
新智元报道
最近,OpenAI宣布向全美医生免费提供临床版ChatGPT,这款工具专为处理转诊信、保险预授权和病历文书设计,并要求使用者必须通过验证才能使用。
这次的更新让ChatGPT进入美国医疗领域,成为医生工作台上的重要助手。
OpenAI总裁兼联合创始人Greg Brockman最近宣布了这一重大举措:
推出了一款专为临床医生设计的ChatGPT版本——ChatGPT for Clinicians。

该产品面向所有通过身份验证的美国临床医生免费开放,包括医师、执业护士和药剂师等专业人员。
ChatGPT for Clinicians提供七大功能模块:
- 免费使用先进模型处理复杂的医疗问题;
- 实时搜索同行评审的临床信息,包含具体引用和出版日期;
- 可选HIPAA合规支持(通过签署业务协议);
- 医生只需使用NPI验证身份即可开始使用ChatGPT for Clinicians,无需医院统一部署。
- OpenAI此举标志着医疗AI从患者私下咨询转向医生公开应用的转变,直接进入美国所有医生的工作环境。
- 仅限于持有执照的专业人员如医师、护士和药剂师等可以访问此工具。
- OpenAI的目标是通过提供专业用户身份验证来确保工具的合法使用场景接入权。
72%的美国医生已经在临床实践中应用了至少一种人工智能技术,相较于一年前增加了24个百分点。
OpenAI官方博客指出,全球每周有数百万临床医生使用ChatGPT支持其工作,过去一年内用户量翻了一倍以上。
ChatGPT for Clinicians的功能之一是帮助医生编写转诊信等文书工作。
没有NPI,进不了门
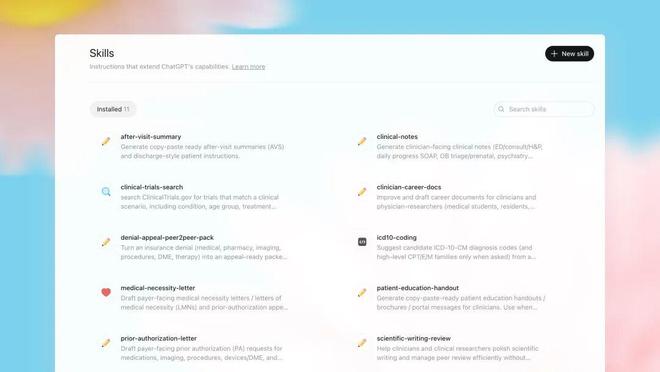
医生可以将常见流程转化为可复用的技能模板,并根据需要进行调整和执行。
Skills模块已经安装了11个覆盖保险预授权、病历文档及患者教育材料等功能的临床技能。
通过Clinical Search功能,医生能够基于大量同行评审文献获取实时答案,大大提高了工作效率。
ChatGPT for Clinicians的深度研究功能允许医生设定信任来源并快速生成详尽报告。
研究过程中获得的循证综述可以自动计入继续医学教育学分,无需额外培训或申请程序。
OpenAI选择了最具挑战性的行政文书工作作为切入点,以解决医生面临的最大痛点之一。
这一策略看似平凡,但可能是医疗人工智能领域首个大规模成功的应用场景。
为了证明产品的优越性,OpenAI开发了一套专门的评估标准HealthBench Professional。
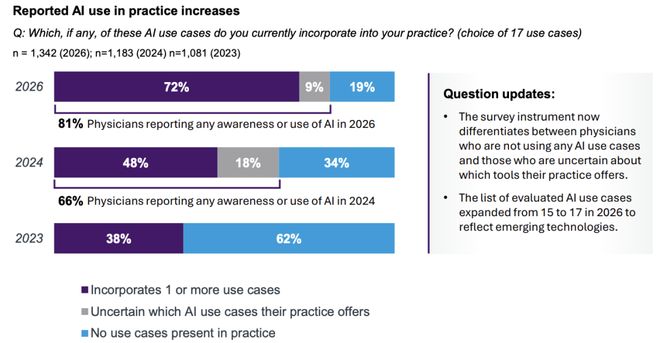
HealthBench Professional从525个最终任务中筛选出最复杂的真实对话案例进行测试。
ChatGPT for Clinicians在这些高标准的评测中表现突出,得分显著高于其他模型和人类医生。
不看病
先从干杂活开始
尽管评分系统严谨,但OpenAI设计并执行测评可能影响其公信力。
医生们对人工智能的主要顾虑包括数据隐私、安全验证及责任归属问题。
OpenAI强调对话内容不会用于训练模型,并支持多因素认证等措施保障信息安全。
为了进一步增加透明度,OpenAI发布了《保持患者第一》政策蓝图,明确指出最终责任仍归于人类医生。
在使用ChatGPT for Clinicians生成的文档中如果出现错误,签名医生将承担相应的后果。
ChatGPT for Clinicians在发布前测试了6924段对话,并获得99.6%的安全准确率评价。

