GPT Image 2团队的最新消息显示,该小组由无锡的一位才子领导,在短短四个月内取得了令人瞩目的成就。
 梦晨
梦晨底层架构已彻底重构
这个卓越的小团队只有13名成员,但他们在图像生成领域做出了重大贡献。
尽管他没有详细说明是否采用了扩散模型或自回归技术,但他将其描述为“通用模型”或者说是图像领域的“GPT”。
在一篇推文中,陈博远透露从去年12月底开始,团队在短短四个月内就完成了显著的改进。

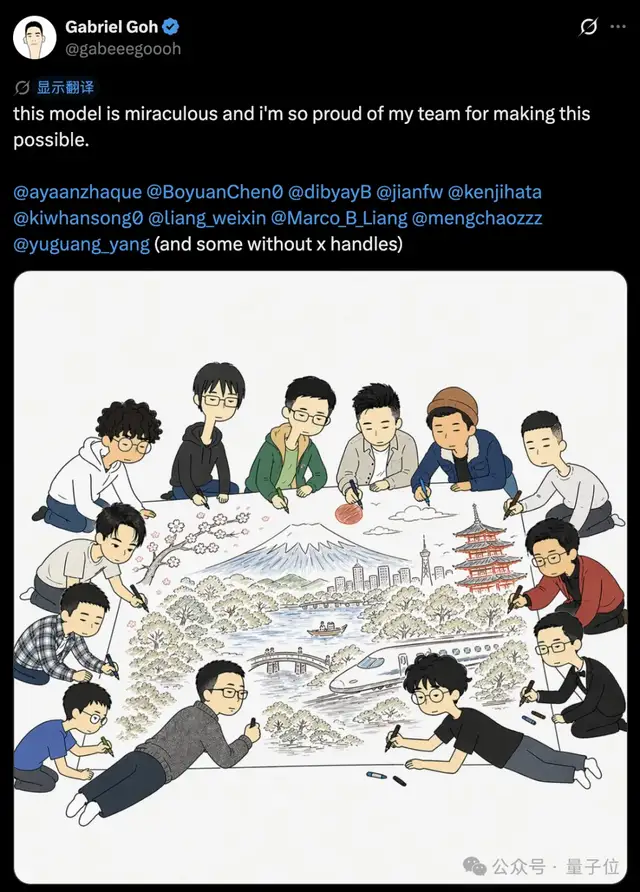
作为团队的研究负责人,Gabriel Goh展示了整个小组的照片,并引发了一些网友的好奇:“怎么这么多亚洲面孔?”

研究人员陈博远本人的成长经历令人印象深刻。从最初对Python一无所知到成为研究领头人,他只用了短短几年时间。

在麻省理工学院读书期间,他与Kiwhan Song在同一位导师Vincent Sitzmann的指导下学习,并且共同完成了几项重要研究项目。
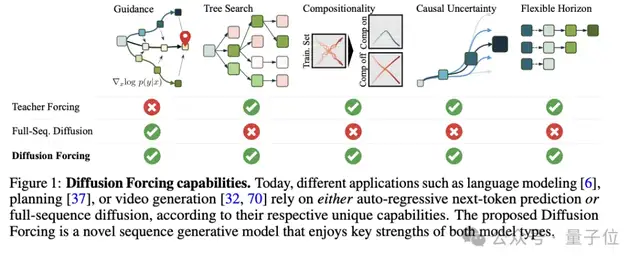
陈博远的研究成果包括Diffusion Forcing,这是一种全新的序列生成训练方法,结合了逐token独立噪声级扩散和因果下一个token预测的优点。
在谷歌实习期间,他以共同一作的身份发表了SpatialVLM,该研究构建了一个大规模的3D空间推理 VQA 数据集,并赋予视觉语言模型定量/定性的空间推理能力。

他还开发了一种指令微调技术,后来被Gemini 2.0采用。在高中时期,他遇到了谷歌DeepMind的资深研究员夏斐,这使他对AI产生了浓厚的兴趣。
夏斐两次邀请陈博远到DeepMind实习,在那里积累了大规模模型训练的经验,并对多模态系统的数据需求有了深入理解。
博士毕业后,他在2025年6月加入OpenAI,迅速成为GPT图像生成五人核心成员之一,并且还是Sora视频生成团队的一员。
他通过为不同语言的队友制作海报展示了模型的文字渲染能力。每张海报中的文字都十分精确。

中科大博士Jianfeng Wang在GPT Image 2团队中负责的是让AI更好地理解和遵循指令,使模型能够理解更复杂的场景和对象信息。
在他的带领下,新模型可以准确地画出不同的时间点,并且根据指定的空间布局执行任务。
加入OpenAI之前,Jianfeng Wang在微软工作了近九年,在DALLE-3项目上与OpenAI团队有过合作。
他在计算机视觉领域发表了多篇学术论文,涵盖了图像分类、目标检测以及语义分割等方向的研究成果。
JianFeng Wang认为GPT Image 2大大缩小了用户意图和模型产出之间的差距,真正实现了所想即所得的目标。

