智谱近期发布了一篇技术博客,揭示了“降智”背后的原因——Scaling的烦恼。
 鹭羽
鹭羽原因主要归咎于Prefill阶段的问题。
近期,智谱的技术团队在处理GLM-5系列模型时遇到了一系列挑战,并将这些难题统称为「Scaling Pain」。
从发布GLM-5以来,用户报告了许多使用复杂Coding Agent任务时遇到的问题,如乱码、重复内容以及出现罕见字符等现象。
这些问题在标准环境中几乎无法重现,给团队带来了不小的困扰。

经过数周的排查和测试,智谱终于找到了这些问题的根本原因,并将其归结为推理环境下的高负载状态管理不善。
为了帮助其他开发者避免类似的陷阱,他们详细总结了自己的经验教训,并提供了实用的解决方案建议。
如果你正考虑增强自己的Agent功能,请务必先阅读这份来自一线实战的经验分享。

最后则是生僻字的出现。
这些问题让工程师们意识到存在潜在的技术隐患。
为了查明原因,团队通过回放用户反馈并反复运行相似请求进行测试。

定位关键Bug
事情是酱紫的——
结果表明,模型本身并不是造成异常的主要因素。
- 接下来,在模拟在线环境后,他们调整了PD分离比例,并逐步增加系统负载,最终在每千次请求中大约能复现3-5个异常情况。
- 这一发现进一步确认了高负载条件下推理状态管理的重要性。
- 尽管如此,线下的问题重现率仍低于用户报告的实际频率,这意味着现有的检测方法仍有改进空间。
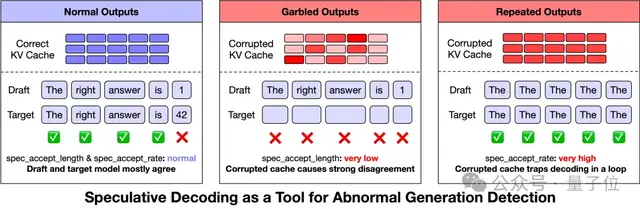
为此,智谱团队优化了异常输出的检测机制。他们注意到投机采样(Speculative Decoding)指标可以作为重要参考。
在GLM-5中发现的三类异常现象可以通过spec_accept_length的数值变化来预测和识别。
当乱码或生僻字出现时,这通常意味着目标模型与草稿模型之间的KV缓存状态不匹配;
而重复生成则表明损坏的KV缓存可能使注意力模式退化。
根据这些观察,智谱团队制定了在线异常监控策略:
在spec_accept_length持续低于1.4且生成长度超过128 token,或spec_accept_rate超过0.96时,系统将自动停止当前任务并重新分配给负载均衡器。
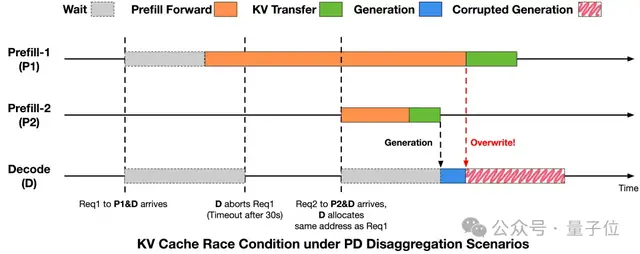
为了深入解析异常的根源,团队重点研究了PD分离架构下的KV Cache竞态问题。
分析显示,请求生命周期与推理引擎中的KV Cache回收复用不一致是导致冲突的主要原因。
为解决这一挑战,研究人员在推理引擎中引入了一套严格的时序规则,在请求终止和KV Cache写入完成之间设置显式同步点。
这一机制确保了KV Cache的写入不会跨越内存复用边界,避免了跨请求的数据损坏问题。
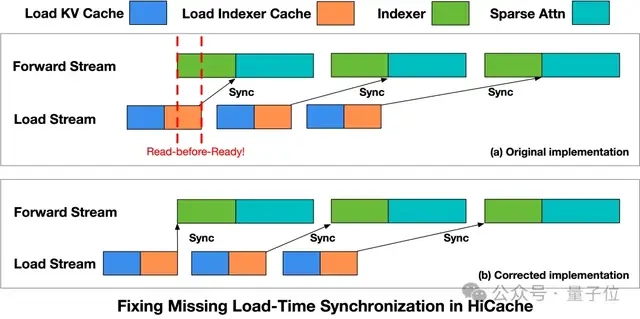
此外,团队还解决了HiCache加载时序缺失的问题,通过引入数据准备就绪验证和计算之间的同步策略来消除read-before-ready的风险。
这项修复措施在相同的工作负载下消除了由执行顺序不一致引起的异常现象。
经过这些改进后,异常输出的发生率显著降低。
