近日,朋友圈被GPT-Image-2生成的图像所占据,占了近七成。
 henry
henry全网开源,即刻可用
无论是中文海报、复古杂志封面还是直播画面与社交截图,甚至高考试卷也能逼真模拟。
为解决这一问题,商汤最近开源了一个全新的理解与生成一体化模型——SenseNova-U1,尽管其小版本只有8B的参数量,却能复制不少GPT-Image-2的功能。
利用这个新模型可以制作出高质量的招聘海报、太阳系图解以及钢铁侠和马斯克太空集群的信息图。这些图像都具有高度的真实感与美观性。
SenseNova-U1在信息图表、文字密集排版及图文交错领域表现出色,与GPT-Image-2并驾齐驱,并且在多项指标上领先于开源模型,在推理速度方面也接近主流商用闭源模型的水平。
U1为何如此出色?这得益于其独特的连续性图文创作功能。以往的传统架构难以同时保留语义和像素细节,而U1通过让两者在一个共享上下文的空间里工作解决了这一难题。
在实际操作中,这种连贯性使模型能够自然地将文字与图片结合在一起,比如制作一个详细的牛排烹饪教程或漫画分镜技巧教学图。其输出的图像具有高度的一致性和完整性。
这种新颖的能力使得U1在很多场景下都能提供高质量的图像生成服务。例如,在简历信息输入后可以得到一张精美的手绘风格海报,或者通过简单的指令就能获得连环画和做菜教程图等。
此外,商汤还为U1配备了自研推理栈LightLLM和LightX2V,使得其能够高效地生成高质量的图像。例如,在H100/H200单节点上生成一张2048×2048大小的图仅需约9秒。

尽管U1表现出色,但商汤也在开源文档中明确指出了一些局限性,包括上下文长度限制、复杂场景下的人物细节不够稳定等问题。不过这些问题都已在持续改进之中。

商汤还为用户提供了方便使用的SenseNova-Skills技能包,它涵盖了图像生成、PPT制作等多方面功能,极大地提高了工作效率。

目前,SenseNova-U1的两个版本已经全部开源,并且可以在Hugging Face和GitHub上下载。对于不想自己部署的用户来说,可以直接使用U1 Lite Skill进行体验。

