紧密结合在一起。

另外,推广Codex到整个英伟达公司,并公开了与CEO黄仁勋交流的邮件内容。
说归说,闹归闹。
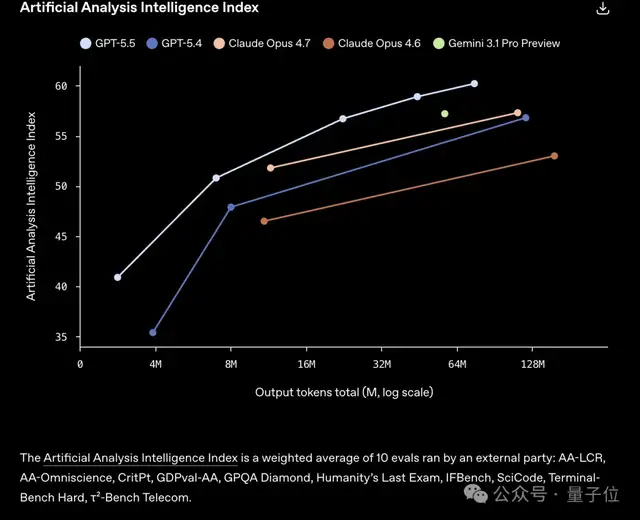
根据Artificial Analysis Intelligence Index的综合测试结果,有两种解读方式:
在同样的分数下,GPT-5.5使用的token比其他模型更少。
或者在使用同样数量的token时,它完成的任务更多。
最引人注目的并不是这些跑分数据。
以往每次模型升级,“更强”和“速度减慢”总是相伴而生。
这是由于更大规模的模型需要更多的参数和更长的时间进行思考。用户在享受智能的同时也要接受延迟的问题。
然而,GPT-5.5打破了这一规则。
在实际生产环境中,它的逐token延迟与上一代相当,但完成任务所需的token却减少了。
这使得它不仅效率更高,功能也更加强大。
Codex更新至最新版本后可以使用GPT-5.5,并且上下文窗口扩展到了400K。
GPT-5.5在编程领域的提升尤为显著。
与上一代相比,用户不再需要小心翼翼地拆分任务并一步步监控其进展。
用户只需提出需求,GPT-5.5会自行进行处理,并提供最终结果。
OpenAI还展示了Codex下由GPT-5.5生成的3D游戏动作,在网页上直接运行。
(但价格翻倍)

这包括使用TypeScript/Three.js实现战斗系统、敌人遭遇等元素。
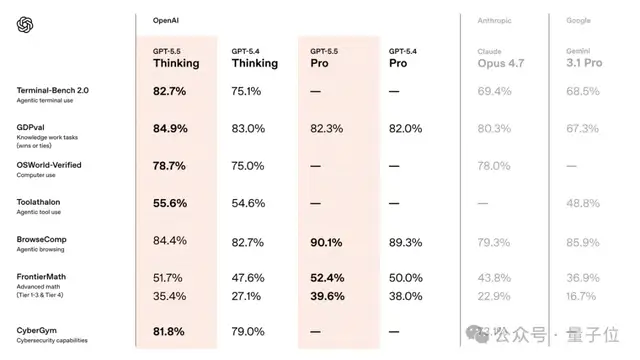
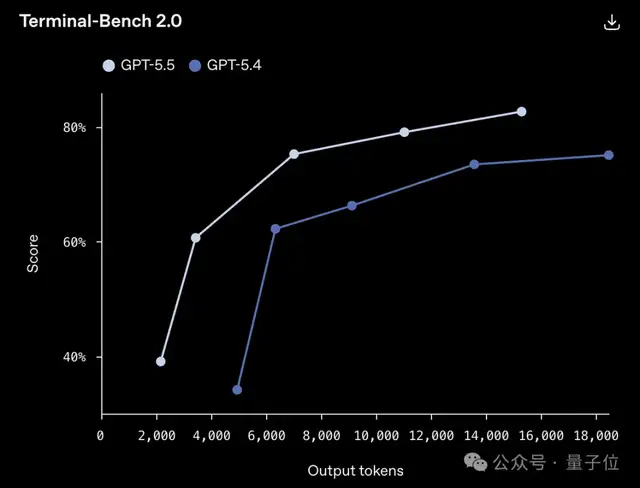
在复杂的命令行工作流测试中,GPT-5.5的表现为82.7%。