为了进一步缓解Prefill阶段的内存和带宽压力,团队设计了KV Cache分层存储方案——LayerSplit。
在这种方案中,每个GPU只保留部分层的KV Cache数据,从而减少了每个GPU的内存使用量。
这种方法通过在执行Attention计算前将相应层的KV Cache广播给其他相关rank来实现跨节点的数据同步。
为了减少通信开销,团队还设计了KV Cache广播与indexer计算重叠的机制,进一步隐藏了通信延迟。
实验显示,在Cache命中率达到90%,请求长度在40k到120k区间内时,系统吞吐量提高了10%至132%。
总体而言,这些优化措施极大地提升了系统处理Coding Agent任务的能力。
智谱认为,在智能进入高并发和长上下文的编码代理场景后,维护推理基础设施的质量变得至关重要。
未来大规模AI不仅需要Scaling Law推动的能力增长,还需要与之相匹配的系统工程技术支持。
在启动Indexer算子之前,先插入一个Load Stream同步点,确保相应级别的Indexer缓存已完全加载。Forward Stream只有在数据准备就绪后才会进行计算,从而消除了read-before-ready的问题。
应用此修复后,在相同的工作负载条件下,由执行时序不一致引起的异常被消除,系统终于得以稳定。
Prefill侧优化
事实上,这两种Bug都指向了同一个常见的系统瓶颈:
在长上下文的Coding Agent Serving任务中,Prefill阶段已经成为影响系统性能的主要因素。
于是为了缓解Prefill阶段在高并发下的内存和带宽压力,团队另外设计了KV Cache分层存储方案——LayerSplit。
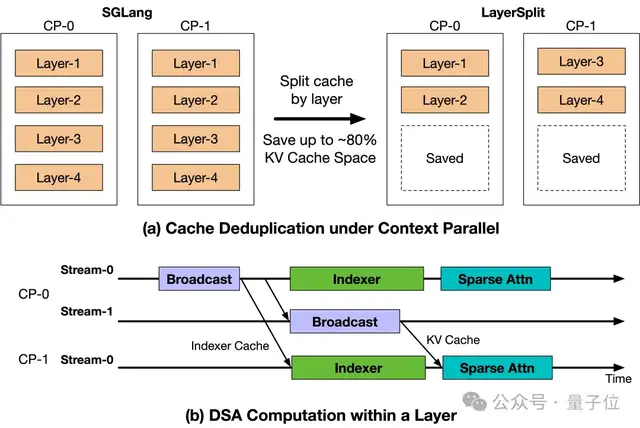
在该方案中,每个GPU只存储部分层的KV Cache,显著降低了每个GPU的内存占用。然后在执行Attention计算前,将对应层的KV Cache广播给其他相关rank。
为了降低通信开销,还进一步设计有KV Cache广播与indexer计算的重叠机制,将通信延迟隐藏在计算过程中。这样唯一的额外通信开销就来自Indexer Cache的广播,其大小仅为KV Cache的八分之一,整体通信成本可以忽略不计。
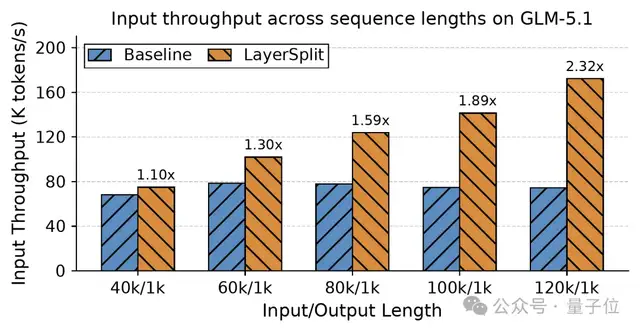
团队将LayerSplit和GLM-5.1结合发现,在Cache命中率达到90%、请求长度在40k到120k区间内时,系统吞吐量提高了10%到132%,且随着上下文长度的增加,收益也随之增长。
总体而言,该优化显著提升了系统在Coding Agent场景下的处理能力。
同时智谱也认为,当智能真正进入高并发、长上下文的Coding Agent场景后,维护推理基础设施的输出质量变得至关重要。未来大规模AI需要的不仅是Scaling Law推动的能力增长,还必须有等量级的系统工程支撑。
参考链接:
[1]
https://z.ai/blog/scaling-pain
[2]
https://www.zhipuai.cn/zh/research/159