另外,在不久将来,“办公小浣熊”也会推出集成U1的新功能模块。
这几个曾经被公认是AI生图最难啃的硬骨头,U1能跟GPT-Image-2挤进一桌。
在具体的图像理解与生成的多项指标上,SenseNova-U1也是登顶开源模型的榜首。
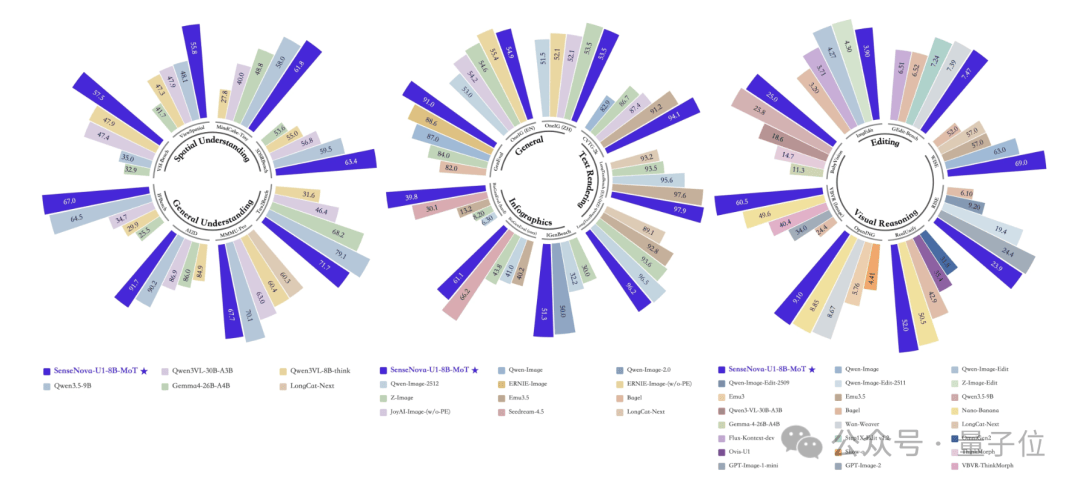
在推理响应速度上也具备相当的优势,逼近主流商用闭源模型。
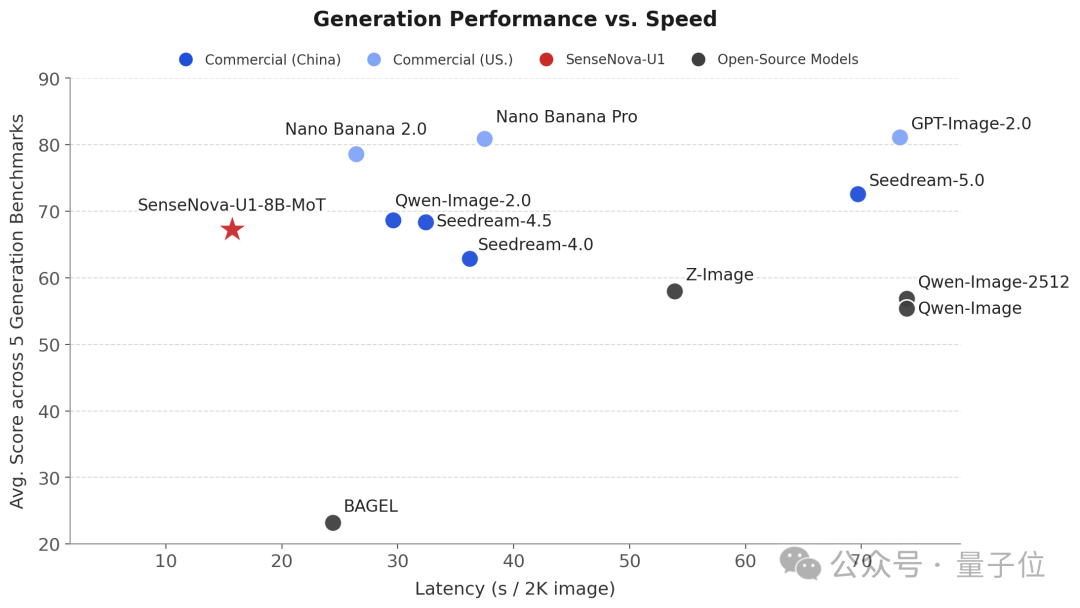
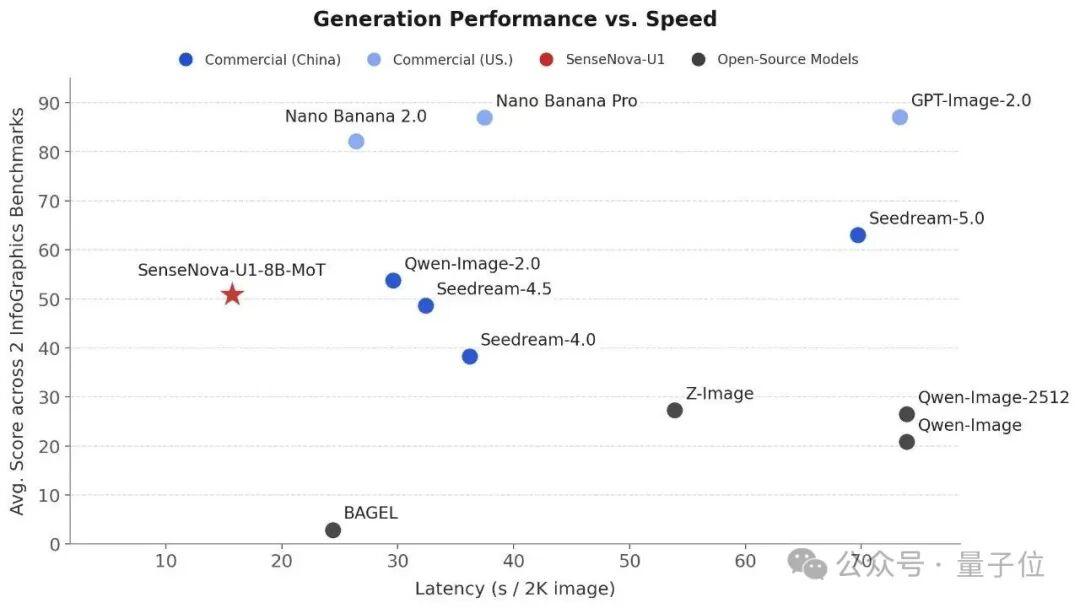
这是怎么做到的,咱往下看。
连续性图文创作,这次是原生的
先说U1这次最有意思的能力,连续性图文创作。
所谓连续性图文创作,就是文字和图片在一段输出里自然交叠,而不是文字归文字、图片归图片。
这听起来很简单,但实际上很难。因为文字保留语义、图片保留像素细节,这两件事在传统架构里几乎是天敌——
保了语义就丢了像素,保了像素就稀释了语义。
U1的做法是让两者在同一个表征空间里共享上下文,语义丰富性和像素级视觉保真度第一次同时拿住。
简单讲,就是模型能像人一样,边思考边画草图,文字和图片在一段输出里自然交叠。
比如,我让它生成一个“煎牛排的操作教学”。它能从食材准备,沥干水分、调味、煎制和翻面……讲到最后装盘。
每一步的关键操作都有图,牛排的形象从生肉到五分熟一路保持高度一致,不会画着画着变成另一块肉。