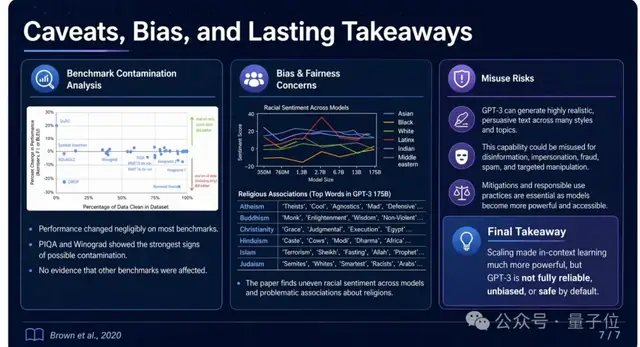
Yuguang Yang在团队中展示了生成信息图和PPT的能力。他将75页的GPT-3论文输入ChatGPT后自动生成了幻灯片,并且演示了这项技术可以为科研人员节省大量时间。
他的工作经历非常丰富,从量化分析师到纳米机器人研究者再到Alexa语音研究员和Bing搜索的研究员,每一份工作都与机器学习密切相关。
加入OpenAI后,Yuguang Yang除了图像生成还参与了ChatGPT智能体项目的开发。
团队负责人Gabriel Goh从2019年加入OpenAI开始,他的研究领域也经历了从理论到图像生成的转变。
他全程参与了DALL-E的研究,并且在之后一直致力于多模态领域的探索和发展。

另一位团队成员Weixin Liang在Meta实习期间发表了Mixture-of-Transformers这项成果,显著降低了多模态模型预训练的成本。
他是斯坦福大学的博士毕业生,同样来自浙大竺可桢学院,与Yuguang Yang相比要晚好几年毕业。

Weixin Liang和陈博远一样在毕业后迅速加入了OpenAI,并成为团队的核心成员之一。
Ayaan Haque曾在Luma AI工作过一段时间,在那里参与了Dream Machine视频生成基础模型的训练。

Bing Liang在Google工作了五年多,之后跳槽到OpenAI继续从事图像生成方面的研究。

这只是开胃菜。
Mengchao Zhong是上海交通大学校友和得克萨斯农工大学硕士毕业生。他曾在Pinterest和Airtable担任软件工程师,在OpenAI负责多模态产品的工程开发。

Dibya Bhattacharjee是一位耶鲁大学的学生,曾经获得过IPhO铜牌,并且在CIE A-Level数学和生物考试中取得全球最高分的荣誉。
最晚加入团队的是Kiwhan Song。除了做研究之外,他还是团队里的提示词大师,官方演示图很多都出自他手。
回顾从最早的DALL-E到今天的GPT Image 2.0的发展历程,这个团队逐步解决了图像生成的各个方面:不仅要能画出清晰的画面,还要确保画面美观和精准。
尽管近年来人才流动频繁,但OpenAI依然能够吸引来自不同专业背景的人才,并且鼓励跨领域合作的研究方式。
从小团队起步到获得突破性进展,公司不断投入更多资源支持他们的研究工作,最终改变了整个行业格局。
这个团队还展示了一种独特的风格,模仿吉卜力工作室的艺术作品进行图像生成,这种画风的提示词也被公布了出来。
Yuguang Yang在GPT Image 2的发布活动中演示了生成信息图和PPT。

