
机器之心发布
最近,在人工智能领域又发生了令人瞩目的事件。
4月20日,OpenAI 推出了名为 Chronicle 的工具,这使得 AI 能够直接「查看屏幕」并持续记忆上下文信息。
这意味着什么?它不仅让对话更加流畅,还改变了交互方式。无论是编写代码、编辑文档还是调整设计稿,无需再反复向 AI 说明细节,因为它能够自行获取和记住相关信息。
然而,目前要使用这项功能需要订阅 ChatGPT Pro 版本,每月费用为100美元。
不过,在短短的两天之后,一个新的项目出现。一个由年轻开发者组成的团队「Vida」开源了 OpenChronicle 项目。

- 开发者们在发布时直接阐明了自己的观点:OpenAI 的 Chronicle 指出了一种未来的方向,但 AI 记忆不应该被限制在付费墙后面。
因此,他们决定将其开源化。除了「查看屏幕和持续记忆」之外,该项目还具备三个更激进的功能:完全本地运行、与任意模型兼容以及可以由不同 AI 代理共享使用。
这些特点使得 OpenChronicle 并非只是一个功能替代品,而是首次为 AI 提供了一个可重复使用的「记忆层」。
自开源发布以来,该项目在海外社区引起了热烈讨论。短短时间内,在线帖子超过2000条,许多开发者开始接入、复制和二次开发这个项目。
在 GitHub 上,OpenChronicle 迅速形成了热门话题,仅用九小时就积累了两千多条评论。
社区中有人这样评价:「这不仅仅是一个开源项目,它正在将 AI 的形态从单一产品推向更通用的系统。」
那么,这个「记忆层」具体能做什么呢?开发团队列举了几个具体的使用案例。
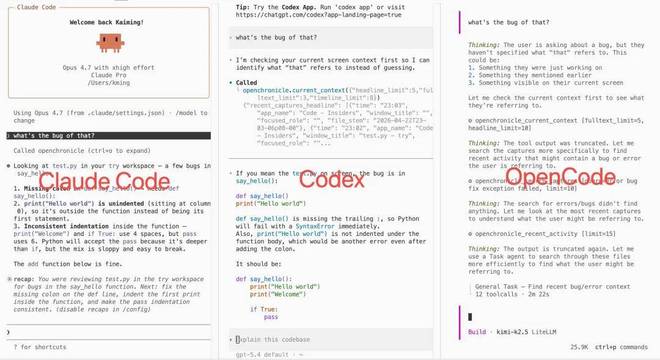
例如,在缺乏持续记忆的情况下,突然问一句“那里的错误是什么?”模型可能会感到困惑;但借助 OpenChronicle,AI 能直接调取当前屏幕的上下文信息(如 VS Code 打开的文件、报错内容),准确解析“那”所指的具体代码。
开发团队还进行了一项测试:在一个全新的对话中,让 Claude 创建一个关于 OpenChronicle 的 logo 描述。值得注意的是,他们从未向 Claude 提及过该项目名称。
在没有连续记忆的情况下,模型会询问“OpenChronicle 是什么?”;但一旦接入了 OpenChronicle,它可以从其他软件(如浏览器、飞书或 VS Code)中检索项目信息,并直接给出答案。无需额外解释和复制粘贴上下文,对话间的联系变得更为紧密。

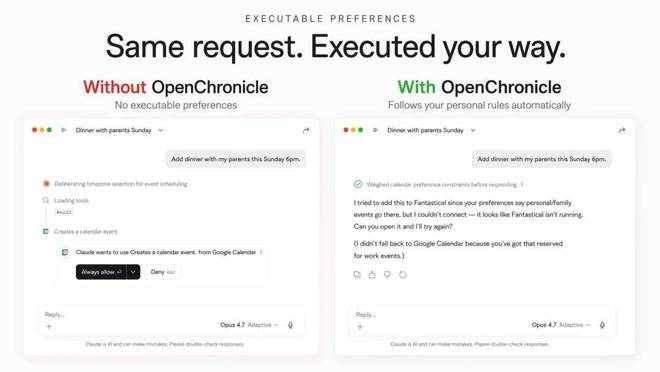
此外,开发团队指出:记忆不应仅仅帮助 AI 理解用户,还应让它能够按照用户的习惯执行任务。
2)跨会话连续性

