 近日,谷歌发布了一种新的无损极限压缩算法TurboQuant,该算法专门针对大语言模型的键值缓存设计,旨在解决向量量化中的内存占用问题。
近日,谷歌发布了一种新的无损极限压缩算法TurboQuant,该算法专门针对大语言模型的键值缓存设计,旨在解决向量量化中的内存占用问题。
谷歌声称,TurboQuant能够将大语言模型的键值缓存内存使用量至少减少至原来的六分之一,并且在推理速度上可以提升八倍,同时保持模型的精度不变。
Matthew Prince,Cloudflare的创始人、首席执行官兼执行主席,将TurboQuant的发布视为谷歌的一个重要里程碑,类似于DeepSeek时刻。

向量量化技术是企业压缩AI数据的主要手段,它通过减少高维向量的维度来节省内存,同时提高检索和推理的效率。然而,传统的压缩方法通常会导致额外的内存消耗,因为每一小块数据都需要单独的“压缩参数”,这反而可能影响压缩效果。
谷歌这次推出TurboQuant,利用了其此前提出的1位无偏误差校正算法QJL和极坐标量化压缩技术PolarQuant,实现了显著的压缩技术突破。
TurboQuant采用了一种创新的方法,通过随机旋转变换数据向量,简化了数据的几何结构。这种技术允许TurboQuant对向量的每个部分分别应用高质量的量化器,从而实现高效的压缩。
在TurboQuant的第一阶段,PolarQuant利用大部分的压缩算力来捕捉原始向量的核心语义和特征强度。这种技术不再依赖传统的标准坐标系,而是采用极坐标来描述向量,这大大减少了内存消耗。
PolarQuant将向量转换为极坐标,只保留半径和角度,其中半径代表核心数据强度,角度则代表数据的方向或语义。这种方法避免了复杂的归一化操作,显著节省了内存空间。
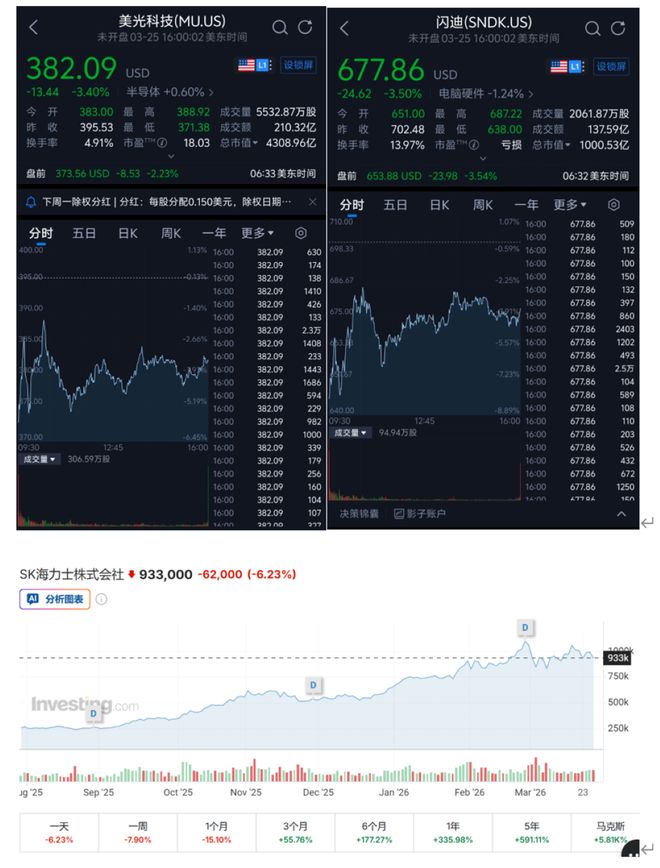
TurboQuant的第二阶段,利用QJL算法以极低的额外内存开销来修正第一阶段中产生的微小误差,从而实现完全无损的压缩效果。
博客链接:
QJL算法通过约翰逊–林登斯特劳斯变换,将复杂的数据简化为一种几乎不占用额外内存且计算速度快的格式,同时保持了数据点之间的基本距离和关联性。