再比如,我想学一点漫画分镜技巧。
它能直接给我吐出图文并茂的教材式段落,从准备阶段、镜头建立、再到引入道具、次要角色一应俱全,比纯文字解释直观得多。

这种“始终是同一个主体”的连贯性看起来朴素,但对生成模型却很难。
传统范式得在多个模型之间来回调用,各画各的,角色形象很容易在第三步就走样。U1是单次单模型调用直接出全套。
对一个新模型来说,还有一个值得关注的考验就是——
高密度信息图。
在模型界面中,你可以直接输入“自己的简历信息”,它就能返回你一张手绘风格的海报,信息分布、配色、字体层级都安排得明明白白。
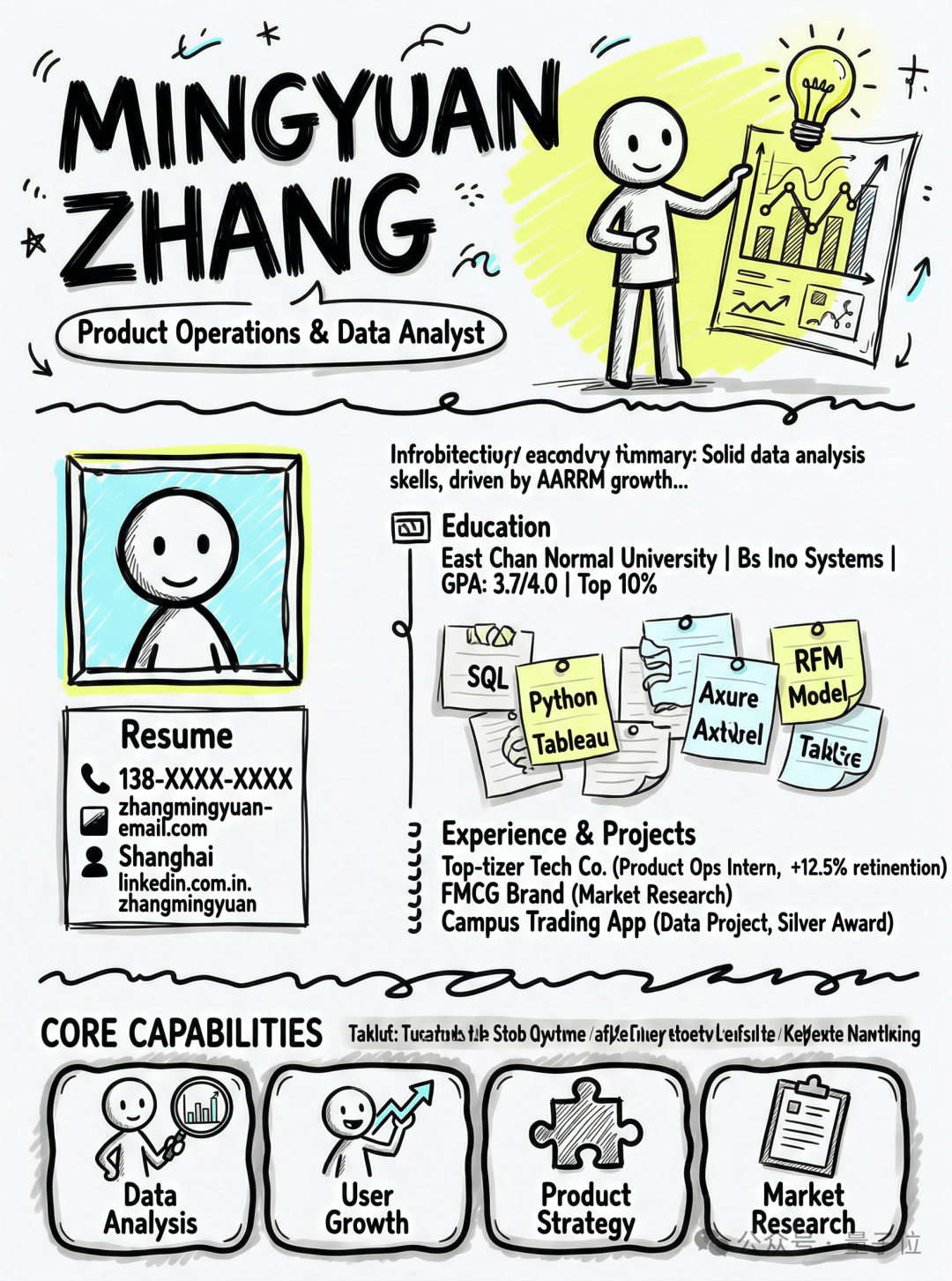
让它讲“三只小猪盖房子”,我输入只有这么“7个字”,输出就能直接给你一整组连环画——
三只小猪、三种材料、三栋房子、最后那只大灰狼,一格一格排好,顺序对得上故事。

