
最近几天,全球顶尖的大规模语言模型陆续更新,新闻不断。
在国内,从本周一开始,Qwen、Kimi、小米和腾讯纷纷发布了新的模型版本。到了周五,备受期待的DeepSeek也终于推出了V4双版本,引发了中国AI社区的一场巨浪。
目前,中国已经加入万亿参数俱乐部并已开源的模型包括DeepSeek和Kimi两家公司,而小米则预告了其最新的万亿级模型即将开源。
阅读完近60页的技术报告后,我们发现这两个开源的大规模模型在技术上的默契程度比各自独立研发更令人印象深刻。
追溯到过去,DeepSeek和Kimi已经多次不谋而合地推出了类似的技术成果。这背后可能是梁文锋与杨植麟共同对扩展法则的信仰及对通用人工智能(AGI)追求的一致性所致。
两家公司之间的技术合作并非偶然事件
比如,DeepSeek-R1和Kimi K1.5仅相隔两小时发布;在NSA论文发表的同时,Kimi也发布了MoBA论文;Kimi的数学推理模型Kimina-Prover启发了DeepSeek-Prover V2等。
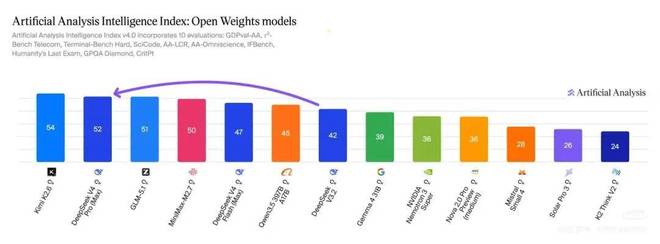
这两家公司并不是竞争对手,而是在一种近似于“开源共享”的模式下共同进步。
有句话说得好,“好的设计总是心有灵犀”。
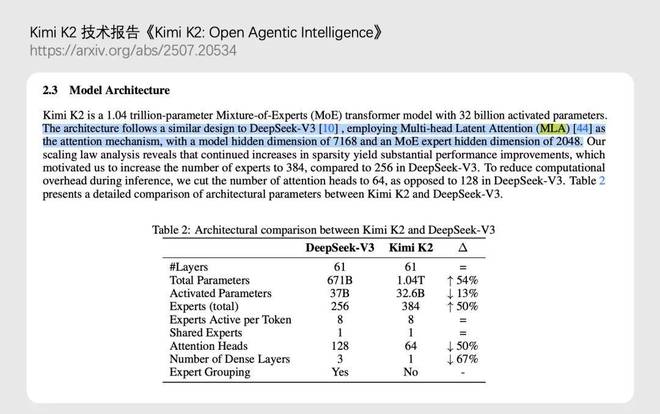
比如Kimi K2采用了DeepSeek的V3版本中的MLA注意力机制;而在DeepSeek V4中,则引入了由Kimi验证的大规模优化器Muon,这体现了技术上的互动成为行业亮点。
MLA机制:创新与复用
首先,DeepSeek在V3版本中率先提出了MLA注意力机制,通过低秩压缩技术有效减少了显存占用,从而让长上下文推理成为可能。这一设计很快就得到了业界的广泛认可,并被Kimi K2采纳。
优化器:大规模验证
另一个值得关注的技术突破是优化器的发展。早在2025年2月,Kimi就发布了《Muon is Scalable for LLM Training》论文,在拥有480亿参数的Moonlight系列模型上成功测试了Muon优化器,取代了传统的Adam技术。同年7月,在万亿级参数规模的Kimi K2中首次大规模应用了二阶优化器Muon。