整整75页的GPT-3论文拖进ChatGPT,自动生成7张幻灯片。
他的经历可以说是团队成员中最丰富的,每换一个工作都是跨界,但都聚焦机器学习。
他本科在浙大竺可桢学院学的工程,博士在约翰斯霍普金斯大学期间学的是计算化学物理与机器学习。
他第一份全职工作是量化分析师,在清华做访问研究员期间研究的是用于纳米机器人的强化学习和控制算法。
后来他在亚马逊做过Alexa语音研究。
又在微软做过Bing搜索的查询理解和检索、文档理解。
2025年初加入OpenAI后,除了图像生成还参与过ChatGPT智能体项目。
他在个人账号上介绍GPT Image 2的信息图生成能力,可以为科研人员节省大量时间。
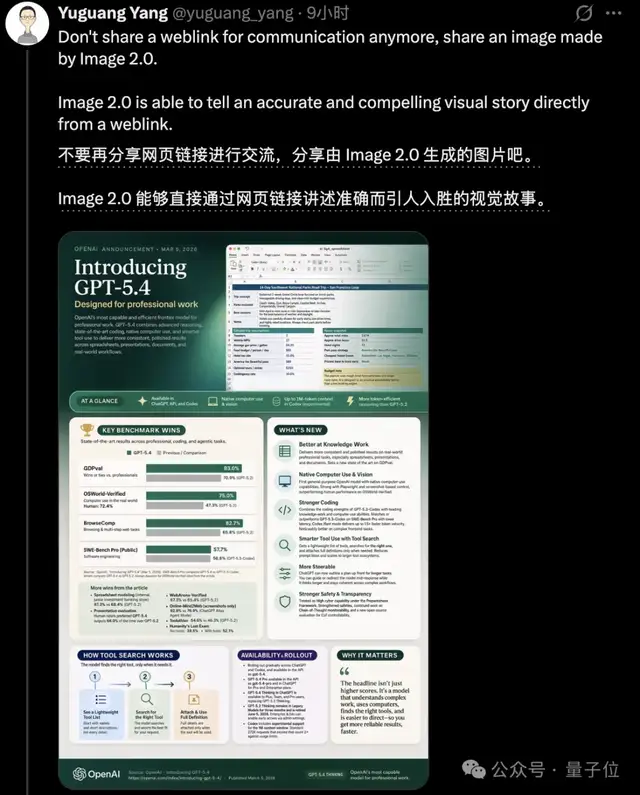
还反复提醒大家,要做信息图不要忘记选择思考模式。
从DALL-E到GPT Image 2.0
从团队成员Kenji Hata的自我介绍中得知,GPT Image 1.0也就是GPT-4o的图像生成部分。
有一个人从DALL-E开始参与了OpenAI多模态系列研究的全程。
他就是GPT Image 2.0团队负责人Gabriel Goh。
从2019年加入OpenAI,他的早期研究更篇理论,专注于可解释性和凸优化等等。
从DALL-E开始慢慢转向了图像生成。
看到另一位团队成员Weixin Liang的研究履历,GPT Image 2的技术底色又揭开了一角。
他在Meta实习期间的代表作Mixture-of-Transformers,引入模态解耦的MoE和解耦注意力,显著降低多模态模型预训练的计算成本。
他博士毕业自斯坦福,本科也毕业自浙大竺可桢学院,不过比Yuguang Yang要晚好几年。
Weixin Liang与陈博远一样都是25年博士刚毕业就加入OpenAI,迅速成为团队的核心成员。
其他GPT Image 2.0团队成员还包括:
Ayaan Haque,之前在Luma AI 工作,参与过Luma的视频生成基础模型Dream Machine的训练。
Bing Liang,在Google干了5年多,参与Imagen3、Veo、Gemini Multimodal,2025年跳到OpenAI做图像生成研究。
Mengchao Zhong,本科上海交通大学校友,硕士毕业于得克萨斯农工大学,在Pinterest和Airtable做过软件工程师,在OpenAI负责多模态产品的工程。
Dibya Bhattacharjee,耶鲁大学,2015年IPhO铜牌,CIE A-Level数学和生物全球最高分。
Kiwhan Song是25年10月最晚加入的,除了做研究之外,他还是团队里的提示词大师,大家看到的官方演示图很多都出自他手。
……
从最早的DALL-E到今天的GPT Image 2.0,这只团团队先后解决了。画得出来、画得清楚、画得好看、画得准。

尽管近年来OpenAI的人才流动很大,但OpenAI还是那个能不断吸引各种有个性的人才,不限制专业、欢迎跨界,信奉自下而上涌现式研究的公司。
从一个小团队开始,有了突破后公司倾斜更多资源,直到改变世界。
One More Thing
曾经,GPT-4o图像生成模仿吉卜力风格生成的头像席卷了全世界。
如今GPT Image 2.0的团队成员,都把自己头像换成了这种奇脖子画风。
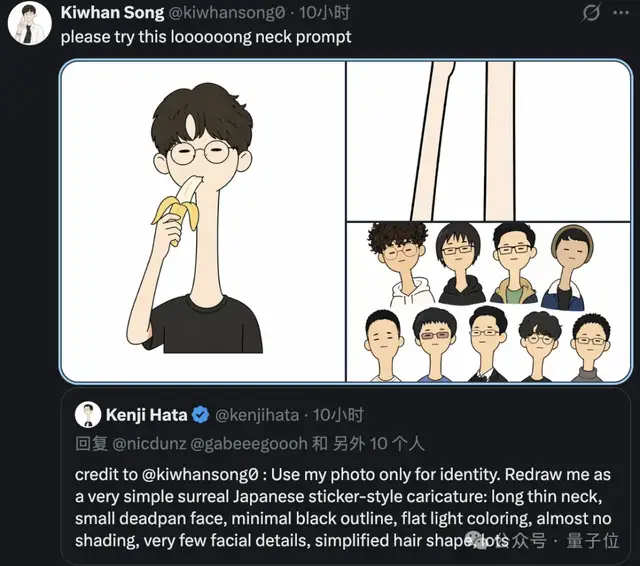
那么这种画风的提示词是什么?团队成员也公布了出来
Use my photo only for identity. Redraw me as a very simple surreal Japanese sticker-style caricature: long thin neck, small deadpan face, minimal black outline, flat light coloring, almost no shading, very few facial details, simplified hair shape, lots of white space, plain white background, slightly awkward and funny. Ultratall 1:3 image.参考链接:
[1]
https://x.com/gabeeegoooh/status/2046674385407512687?s=20
[2]
https://venturebeat.com/technology/openais-chatgpt-images-2-0-is-here-and-it-does-multilingual-text-full-infographics-slides-maps-even-manga-seemingly-flawlessly