例如,在发现某位用户使用 Google Calendar 处理工作事务而用 Apple/Fantastical 安排家庭活动时,当该用户说“这周日和父母吃晚饭”,AI 能自动将此安排添加到「家庭日历」而非工作日历。
一个能学习并适应用户习惯的未来似乎已经触手可及。
OpenChronicle 不仅关注对话记忆,更注重于工作流程中的持久记忆。
它观察和记录你在各种应用(如 IDE、Notion、Figma)上的操作过程,并记住每一个步骤。它追踪的是你实际在做什么,而不是仅仅通过聊天记录来理解上下文。
这种方式使得体验更加自然:当你使用飞书与团队讨论开发方案时,AI 可以直接延续你们的思路;同样地,在修改设计稿的过程中,AI 不只是关注当前版本,还了解之前版本的所有改动细节。
它开始理解整个过程,而不仅仅是某个瞬间的信息输入和输出。它更像是一个底层的基础架构。
这个项目没有绑定特定的模型或工具,Claude Code、Codex、OpenCode、Claude Desktop 等都可以轻松接入,并且 MCP 配置会自动生成。
开发者无需为每个代理单独构建记忆系统。不同工具之间也首次有机会共享统一的「用户上下文」信息。AI 记忆开始成为一种可以复用的基础能力。
更重要的是,OpenChronicle 并没有成为一个黑盒项目:
它使用 Markdown 存储记忆
通过 SQLite 进行检索
结构通过 AX Tree 显示出来
用户可以自由读取、修改和迁移这些数据。
让「AI 记忆」第一次看起来更像是一个数据库或操作系统组件,而不仅仅是一个独立的功能模块。
- 同时,该项目选择了本地优先的策略:使用本地模型总结记忆,并确保数据不会离开设备。此外,用户可以随时暂停和恢复记录功能。
- 看得更长远一点,这样的转变显得更加有趣。
- 过去,大多数 AI 的工作模式是简单的问答形式;但现在情况开始变化了。AI 会先观察环境、结合历史信息再参与当前任务,并留下持续的痕迹。
- 交互的方式从一次对话变为一个连续的过程。不再只是被动响应用户的请求,而是主动地参与到用户的工作中去。
Chronicle 和 OpenChronicle 提供了两种截然不同的路径:一种是将「记忆」作为产品功能纳入订阅体系;另一种则是将其剥离出来成为通用的基础设施层。
但真正的问题其实不在于是否开源。而是在于一个更现实的议题:当 AI 能够长期记录用户的操作、习惯和工作流程时,这些数据归属权到底属于谁?
更大的变化,还在后面
对此,OpenChronicle 的态度非常明确:将所有信息保留在本地设备上,并归用户个人所有。
这种做法导致了三个关键点的变化:
用户是否能控制自己的记忆
记忆能否在不同应用之间自由流动
记忆形式是黑箱能力还是可访问的数据层
如果说早期阶段解决了 AI 是否能够理解并回答用户的问题,那么未来的核心议题将是:AI 能否持续陪伴和参与用户的日常生活。而如今,这种分歧已经开始显现。
这让三件事情开始松动:
- 记忆的控制权,在平台还是在用户手里
- 记忆的边界,是被锁在应用里,还是可以流动
- 记忆的形态,是黑箱能力,还是数据层
如果说大模型阶段解决的是「AI 能不能理解并回答你」,那么下一阶段的核心命题将是:「AI 能否持续陪伴并参与你的世界」。而这一次,分歧已经出现。