然而,在实际医疗环境中可能出现的风险仍不容忽视。
AI虽然可以提高工作效率,但错误的代价可能非常严重。
ChatGPT for Clinicians的主要目标是减轻医生处理文书工作的负担,并逐步向更复杂的临床决策支持领域扩展。
OpenAI从患者自助查询到个体医生工具再到医院系统部署的战略布局已经明确展开。
在第一阶段,ChatGPT允许患者自己查找健康信息;第二阶段面向个人医生提供专业版服务;
既当裁判又参赛
最终目标是实现大型医疗机构的大规模应用。
目前包括波士顿儿童医院等多家顶级机构已经在测试部署。
而Clinicians则专注于尚未统一采用AI技术的个体医生群体。
OpenAI计划在未来与Better Evidence Network合作,向其他国家开放试点项目。
随着越来越多医生开始使用人工智能工具,未来医疗工作方式将会发生重大变革。
例如文书工作时间将大幅缩短,文献查询也将变得更加便捷高效。
ChatGPT for Healthcare的推出标志着AI在医疗领域的新里程碑,有望成为每位医生日常工作不可或缺的一部分。
最终这场技术革新能否真正改善医疗服务还是引发新的问题,答案可能需要从实际诊室操作中寻找。
在355个由三名独立医生指定标准引用来源的子集中,ChatGPT for Clinicians引用这些来源的频率高于人类医生。
这些测试成绩和数据虽然很亮眼,但一个事实必须清楚:出题的是OpenAI,参赛选手包括OpenAI的模型,最高分还是OpenAI的产品。
这就像一家公司自己设计了招聘考试,然后宣布自家员工考了第一名。
即使考试设计很严谨(多医生裁定、红队测试、高难度筛选),但「自评」和「他评」之间的公信力差距不能忽略。
好消息是,Stanford的MedHELM和MedMarks等第三方评测中,OpenAI的模型同样排在前列,多少补上了一部分独立验证的缺口。
隐私、责任、幻觉
三道没跨过去的坎
成绩再好,医生也不会因为一张跑分表就把信任交出去。
AMA同一份调查揭示了另一面:医生对AI最大的三个顾虑,是数据隐私、安全有效性验证、以及出了错谁负责。
先看隐私。
OpenAI承诺对话不用于训练模型,账户支持多因素认证。但HIPAA合规不是默认开启的,需要通过BAA才能获得支持,前提是医生有权为其账户签署BAA。很多日常临床任务可以不涉及PHI,但一旦涉及,合规流程并不是开箱即用的。
再看责任。

OpenAI发布的「Keeping Patients First」政策蓝图,明确AI应加强医患关系,最终责任归人类医生。https://cdn.openai.com/pdf/keeping-patients-first.pdf
OpenAI在同步发布的政策蓝图「Keeping Patients First」中明确写道:AI应加强临床人员与患者之间的关系,人类从业者仍承担最终责任。
意思是:AI可以帮你写,出了事还要你担责。
如果ChatGPT生成的转诊信里有一个错误的药物剂量,签名的医生要承担后果。
最后是幻觉问题。
6924段对话测试中,99.6%被评为安全准确。这个数字看起来很高,但在医疗场景下,0.4%的错误率意味着每250个回答里可能有一个不安全或不准确。
对每天处理几十个查询的忙碌临床医生来说,这个概率不能忽略。
而且这个99.6%是发布前由OpenAI合作的医生顾问测试得出的,不是大规模真实临床环境下的数据。
AI可以写错一封邮件,但在医疗场景下,错误的代价不一样。
医生不会被替代
但工作方式正在被重写
回头看ChatGPT for Clinicians这步棋,它要解决的不是替医生看病,而是重写医生每天花最多时间的「非诊断工作」。
转诊信、保险预授权材料、病历文书草拟、临床搜索、跨期刊文献综述……产品页Skills模块下挂着的任务清单,基本就是美国医生吐槽了十几年的那些日常杂活。
路线很清楚:先动最重、最枯燥、最容易自动化的行政文书,再慢慢往临床推理、决策支持、教育学分这些更核心的场景上走。
不涉及诊断、处方和最终治疗决策。
从ChatGPT到ChatGPT for Healthcare再到ChatGPT for Clinicians,OpenAI杀入医疗的路线图已经摊开了。
第一步,ChatGPT:让患者自助查健康问题;
第二步,ChatGPT for Clinicians:让个体医生免费用上专业工具;
第三步,ChatGPT for Healthcare:让医院和医疗系统大规模部署。
今年1月,波士顿儿童医院、Cedars-Sinai医学中心、斯坦福儿童健康、纪念斯隆凯特琳癌症中心,这些美国顶级医疗机构已经在跑ChatGPT for Healthcare。
Clinicians瞄准的是那些所在医院还没统一部署AI的个体医生。

https://openai.com/zh-Hans-CN/index/openai-for-healthcare/
OpenAI还透露,接下来将与Better Evidence Network合作,在当地法规允许的前提下向美国以外的临床医生试点开放。
72%的美国医生已经在用AI,使用量一年翻了一倍。而且,这个趋势不会逆转。
AI不会替代医生,但五年后的医生工作方式,肯定和今天一定不一样,比如可能是这样的:
每天两小时的文书工作变成十分钟;查文献从翻半天期刊变成一句prompt;写转诊信,从对着模板改半小时,变成审核AI的初稿……
OpenAI这次推出的ChatGPT for Healthcare,正是要从接管文书工作开始,逐渐成为每个医生工作台上的「第二大脑」。
至于这个赌注最终是改善了医疗还是引发了新问题,答案不在硅谷,而是在诊室里。
参考资料:
https://x.com/gdb/status/2047145125604995280%20
https://openai.com/index/making-chatgpt-better-for-clinicians/
https://www.ama-assn.org/system/files/physician-ai-sentiment-report.pdf%20
https://cdn.openai.com/pdf/keeping-patients-first.pdf%20