近期,DeepSeek V4也采用Muon优化器技术,进一步提升了训练效率的稳定性。两家公司在底层技术和优化上相互借鉴,打破了原有的技术壁垒,展现了前所未有的深度合作精神。

残差连接:各自独特的解决方案
在残差连接领域,双方也有各自的突破。
DeepSeek在V4版本中引入了mHC残差连接方式,这使得信息传递更为高效。通过调整多头注意力的拼接策略,提高了梯度流动效率,实测证明训练速度提升了约30%。
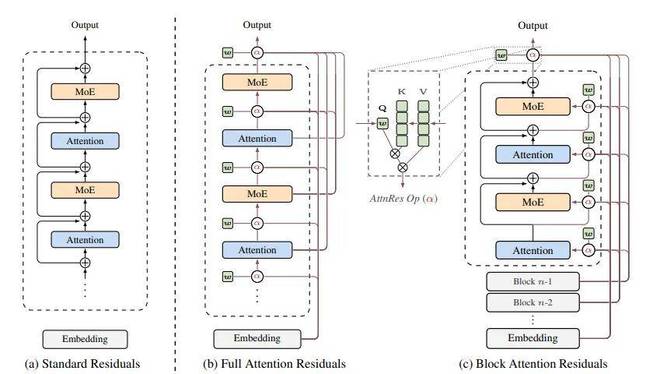
Kimi提出的Attention Residuals优化方案也得到了业界的认可,Andrej Karpathy评价说:“我们对《Attention is All You Need》的理解还不够”,OpenAI推理之父Jerry Tworek则认为“深度学习的2.0时代已经到来”。马斯克也在社交媒体上点赞称是“令人印象深刻的成果”。
这两种方案各有特点,体现了两家公司在同一技术难题上的不同思路。
长上下文推理:多种路径探索
在长上下文推理这一领域,Kimi和DeepSeek也有不同的策略。Kimi在2024年实现了百万Token级别的上下文能力,尽管效果显著但成本问题依然存在,超长上下文的计算开销呈线性增长,普通开发者难以承担。
到了2026年,两家公司分别提出了自己的解决方案:
- DeepSeek采用了稀疏注意力机制,仅关注输入中的关键部分,降低了计算量。这种方法虽然能够精准聚焦信息但设计和调优难度较大。
- Kimi则推出了线性注意力架构,改变了传统的计算方式,将复杂度从O(n²)降低到了O(n),理论上大幅减少了长上下文的计算成本。
两种方案各有利弊:稀疏注意力强调精度;而线性注意力追求效率。两者同时在两条技术路径上发力,为未来长上下文推理提供了多种可能的选择。
“从两个公司到一种基础设施”
DeepSeek与Kimi的“不期而遇”不仅仅是一场技术盛宴,更是中国AI产业格局的一次重大变革。
GPT-4和Claude 3.5 Opus虽未公开其参数规模,但中国的这两家创业公司已经开发出了同等规模且全部开源的模型。这意味着任何人都可以免费获取并进行二次开发或部署这些模型。
这一举措直接降低了企业私有化部署的成本至原来的十分之一,使得中小企业也能在自己的服务器上运行万亿级参数的大规模语言模型,这在过去是难以想象的事情。