TurboQuant在实验中展现了显著的优势,尤其是在不降低模型性能和精度的前提下,大幅提高了键值缓存的效率。
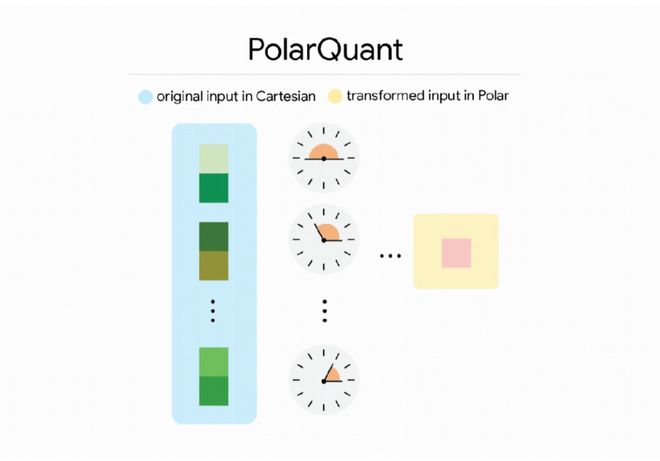
谷歌使用Meta开源的Llama-3.1-8B模型进行测试,结果显示,TurboQuant在键值缓存量化至3.5 bit时,模型精度没有损失,而PolarQuant也几乎实现了无损压缩。
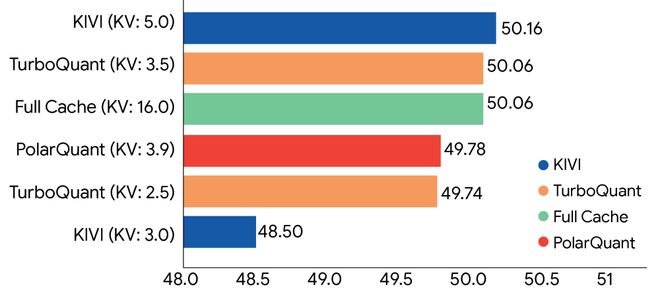
在不同的量化位宽下,TurboQuant表现出了卓越的加速比,尤其是在处理超长上下文时,TurboQuant 1 bit版本的加速比达到了13倍左右,而4 bit版本则为7倍左右。
TurboQuant在英伟达的H100 GPU上也展示了显著的加速效果,4 bit版本相比不压缩的32 bit原版键值缓存,速度提升了八倍,大幅优化了向量搜索、索引构建等关键场景的效率。
在高维向量搜索任务中,谷歌将TurboQuant与当前最优方法PQ和RabbiQ进行了对比,结果显示,无论是2 bit还是4 bit版本的TurboQuant,都取得了更优的召回率,证明了其在高维搜索任务中的稳健性和高效性。
通过对比不同主流量化方法,TurboQuant在GloVe数据集上也展现了稳健的检索性能,并实现了最优的1@k召回率。
总的来说,TurboQuant在PolarQuant主体压缩的基础上,通过极低比特量化和误差校正,大幅减少了键值缓存的存储空间,使模型能够在相同的硬件条件下处理更长的上下文和更大的批量数据,同时降低了推理成本。
此外,TurboQuant的推理速度极快,精度几乎达到无损效果,即使在处理超长文本时,其推理能力依然保持稳定高效。
TurboQuant的推出标志着大语言模型“瘦身”革命的进一步推进,它使得大规模向量索引的构建和查询变得更加迅速高效。
随着科技大厂不断通过算法创新提升AI大模型的推理效率,在当前存储芯片供应紧张的情况下,这种高效压缩技术的应用有助于缓解存储芯片产能无法跟上AI算力发展速度的问题。
二、拆解测试:TurboQuant强在哪?