炒红烧肉这类做菜教程图,也可以一次直出,图文对应。

给一句“做杯咖啡的英文流程图”,图也直接出来了。
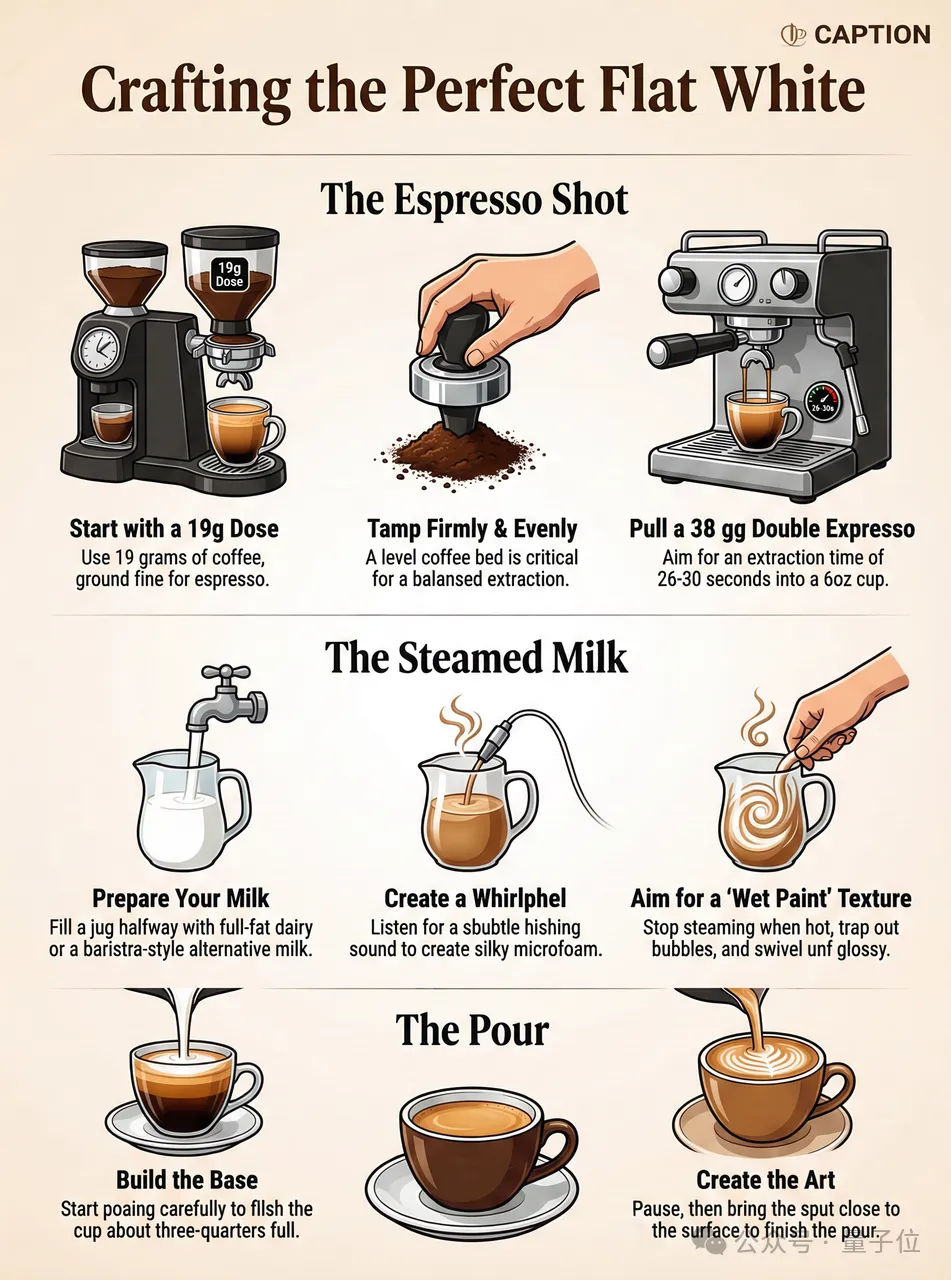
在讲究排版、涉及多种元素的插画场景中,U1也能实现比较精细的效果,比如这张划船乐的教学总览图。
最有意思的是这个,扔给它一张路边常见的“电梯安全”警示牌,让它换个排版做成一张信息图。
它还能直接把这个实现完美迁移,把版式从警示牌切成了科普卡片。


前段时间火爆的产品爆炸图,在U1这里也可以做到。一台相机,被它拆得整整齐齐:
镜头组、反光镜、快门、传感器、芯片,电池什么的,统统被它拆得整整齐齐悬浮在空中,标注线一根不少。

这种程度的玩法,以前是超大参数模型的专属。更有意思的一点是,SenseNova U1 Lite还在行业首创了图文交错的思维链。
这种会推理的能力放到图像编辑上会更有趣。
我扔给它一张刚泡好的玻璃杯热茶,让它“画出一小时后的样子”。它没有简单地直接出图,而是先做了一段推理:
一是给自己定约束,同一只玻璃杯、同一张原木桌面、同一种侧逆光,这样两张图放一起才看得出“是同一杯茶过了一小时”。
二是推导物理:刚泡时,叶片高速舒展、气泡从叶脉逸出、蒸汽在杯壁上留下弧形折射;
一小时后,多酚类扩散均匀,茶汤变深红褐,叶子完全沉降呈半透明,杯底跟桌面交界处出冷凝痕迹。光影也跟着从“清晨的清冷”过到“午后的慵懒”。