给编程开挂
上一版本的得分是75.1%,而目前最强的竞争者Claude Opus 4.7则只有69.4%。
这意味着新一代模型在面对高难度问题时表现更佳,卡顿比例显著下降。
Dan Shipper进行了一项实验,他的App出现了一个bug,并请一位顶尖工程师重构代码。结果发现GPT-5.5能独立做出与该工程师相同的设计决策。
这是Shipper第一次在一个编程模型身上感受到真正的“概念清晰度”。
GPT-5.5不仅能够理解问题,还能自主地找到解决方案。
多位高级工程师反馈称,GPT-5.5在推理和自主性上明显优于前一版本和其他竞争产品。
它具备预测测试与审查需求的能力,并能在没有明确指示的情况下提前发现问题。
编程领域的进步只是开始,知识工作和科学研究领域也出现了类似的变化。
接下来请各路嘴替:
GPT-5.5在Codex中的应用不仅仅局限于编程。它还能生成文档、整理表格以及制作PPT等。
OpenAI强调新版本更加理解用户的需求,并且能够自主使用工具进行检查并完善输出结果。
超过85%的OpenAI员工每周都在用Codex工作。(剩下的15%又是怎么回事呢?)
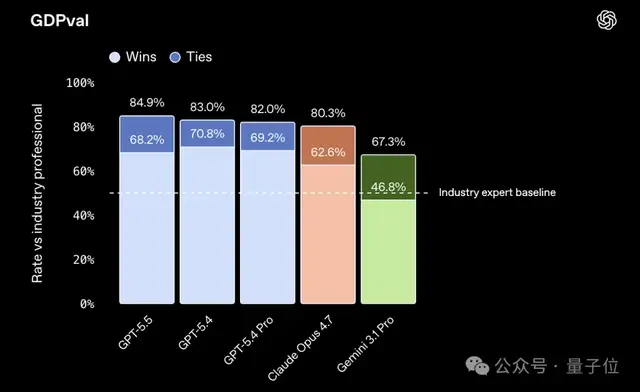
在知识工作的基准测试中,GPT-5.5的表现为84.9%,领先于Claude Opus 4.7。
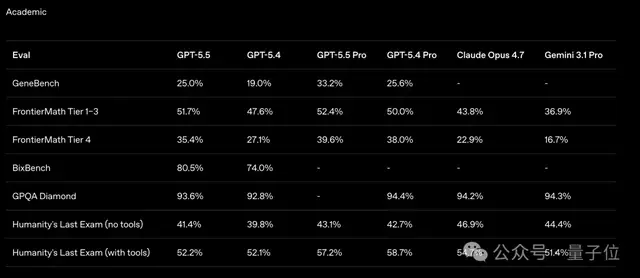
FrontierMath Tier 4是目前最困难的数学基准之一,题目来自未发布的论文和开放性问题。
GPT-5.5在这一测试中的得分达到了39.6%。相比之下,Claude Opus 4.7只有22.9%,差距明显。

科学家们如何利用GPT-5.5也是一个亮点。
Bartosz Naskręcki通过Codex生成了一个代数几何可视化应用,并且只用了短短的11分钟。

这一过程在以前可能需要花费半天时间来搭建项目框架。
编程之外
Derya Unutmaz使用GPT-5.5分析了一份包含62个样本和近28000个基因的数据集,并生成了一整份研究报告,这原本需要团队几个月的时间才能完成。
OpenAI认为GPT-5.5不再像是一次性答案引擎,更像是一个“研究伙伴”。
它不仅能查找资料,还能多轮批改论文并提出新的分析方案。每次对话都建立在前一次的基础上进行深入讨论。
GPT-5.5在数学领域做出了重大贡献。
还是先看评测结果。
Ramsey数是组合数学中最重要的问题之一。
它研究的是网络需要达到何种规模才能保证某种秩序必然出现的问题。
过去几十年,关于off-diagonal Ramsey数的渐近性质一直悬而未决。
GPT-5.5找到了一个新的证明路径,并且这个证明被数学界最严格的工具Lean确认无误。
一个AI在纯数学的核心领域做出了原创贡献,这一成就过去一年内还不可想象。
“更强却更快”的性能是如何实现的呢?
答案在于整个推理系统被推倒重来。

GPT-5.5与英伟达GB200、GB300 NVL72系统的联合设计,使其在相同的延迟下智能水平大幅提升。
Codex通过分析生产流量数据自动生成了负载均衡的分区启发式算法,这比固定的分块策略更加高效。
这个新的自适应算法根据实际流量动态调整分块策略。
token生成速度提升了超过20%。
模型优化了自己的基础设施,使AI运行得更快。
整体推理系统的重构加上模型参与自身的优化,带来了这样的成果。
OpenAI表示这标志着“迈向新的工作方式”的一步。
当模型开始优化自身运行的基础设施——
这一步到底迈出了多远?
未来展望:有了GPT-5.5,OpenAI预计未来的版本发布将会更加频繁且显著进步。

首席科学家Jakub Pachocki在电话会议中表示:“过去几年的进展其实比我们预期得要慢。”
这表明未来将会有更多的突破。
更强却不更快的秘密
“更强却更快”是怎么做到的?
答案不是在某一个环节上做了优化。OpenAI把整个推理系统推倒重来了。
前面提到GPT-5.5和英伟达GB200、GB300 NVL72系统是联合设计的,结果在同等延迟下,智能水平大幅跃升。

但还有另一个故事。
GPT-5.5驱动的Codex系统,分析了数周的生产流量数据,然后写出了一个负载均衡的分区启发式算法。
之前,请求被切分成固定数量的块,分发给加速器处理。但固定的分块策略在不同流量模式下并不总是最优。有时候块分得太粗,有时候太细,资源利用率忽高忽低。
Codex看了几周的真实流量数据,自己写了一套自适应的分区算法。根据实际流量形态动态调整分块策略。
token生成速度提升了超过20%。
模型优化了运行自己的基础设施,AI在让自己跑得更快。
推理系统的整体重构,加上模型参与自身的优化,两件事叠在一起,带来了这样的结果。

OpenAI说,这是“迈向用计算机完成工作的新方式的一步”。
但当模型已经开始优化自己运行的基础设施——
这一步,到底迈了多远?
One More Thing
有了GPT-5.5,OpenAI预计接下来模型发布数据将加快。
我们看到短期内有相当显著的进步,中期有极其显著的进步。
我认为过去几年进展出乎意料地缓慢。
说这话的是首席科学家Jakub Pachocki ,场合是与记者的电话会议上。
参考链接:
[1]
https://openai.com/index/introducing-gpt-5-5/
[2]
https://x.com/firstadopter/status/2047378435555651856?s=20