生态系统也悄然形成,在OpenRouter平台上,两者的API调用量稳居中国前两名;在应用层面,Kimi被海外流行的编程工具所采用,而DeepSeek则被乐天集团包装为Rakuten AI 3.0。
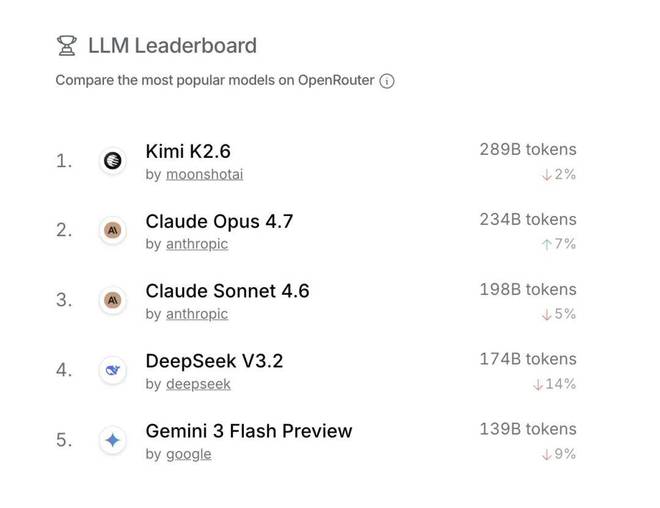
硅谷的科技巨头们也不得不正视这股来自东方的力量。
在Meta公司最新模型Muse Spark的技术博客中,直接将Llama 4与DeepSeek-V3.1及Kimi-K2进行了性能比较;
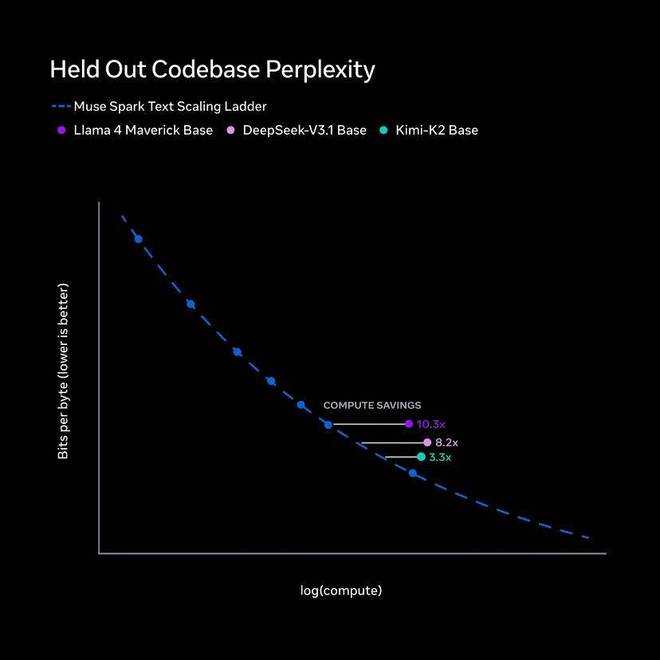
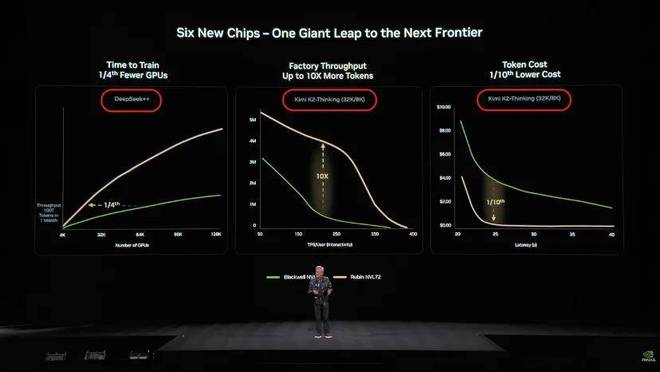
黄仁勋在CES主题演讲上更是将这两家公司的大模型作为下一代Blackwell和Rubin芯片强大性能展示的标杆。
同时两家公司都在国产芯片适配方面投入了大量精力。
DeepSeek V4首次深度适配华为昇腾芯片,推理环节将在国内硬件上运行;Kimi的Prefill-as-a-Service方案则提出了跨数据中心异构硬件推理框架,实测吞吐量提升54%,首令牌延迟降低64%。这为国产芯片进入大规模模型推理链条提供了现实路径。
黄仁勋在一次播客节目中提到:“阻挡不了中国芯片的进步”。他可能未曾想到,DeepSeek与Kimi正在用实际行动让这一天提前到来。
两位来自广东的创始人,杨植麟与梁文锋,在最短时间内双双叩开了百亿美金的大门。他们是技术的热情信徒也是被寄予厚望的中国AI国家队成员。
在总理主持召开的经济形势专家和企业家座谈会上,两人的建议成为了中国AI发展历程中的重要注脚。
深度的技术与广阔的视野是企业成功的关键。
2023年同期起步,以最少的人力资源实现了百亿市值的目标。两位来自广东的创始人既是技术范式的引领者:DeepSeek向世界展示了“思维链”的力量;Kimi在国内推动了智能体落地浪潮的发展。
在追求AGI的马拉松竞赛中,没有任何一家公司可以闭门造车完成全程。竞争与共鸣并存——Muon和MLA的技术互通、底层机制上的探索,正说明中国AI的力量来自于这种在“不期而遇”中的技术碰撞以及开源生态下的互利共生。
双峰并峙,最终将在顶峰相见。属于中国大规模语言模型的万亿级时代才刚刚开始。
双峰并峙,终将顶峰相见。属于中国大模型的万亿级航海时代,才刚刚拉开序幕。