类似的还有几个测试。
给它一个绿色的香蕉,模型会先推理“叶绿素分解+糖化”,从而保证输出的是一根带着斑点的成熟香蕉。

可以说,这款新模型不只是在改图,还具备了一定的物理常识。
NEO-unify,一个网络实现“看”和“画”
看到这,你可能想问,这是怎么做到的?
U1的底层是一套叫NEO-unify的架构。一个模型同时会看、会画,理解和生成在同一个网络里完成,中间没有任何拼接。
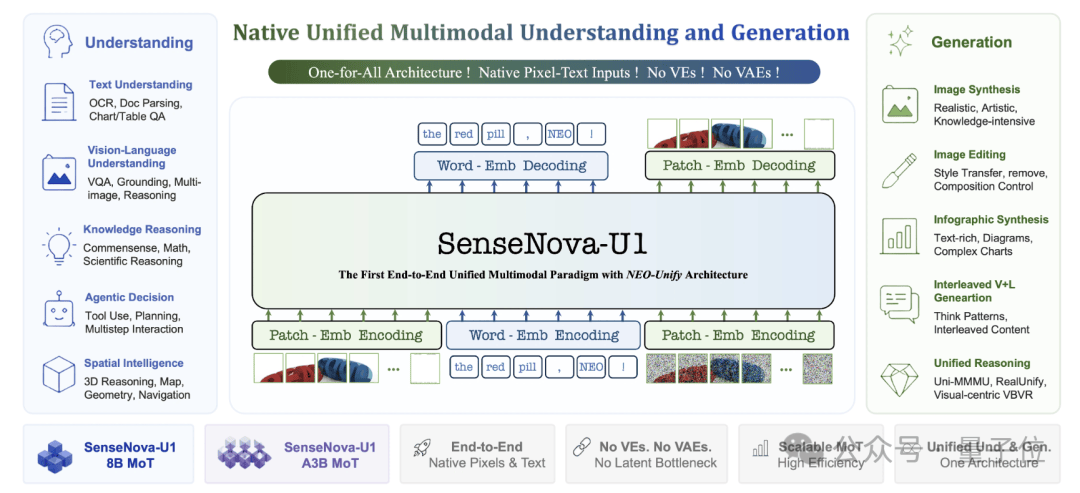
在过去,多模态模型的标配经常是这样的,视觉编码器(VE)负责看,变分自编码器(VAE)负责画,理解归理解,生成归生成,中间靠适配器拼起来。
NEO-unify把这两个东西都拿掉了,不需要VE,不需要VAE,模型直接吃像素,直接吐像素。
具体来说,这一过程分为三步:
第一步,引入近似无损的视觉接口,把图像的输入和输出统一成同一种表示。
第二步,用Mixture-of-Transformer做主干,理解和生成共享同一套底层。
第三步,文本走自回归,视觉走像素流匹配,两套目标函数在同一个学习框架里跑完。
△图片由SenseNova U1生成
这套技术架构给了NEO-unify独门绝活,连续性图文创作。
传统模型要做这件事,得外挂工具或者后处理拼接。U1底层就是统一的,原生支持图片和文字的交叉排版,所有视觉内容都来自模型自身,不调用外部工具。
模型在思考一个问题的时候,可以一边推理一边生成中间示意图,把复杂逻辑可视化。
生成一段教程,可以在恰当的位置自然地插入说明图。
落地到模型,两个规格。SenseNova-U1-8B-MoT ,8B参数,端侧能跑。SenseNova-U1-3AB-MoT,总参数38B的MoE架构,提供更强的能力,底层都是同一套NEO-unify。
此外,商汤还给U1配了一套自研推理栈,LightLLM跑理解、LightX2V跑生成,两条路解耦各管各的。以H100/H200单节点为例,生成一张2048×2048的图,端到端大概9秒。
全网开源,即刻可用
值得一提的是,商汤这次在README里把模型的局限也直接写了出来:
上下文最长32K、人物在复杂场景里的细节有时不够稳、长文字渲染偶尔会出现拼写或排版错误、连续性图文创作目前还是beta。
不过这些短板都标了“持续改进中”。换句话说,U1这次开的不是终点,是个起点。
为了方便大家使用,商汤这次顺手开源了一套SenseNova-Skills技能包,把U1做成了Agent里能直接调的工具。
sn-infographic自带87种版式、66种风格,自己评分自己挑;挂进OpenClaw,一句 /skill sn-infographic “提示词”,图就出来了。
Skills不只是infographic一个,整套覆盖图像生成、PPT制作、Excel数据分析、深度研究、跨平台搜索。
目前,SenseNova-U1两个模型已经全网开源。Hugging Face和GitHub都能下,仓库地址在https://github.com/OpenSenseNova/SenseNova-U1。
想直接体验不动手部署的,现在可以直接进入SenseNova U1 Lite Skill,https://github.com/OpenSenseNova/SenseNova-Skills。
另外,办公小浣熊也即将上线U1。