
单张显卡跑出15倍推理速度,aiX-apply-4B小模型加速企业AI研发落地
单张显卡跑出15倍推理速度,aiX-apply-4B小模型加速企业AI研发落地 思邈 2026-03-30 08:41:45 量子位
AI3 阅读
共找到 6 篇相关文章
单张显卡跑出15倍推理速度,aiX-apply-4B小模型加速企业AI研发落地 思邈 2026-03-30 08:41:45 量子位

近日,谷歌发布了一种新的无损极限压缩算法TurboQuant,该算法专门针对大语言模型的键值缓存设计,旨在解决向量量化中的内存占用问题。谷歌声称,TurboQuant能够将大语言模型的键值缓存内存使用量至少减少至原来的六分之一,并且在推理速度上可以提升八倍,同时保持模型的精度不变。Matthew Prince,Cloudflare的创始人、首席执行官兼执行主席,将TurboQuant的发布视为谷歌

头图由AI生成近日,一家由北京大学背景的团队创立的人工智能编程初创公司——硅心科技,发布了其最新研发的轻量级模型aiX-apply-4B。这款模型仅需4B的参数量和256K的上下文支持,能够在消费级显卡上进行部署。该模型专为企业级代码修改任务设计,能够自动识别修改意图,精确定位目标代码区域,并保持原有代码格式和上下文结构的完整,将修改后的代码无缝融入原始文件。在基准测试中,aiX-apply模型在
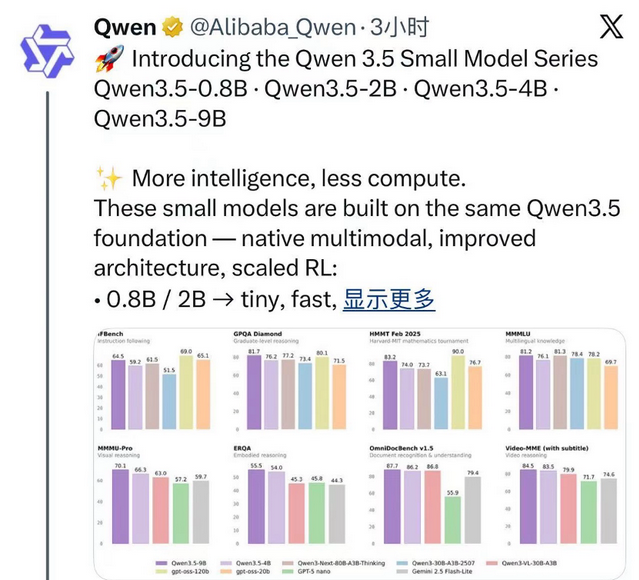
最近,阿里巴巴更新了其开源项目,发布了Qwen 3.5系列中的四款小型模型。这些新模型中最小的是0.8B和2B版本,它们体积小巧,推理速度非常快,非常适合在移动设备、物联网边缘计算环境中以及需要低延迟实时交互的应用场景中使用。另一款4B的模型则性能强劲,适合作为轻量级代理的核心大脑,能够在保证高性能的同时减少资源消耗。9B版本的这款模型,在智力需求较高但内存有限制的情况下表现优异,适用于服务器端部

新智元报道当硅谷公司Taalas将大模型「物理焊死」进芯片引发全球半导体行业的关注时,上海交通大学、辉羲智能及微软亚洲研究院的研究团队已更进一步——他们采用ROM+SRAM异构架构,使端侧LLM推理速度提升至20,000 tokens/s,极大地提升了端侧算力。最近,硅谷初创公司Taalas提出的「模型即芯片」方案引起了全球半导体界的深入讨论和反思。他们绕过了所有热门概念,直接将AI大模型物理焊接

2月13日,OpenAI于本周四发布了其智能体编程工具Codex的精简版本GPT-5.3-Codex-Spark,该新版本专注于极致推理速度。新版模型为了达到高效的推理性能,采用了Cerebras提供的专用芯片。此举标志着公司在硬件集成方面迈出了重要一步。上个月,OpenAI与Cerebras签署了一项为期多年的合作协议,价值超过100亿美元。“通过引入Cerebras的解决方案,我们旨在大幅提高