谷歌称,在实验中,TurboQuant能在完全不降低AI模型效果、不损失精度的前提下,显著解决键值缓存给模型推理带来的性能瓶颈。
谷歌拿Meta开源的Llama-3.1-8B模型做测试,将TurboQuant、PolarQuant和KIVI算法相比较,可以看到,与官方基准线Full Cache相比,TurboQuant能够将键值缓存量化至仅3.5 bit,并且没有损失模型精度。同时,PolarQuant也几乎实现了无损压缩。
▲TurboQuant的缓存压缩性能图(横轴为性能得分,纵轴为量化方案)(图源:谷歌官网)
谷歌对3种不同量化位宽的TurboQuant进行测试,结果表明,在下图的所有序列长度(模型处理的文本token数量)中,TurboQuant 1 bit版本加速比最高,4 bit版本加速比最低。在1M超长上下文中,TurboQuant 1 bit版本加速比在13倍左右,4 bit版本在7倍左右。
同时,谷歌称TurboQuant在JAX框架(谷歌的超级加速框架)的基础上,仍能实现显著加速。在英伟达的H100 GPU上,TurboQuant 4 bit版本相比不压缩的32bit原版键值缓存,速度最高提升8倍,不仅能加速大模型推理,还能大幅优化向量搜索、索引构建等关键场景。
▲TurboQuant计算注意力logits的加速效果图(横轴为序列长度,纵轴为加速比)(图源:谷歌官网)
在高维向量搜索任务中,谷歌以1@k召回率(1@k召回率用于衡量算法在其前k个近似结果中,压缩后的向量和不压缩时算出“最相似结果”一样的概率。)为指标,将TurboQuant与当前最优方法PQ和RabbiQ进行了效果对比。
从下图可以看到,不管是2 bit还是4 bit版本的TurboQuant,都在召回率指标上持续取得了更优表现。这证实了TurboQuant在高维搜索任务中的稳健性与高效性。
同时,谷歌称,在GloVe数据集(维度d=200)(斯坦福大学发布的经典预训练词向量数据集)上,TurboQuant在与当前多种主流先进量化方法的对比中,展现出稳健的检索性能,并实现了最优的1@k召回率。
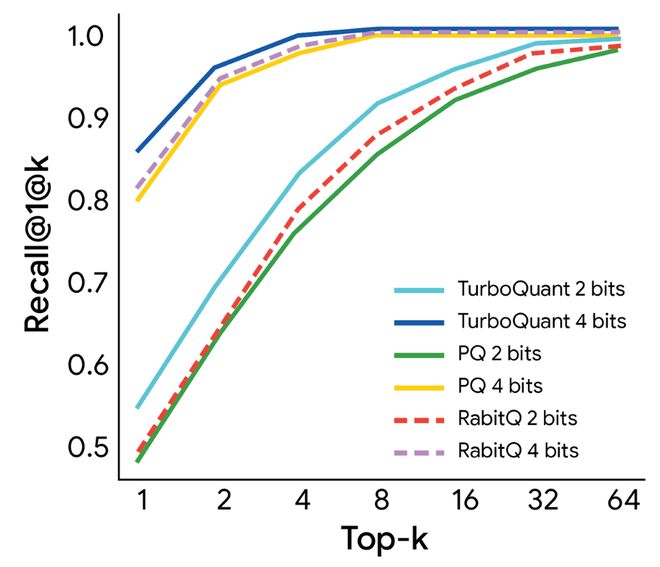
▲TurboQuant的召回率图(横轴是检索范围,纵轴是召回率)(图源:谷歌官网)
由此可见,TurboQuant在PolarQuant主体压缩的基础上,通过极低比特量化与误差校正,使键值缓存的存储空间显著减少,让模型能够在相同硬件条件下处理更长的上下文、更大的批量数据,同时降低推理成本。
此外,TurboQuant的推理速度极快,精度几乎达到无损效果,即使在超长文本下其推理能力依然稳定高效。
结语:算法博弈下的存储焦虑,企业推动大模型“瘦身”革命
TurboQuant在谷歌的测试中表现出了出色的出成绩,它能够以极低的内存占用、近乎为零的预处理耗时,完成大规模向量索引的构建与查询,这让“谷歌级别”的语义搜索变得更加快速高效。
早在2025年,英伟达于在arXiv上公开了第一版KVTC,证明它能把大模型的键值缓存压缩到原来的 1/20,同时精度损失不到1%。近期,英伟达更新了实测数据,称在H100 GPU上处理8000 Token的长提示时,模型生成第一个词的时间,从传统方案的3秒左右,缩短至380毫秒,速度提升8倍。
科技大厂正通过持续的算法创新与迭代,不断提升AI大模型的推理效率。在当前存储芯片供应紧张的背景下,企业通过对大模型推理过程中的键值缓存进行高效压缩,来提升大模型自身的推理效率,或许可以在一定程度上缓解存储芯片产能跟不上AI算力发展速度的局面。